1、ceph简介 ceph是一种开源的分布式的存储系统
包含以下几种存储类型:
块存储(rbd),对象存储(RADOS Fateway),文件系统(cephfs)
1 2 3 4 官方:start /intro/
1.1 块存储(rbd) 块是一个字节序列(例如,512字节的数据块)。 基于块的存储接口是使用旋转介质(如硬盘,CD,软盘甚至传统的9轨磁带)存储数据的最常用方法;Ceph块设备是精简配置,可调整大小并存储在Ceph集群中多个OSD条带化的数据。 Ceph块设备利用RADOS功能,如快照,复制和一致性。 Ceph的RADOS块设备(RBD)使用内核模块或librbd库与OSD进行交互;Ceph的块设备为内核模块或QVM等KVM以及依赖libvirt和QEMU与Ceph块设备集成的OpenStack和CloudStack等基于云的计算系统提供高性能和无限可扩展性。 可以使用同一个集群同时运行Ceph RADOS Gateway,CephFS文件系统和Ceph块设备。
linux系统中,ls /dev/下有很多块设备文件,这些文件就是我们添加硬盘时识别出来的;
rbd 就是由Ceph集群提供出来的块设备。可以这样理解,sda是通过数据线连接到了真实的硬盘,而rbd是通过网络连接到了Ceph集群中的一块存储区域,往rbd设备文件写入数据,最终会被存储到Ceph集群的这块区域中;
总结: 块设备可理解成一块硬盘,用户可以直接使用不含文件系统的块设备,也可以将其格式化成特定的文件系统,由文件系统来组织管理存储空间,从而为用户提供丰富而友好的数据操作支持。
1.2 文件系统(cephfs) Ceph文件系统(CephFS)是一个符合POSIX标准的文件系统,它使用Ceph存储集群来存储其数据。 Ceph文件系统使用与Ceph块设备相同的Ceph存储集群系统。
用户可以在块设备上创建xfs文件系统,也可以创建ext4等其他文件系统,Ceph集群实现了自己的文件系统来组织管理集群的存储空间,用户可以直接将Ceph集群的文件系统挂载到用户机上使用,Ceph有了块设备接口,在块设备上完全可以构建一个文件系统,那么Ceph为什么还需要文件系统接口呢?
主要是因为应用场景的不同,Ceph的块设备具有优异的读写性能,但不能多处挂载同时读写 ,目前主要用在OpenStack上作为虚拟磁盘,而Ceph的文件系统接口读写性能较块设备接口差,但具有优异的共享性。
1.3 对象存储 Ceph对象存储使用Ceph对象网关守护进程(radosgw),它是一个用于与Ceph存储集群交互的HTTP服务器。由于它提供与OpenStack Swift和Amazon S3兼容的接口,因此Ceph对象网关具有自己的用户管理。 Ceph对象网关可以将数据存储在用于存储来自Ceph文件系统客户端或Ceph块设备客户端的数据的相同Ceph存储集群中
使用方式就是通过http协议上传下载删除对象(文件即对象)。
老问题来了,有了块设备接口存储和文件系统接口存储,为什么还整个对象存储呢?
Ceph的块设备存储具有优异的存储性能但不具有共享性,而Ceph的文件系统具有共享性然而性能较块设备存储差,为什么不权衡一下存储性能和共享性,整个具有共享性而存储性能好于文件系统存储的存储呢,对象存储就这样出现了。
分布式存储的优点:
高可靠: 既满足存储读取不丢失,还要保证数据长期存储。 在保证部分硬件损坏后依然可以保证数据安全
高性能: 读写速度快
可扩展: 分布式存储的优势就是“分布式”,所谓的“分布式”就是能够将多个物理节点整合在一起形成共享的存储池,节点可以线性扩充,这样可以源源不断的通过扩充节点提升性能和扩大容量,这是传统存储阵列无法做到的
2、ceph核心组件 在ceph集群中,不管你是想要提供对象存储,块设备存储,还是文件系统存储,所有Ceph存储集群部署都是从设置每个Ceph节点,网络和Ceph存储开始 的。 Ceph存储集群至少需要一个Ceph Monitor,Ceph Manager和Ceph OSD(对象存储守护进程)。 运行Ceph Filesystem客户端时也需要Ceph元数据服务器。
Monitors: Ceph监视器(ceph-mon)维护集群状态的映射,包括监视器映射,管理器映射,OSD映射和CRUSH映射。这些映射是Ceph守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。冗余和高可用性通常至少需要三个监视器。
Managers: Ceph Manager守护程序(ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。 Ceph Manager守护进程还托管基于python的模块来管理和公开Ceph集群信息,包括基于Web的Ceph Dashboard和REST API。高可用性通常至少需要两名Managers。
Ceph OSD: Ceph OSD(对象存储守护进程,ceph-osd)存储数据,处理数据复制,恢复,重新平衡,并通过检查其他Ceph OSD守护进程来获取心跳,为Ceph监视器和管理器提供一些监视信息。冗余和高可用性通常至少需要3个Ceph OSD。
MDS: Ceph元数据服务器(MDS,ceph-mds)代表Ceph文件系统存储元数据(即,Ceph块设备和Ceph对象存储不使用MDS)。 Ceph元数据服务器允许POSIX文件系统用户执行基本命令(如ls,find等),而不会给Ceph存储集群带来巨大负担。
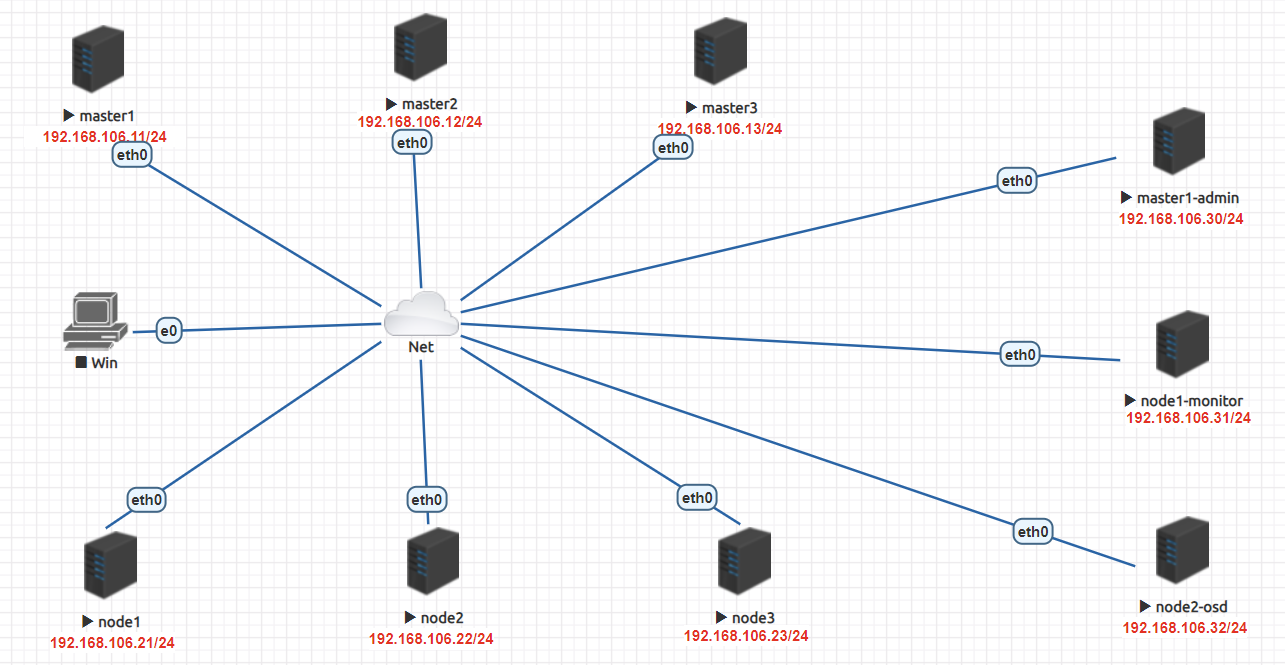
3、安装ceph集群 3.1 规划
3.2 初始化环境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 END 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.106.30 master1-admin 192.168.106.31 node1-monitor 192.168.106.32 node2-osd END disable firewalld --now's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config "s/^#ClientAliveInterval.*/ClientAliveInterval 600/" /etc/ssh/sshd_config "s/^#ClientAliveCountMax.*/ClientAliveCountMax 10/" /etc/ssh/sshd_config 's/^server.*//' /etc/chrony.conf's/# Please.*/server ntp.aliyun.com iburst/' /etc/chrony.conf enable chronyd --now
3.3 配置ceph安装源 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 yum install -y yum-utils && sudo yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && sudo yum install --nogpgcheck -y epel-release && sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && sudo rm /etc/yum.repos.d/dl.fedoraproject.org*END [Ceph] name=Ceph packages for \$basearch baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ enabled=1 gpgcheck=0 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc priority=1 [Ceph-noarch] name=Ceph noarch packages baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/ enabled=1 gpgcheck=0 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc priority=1 [ceph-source] name=Ceph source packages baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS/ enabled=1 gpgcheck=0 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc priority=1 END
3.4 安装ceph-deploy 在master1-admin节点安装ceph-deploy
在master1-admin、node1-monitor和node2-osd节点安装ceph
1 2 3 [root@master1-admin ~]
3.5 创建monitor节点 创建一个目录,用于保存 ceph-deploy 生成的配置文件信息的
1 2 3 4 5 6 7 8 9 [root@master1-admin ceph]
3.6 安装ceph-monitor 3.6.1 修改ceph.conf配置文件 mon clock drift allowed :监视器间允许的时钟漂移量默认值0.05
mon clock drift warn backoff :时钟偏移警告的退避指数。默认值5
ceph对每个mon之间的时间同步延时默认要求在0.05s之间,这个时间有的时候太短了。所以如果ceph集群如果出现clock问题就检查ntp时间同步或者适当放宽这个误差时间。
1 2 3 4 5 6 7 8 9 10 11 [root@master1-admin ceph]
3.6.2 配置初始monitor、收集所有的密钥 1 2 3 4 5 6 7 8 9 10 11 [root@master1-admin ~]
3.7 部署osd服务 3.7.1 准备osd 1 2 3 4 [root@master1-admin ~]
3.7.2 激活osd 1 2 3 4 [root@master1-admin ~]
3.7.3 查看状态 1 2 [root@master1-admin ~]
要使用Ceph文件系统,你的Ceph的存储集群里至少需要存在一个Ceph的元数据服务器(mds)。
3.8 创建ceph文件系统 3.8.1 创建mds 1 2 [root@master1-admin ~]
3.8.2 查看ceph当前文件系统 一个cephfs至少要求两个librados存储池,一个为data,一个为metadata。当配置这两个存储池时,注意:
为metadata pool设置较高级别的副本级别,因为metadata的损坏可能导致整个文件系统不用
建议,metadata pool使用低延时存储,比如SSD,因为metadata会直接影响客户端的响应速度。
1 2 [root@master1-admin ceph]
3.8.3 创建存储池 关于创建存储池
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
*少于 5 个 OSD 时可把 pg_num 设置为 128
*OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
*OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
*OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
*自己计算 pg_num 取值时可借助 pgcalc 工具
随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
1 2 3 4 5 [root@master1-admin ~]'cephfs_data' created'cephfs_metadata' created
3.8.4 创建文件系统 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1-admin ceph]in
3.9 测试k8s挂载ceph rbd 3.9.1 安装软件 kubernetes要想使用ceph,需要在k8s的每个node节点安装ceph-common,把ceph节点上的ceph.repo文件拷贝到k8s各个节点/etc/yum.repos.d/目录下,然后在k8s的各个节点yum install ceph-common -y
1 yum install ceph-common -y
3.9.2 将ceph的配置拷贝到k8s集群的各个节点 1 2 3 4 5 6 [root@master1-admin ~]
3.9.3 创建ceph rbd 1 2 3 4 5 6 7 8 9 10 [root@master1-admin ~]'k8srbd1' created
3.9.4 测试nginx镜像挂载ceph rbda块设备 当一个pod使用此rbda块设备时,其他容器想要挂载是不能成功挂载的,此方式生成块设备用的不多,但是需要了解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@master1 k8s-ceph]'192.168.106.30:6789' '192.168.106.31:6789' '192.168.106.32:6789' false
3.10 基于ceph rbd生成pv 3.10.1 获取client.admin的keyring值 创建ceph-secret这个k8s secret对象,这个secret对象用于k8s volume插件访问ceph集群,获取client.admin的keyring值,并用base64编码,在master1-admin(ceph管理节点)操作
1 2 [root@master1-admin ceph]
3.10.2 创建ceph的secret,在k8s的控制节点进行操作 1 2 3 4 5 6 7 8 9 10 11 [root@master1 k8s-ceph]
3.10.3 回到ceph管理节点创建pool池 1 2 3 4 5 6 [root@master1-admin ceph]'k8stest' created
3.10.4 到k8s控制节点创建pv 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 k8s-ceph]'192.168.106.30:6789' '192.168.106.31:6789' '192.168.106.32:6789' false
3.10.5 创建pvc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@master1 k8s-ceph]
3.10.6 测试挂载pvc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@master1 k8s-ceph]"/ceph-data"
总结: ceph rbd块存储能在同一个node上跨pod以ReadWriteOnce共享挂载
ceph rbd块存储能在同一个node上同一个pod多个容器中以ReadWriteOnce共享挂载
ceph rbd块存储不能跨node以ReadWriteOnce共享挂载
如果一个使用ceph rdb的pod所在的node挂掉,这个pod虽然会被调度到其它node,但是由于rbd不能跨node多次挂载和挂掉的pod不能自动解绑pv的问题,这个新pod不会正常运行
Deployment更新特性:
deployment触发更新的时候,它确保至少所需 Pods 75% 处于运行状态(最大不可用比例为 25%)。故像一个pod的情况,肯定是新创建一个新的pod,新pod运行正常之后,再关闭老的pod。
默认情况下,它可确保启动的 Pod 个数比期望个数最多多出 25%
问题:
结合ceph rbd共享挂载的特性和deployment更新的特性,我们发现原因如下:
由于deployment触发更新,为了保证服务的可用性,deployment要先创建一个pod并运行正常之后,再去删除老pod。而如果新创建的pod和老pod不在一个node,就会导致此故障。
解决办法:
1,使用能支持跨node和pod之间挂载的共享存储,例如cephfs,GlusterFS等
2,给node添加label,只允许deployment所管理的pod调度到一个固定的node上。(不建议,这个node挂掉的话,服务就故障了)
3.11 基于storageclass动态生成pv 3.11.1 设置/etc/ceph/目录的权限 1 2 3 4 5 6 7 8 9 [root@master1-admin ~]
3.11.2 创建/root/.ceph/目录 1 2 3 4 5 6 7 8 9 [root@master1-admin ~]
3.11.3 创建rbd-provisioner相关配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 [root@master1 k8s-ceph]"" ]"persistentvolumes" ]"get" , "list" , "watch" , "create" , "delete" ]"" ]"persistentvolumeclaims" ]"get" , "list" , "watch" , "update" ]"storage.k8s.io" ]"storageclasses" ]"get" , "list" , "watch" ]"" ]"events" ]"create" , "update" , "patch" ]"" ]"services" ]"kube-dns" ,"coredns" ]"list" , "get" ]"" ]"secrets" ]"get" ]"" ]"endpoints" ]"get" , "list" , "watch" , "create" , "update" , "patch" ]type : Recreate
3.11.4 创建ceph-secret 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 'k8stest1' createdtype : "ceph.com/rbd"
3.11.5 创建storageclass 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master1 k8s-ceph]"2" "layering"
3.11.6 创建pvc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 k8s-ceph]
3.11.7 测试挂载pvc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 [root@master1 k8s-ceph]test : rbd-podfalse in the same namespace)false false
3.12 k8s挂载cephfs 3.12.1 创建ceph子目录 为了别的地方能挂载cephfs,先创建一个secretfile
挂载cephfs的根目录到集群的mon节点下的一个目录,比如ceph_data,因为挂载后,我们就可以直接在ceph_data下面用Linux命令创建子目录了。
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master1-admin ~]
在cephfs的根目录里面创建了一个子目录lucky,k8s以后就可以挂载这个目录
1 2 3 [root@master1-admin ~]
3.12.2 创建k8s连接ceph使用的secret 将/etc/ceph/ceph.client.admin.keyring里面的key的值转换为base64,否则会有问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1-admin ~]
3.12.3 创建cephfs的pv 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@master1 k8s-ceph]false
3.12.4 创建cephfs的pvc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master1 k8s-ceph]
3.12.5 创建pod,测试挂载cephfs-pvc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@master1 k8s-ceph]