1、Docker 0基础入门到企业实战 1.1 docker概述与基本原理介绍 Docker官网:https://docs.docker.com/ https://github.com/moby/moby
Dockerhub官网https://registry.hub.docker.com
如果docker官方registry拉取镜像速度很慢,可以尝试daocloud提供的加速器服务https://dashboard.daocloud.io/mirror
1.1.1 docker 是什么 Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。它基于 Google 公司推出的 Go 语言实现。项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,项目代码在GitHub 上进行维护。
Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的、可移植的、自给自足的容器。开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何支持docker的机器上运行。容器是完全使用沙箱机制,相互之间不会有任何接口调用。
Docker logo:
Docker的思想来自于集装箱,集装箱解决了什么问题?在一艘大船上,可以把货物规整的摆放起来。并且各种各样的货物被装在集装箱里,集装箱和集装箱之间不会互相影响。那么我就不需要专门运送蔬菜的船和专门运送货物的船了。只要这些货物在集装箱里封装的好好的,那我就可以用一艘大船把他们都运走。
1.1.2 docker的优点 1)快
docker-ce:社区版
1.1.3 docker的缺点 所有容器共用linux kernel资源,资源能否实现最大限度利用,所以在安全上也会存在漏洞。
1.2 生产环境docker集群安装和配置 1.2.1 关闭防火墙 1 systemctl disable firewalld --now
1.2.2 关闭selinux 1 2 setenforce 0's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
1.2.3 配置时间同步 1 2 3 4 yum install chrony -y 's/^server.*//g' /etc/chrony.conf echo 'server ntp.aliyun.com iburst' >> /etc/chrony.confenable chronyd --now
1.2.4 安装基础软件包 1 yum install -y wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack
1.2.5 安装docker-ce 1 2 3 4 yum install -y yum-utils device-mapper-persistent-data lvm2enable docker --now
1.3 Docker 机器内核参数调优 1.3.1 开启包转发功能和修改内核参数 内核参数修改:br_netfilter模块用户将桥接流量转发至iptables链,br_netfilter内核参数需要开启转发
1 2 3 4 5 6 7 8 9 modprobe br_netfilterEND net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 END
1.3.2 设置开机自动加载脚本 1 2 3 4 5 6 7 8 9 10 cat > /etc/rc.sysinit <<END #!/bin/bash for file in /etc/sysconfig/modules/*.modules ; do [ -x $file ] && $file done END echo "modprobe br_netfilter" > /etc/sysconfig/modules/br_netfilter.modules
1.3.3 WARNING: bridge-nf-call-iptables is disabled 的解决办法 将Linux系统作为路由或者VPN服务就必须要开启IP转发功能。当linux主机有多个网卡时一个网卡收到的信息是否能够传递给其他的网卡 ,如果设置成1 的话 可以进行数据包转发,可以实现VxLAN 等功能。不开启会导致docker部署应用无法访问。
1 2 3 4 5 6 net.bridge.bridge-nf-call-ip6tables = 1
1.4 Docker阿里云镜像加速器配置 1.4.1 访问阿里云镜像仓库网址 1 https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
1.4.2 在主机上配置阿里云镜像加速服务 1 2 3 4 5 6 7 8 9 10 11 12 13 sudo mkdir -p /etc/docker 'EOF' "data-root" :"/data/docker" ,"registry-mirrors" : ["https://oym4jkot.mirror.aliyuncs.com" ],"insecure-registries" :["registry.access.redhat.com" ,"quay.io" ],"bip" :"172.108.18.1/24" ,"live-restore" :true
1.5 Docker的基本用法 1.5.1 镜像相关操作 1、从dockerhub上查找镜像 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@docker-master ~]for Kasm Workspaces 21 for Kasm Workspaces 3 for a slim Centos-based Python3 ima... 0 [OK]
解释说明:
NAME: 镜像仓库源的名称
DESCRIPTION: 镜像的描述
OFFICIAL: 是否 docker 官方发布
stars: 类似 Github 里面的 star,表示点赞、喜欢的意思。
AUTOMATED: 自动构建。
2、下载镜像 1 2 3 4 5 6 7 [root@docker-master ~]for docker.io/centos:latest
3、查看本地镜像 1 2 3 [root@docker-master ~]
4、镜像的导出与导入 1 2 3 4 5 6 7 8 9 10
1.6 容器相关操作 1.6.1 以交互式方式启动并进入容器 1 2 [root@docker-master ~]
输入exit,退出容器,退出之后容器也会停止,不会再前台运行
docker run 运行并创建容器
–name 容器的名字
-i 交互式
-t 分配伪终端
centos: 启动docker需要的镜像
/bin/bash 说明你的shell类型为bash,bash shell是最常用的一种shell, 是大多数Linux发行版默认的shell。 此外还有C shell等其它shell。
1.6.1 以守护进程的方式启动容器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 "/bin/bash" 14 seconds ago Up 13 seconds hello
1.6.2 通过docker部署nginx 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@docker-master ~]"/docker-entrypoint.…" 4 seconds ago Up 3 seconds 0.0.0.0:8080->80/tcp, :::8080->80/tcp nginx
1.6.3 容器的导出与导入 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@docker-master ~]"/bin/bash" 42 seconds ago Up 40 seconds 0.0.0.0:8080->80/tcp, :::8080->80/tcp centos-test
1.7 基于Dockerfile构建企业级生产环境镜像 1.7.1 Dockerfile构建镜像流程分析 Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。
基于Dockerfile构建镜像可以使用docker build命令。docker build命令中使用-f可以指定具体的dockerfile文件
dockerfile 构建过程:
从基础镜像运行一个容器
执行一条指令,对容器做出修改
执行类似docker commit 的操作,提交一个新的镜像层
再基于刚提交的镜像运行一个新的容器
执行dockerfile中的下一条指令,直至所有指令执行完毕
1 2 3 4 5 6 7 8 9 FROM centos "/usr/sbin/nginx" ,"-g" ,"daemon off;" ]
1.7.2 Dockerfile文件基本语法 (1) FROM 基础镜像,必须是可以下载下来的, 定制的镜像都是基于 FROM 的镜像,这里的 centos就是定制需要的基础镜像。后续的操作都是基于centos镜像。
(2) MAINTAINER 指定镜像的作者信息
(3) RUN :指定在当前镜像构建过程中要运行的命令 包含两种模式
1 、Shell
RUN (shell 模式,这个是最常用的,需要记住)
RUN echo hello
2 、exec模式
RUN ** **“executable”,“param1”,“param2”
RUN [ “/bin/bash”,”-c”,”echo hello”]
等价于/bin/bash -c echo hello
(4) EXPOSE 指令 仅仅只是声明端口。
作用:
1 、帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射。
2 、在运行时使用随机端口映射时,也就是 docker run -P 时,会自动随机映射 EXPOSE 的端口。
3 、可以是一个或者多个端口,也可以指定多个EXPOSE
格式:EXPOSE <端口1> [<端口2>…]
(5) CMD 类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:
1 、CMD 在docker run 时运行。
2 、RUN 是在 docker build构建镜像时运行的
作用 :为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 CMD[“executable”,“param1”,“param2”](exec 模式)command (shell模式)echo -e "[AppStream]\nname=AppStream\nbaseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/8-stream/AppStream/x86_64/os/\ngpgcheck=0\nenable=1\n[BaseOS]\nname=BaseOS\nbaseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/8-stream/BaseOS/x86_64/os/\ngpgcheck=0\nenable=1\n[epel]\nname=epel\nbaseurl=https://mirrors.tuna.tsinghua.edu.cn/epel/8/Everything/x86_64/\ngpgcheck=0\nenable=1\n" > /etc/yum.repos.d/a.repo "/usr/sbin/nginx" ,"-g" ,"daemon off;" ]"/usr/sbin/nginx -g …" 2 minutes ago Up 2 minutes 0.0.0.0:49153->80/tcp, :::49153->80/tcp dockerfile-test
(6) ENTERYPOINT 类似于 CMD 指令,但其不会被 docker run 的命令行参数指定的指令所覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。
但是, 如果运行 docker run 时使用了 –entrypoint 选项,将覆盖 entrypoint指令指定的程序。
优点:在执行 docker run 的时候可以指定 ENTRYPOINT 运行所需的参数。
注意:如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ENTERYPOINT [“executable”,“param1”,“param2”](exec 模式)command (shell模式)test 镜像:"nginx" , "-c" ] "/etc/nginx/nginx.conf" ] test test -c /etc/nginx/new.conf
(7) COPY COPY..
COPY[“”… “”]
复制指令,从上下文目录中复制文件或者目录到容器里指定路径。
1 2 3 4 5 6 7 8 9 10 11 12 格式:"<源路径1>" ,... "<目标路径>" ]
(8) ADD ADD …
ADD [“”… “”]
ADD 指令和 COPY 的使用格式一致(同样需求下,官方推荐使用 COPY)。功能也类似,不同之处如下:
ADD 的优点:在执行 <源文件> 为 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,会自动复制并解压到 <目标路径>。
ADD 的缺点:在不解压的前提下,无法复制 tar 压缩文件。会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。具体是否使用,可以根据是否需要自动解压来决定。
ADD vs COPY
ADD 包含类似tar的解压功能
如果单纯复制文件,dockerfile推荐使用COPY
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 替换/usr/share/nginx下的index.htmlecho -e "[AppStream]\nname=AppStream\nbaseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/8-stream/AppStream/x86_64/os/\ngpgcheck=0\nenable=1\n[BaseOS]\nname=BaseOS\nbaseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/8-stream/BaseOS/x86_64/os/\ngpgcheck=0\nenable=1\n[epel]\nname=epel\nbaseurl=https://mirrors.tuna.tsinghua.edu.cn/epel/8/Everything/x86_64/\ngpgcheck=0\nenable=1\n" > /etc/yum.repos.d/a.repo "/usr/sbin/nginx" ,"-g" ,"daemon off;" ]test
(9) VOLUME 定义匿名数据卷。在启动容器时忘记挂载数据卷,会自动挂载到匿名卷。
作用:
1 、避免重要的数据,因容器重启而丢失,这是非常致命的。
2 、避免容器不断变大。
1 2 3 4 5 6 格式:"<路径1>" , "<路径2>" ...]
(10)WORKDIR 指定工作目录。用 WORKDIR 指定的工作目录,会在构建镜像的每一层中都存在。(WORKDIR 指定的工作目录,必须是提前创建好的)。
docker build 构建镜像过程中的,每一个 RUN 命令都是新建的一层。只有通过 WORKDIR 创建的目录才会一直存在。
格式:
WORKDIR <** **工作目录路径>
WORKDIR /path/to/workdir
(填写绝对路径)
(11) ENV 设置环境变量
ENV
ENV =…
以下示例设置 NODE_VERSION =6.6.6, 在后续的指令中可以通过 $NODE_VERSION 引用:
ENV NODE_VERSION 6.6.6
1 2 RUN curl -SLO "https://nodejs.org/dist/v$NODE_VERSION /node-v$NODE_VERSION -linux-x64.tar.xz" \"https://nodejs.org/dist/v$NODE_VERSION /SHASUMS256.txt.asc"
(12) USER 用于指定执行后续命令的用户和用户组,这边只是切换后续命令执行的用户(用户和用户组必须提前已经存在)。
格式:
USER <** **用户名>[:<用户组>]
1 2 3 4 5 6 7 8 USER daemon
(13) ONBUILD 用于延迟构建命令的执行。简单的说,就是 Dockerfile 里用 ONBUILD 指定的命令,在本次构建镜像的过程中不会执行(假设镜像为 test-build)。当有新的 Dockerfile 使用了之前构建的镜像 FROM test-build ,这时执行新镜像的 Dockerfile 构建时候,会执行 test-build 的 Dockerfile 里的 ONBUILD 指定的命令。
格式:
ONBUILD <** **其它指令>
为镜像添加触发器
当一个镜像被其他镜像作为基础镜像时需要写上OBNBUILD
会在构建时插入触发器指令
(14) LABEL LABEL 指令用来给镜像添加一些元数据(metadata),以键值对的形式,语法格式如下:
LABEL = = = …
比如我们可以添加镜像的作者:
LABEL org.opencontainers.image.authors=”xianchao”
(15) HEALTHCHECK 用于指定某个程序或者指令来监控 docker 容器服务的运行状态。
格式:
HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令
HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
HEALTHCHECK [选项] CMD <命令> : 这边 CMD 后面跟随的命令使用,可以参考 CMD 的用法。
(16) ARG 构建参数,与 ENV 作用一至。不过作用域不一样。ARG 设置的环境变量仅对 Dockerfile 内有效,也就是说只有 docker build 的过程中有效,构建好的镜像内不存在此环境变量。
构建命令 docker build 中可以用 –build-arg <参数名>=<值> 来覆盖。
格式:
ARG <参数名>[=<默认值>]
1.7.3 Dockerfile构建nginx镜像 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 "/usr/sbin/nginx" ,"-g" ,"daemon off;" ]enable =1enable =1enable =1test test
注意: ENTRYPOINT [“/usr/sbin/nginx”,”-g”,”daemon off;”]
表示容器运行时,自动启动容器里的nginx服务
1.7.4 Dockerfile构建tomcat安装包 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 local local cd /usr/local && rpm -ivh jdk-8u45-linux-x64.rpmlocal /apache-tomcat-8.0.26 /usr/local /tomcat8local /tomcat8/bin/startup.sh && tail -F /usr/local /tomcat8/logs/catalina.out
1.8 Docker容器的数据卷管理 1.8.1 Docker容器的数据卷 什么是数据卷?
数据卷是经过特殊设计的目录,可以绕过联合文件系统(UFS),为一个或者多个容器提供访问,数据卷设计的目的,在于数据的永久存储,它完全独立于容器的生存周期,因此,docker不会在容器删除时删除其挂载的数据卷,也不会存在类似的垃圾收集机制,对容器引用的数据卷进行处理,同一个数据卷可以只支持多个容器的访问。
数据卷的特点:
1. 数据卷在容器启动时初始化,如果容器使用的镜像在挂载点包含了数据,这些数据会被拷贝到新初始化的数据卷中
2. 数据卷可以在容器之间共享和重用
3. 可以对数据卷里的内容直接进行修改
4. 数据卷的变化不会影像镜像的更新
5. 卷会一直存在,即使挂载数据卷的容器已经被删除
数据卷的使用:
1. 为容器添加数据卷
docker run -v /datavolume:/data -it centos /bin/bash
如:
docker run –name volume -v ~/datavolume:/data -itd centos /bin/bash
注:~/datavolume为宿主机目录,/data为docker启动的volume容器的里的目录
这样在宿主机的/datavolume目录下创建的数据就会同步到容器的/data目录下
(1)为数据卷添加访问权限
docker run –name volume1 -v ~/datavolume1:/data:ro -itd centos /bin/bash
添加只读权限之后在docker容器的/data目录下就不能在创建文件了,为只读权限;在宿主机下的/datavolume1下可以创建东西
1.8.2 Dockerfile volume 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 "/datavolume3" ,"/datavolume6" ]
1.8.3 docker数据卷的备份与还原 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 1、数据备份
1.9 Docker容器的网络基础 1.9.1 Docker的三种网络模式 docker run 创建Docker容器时,可以用–net选项指定容器的网络模式,Docker有以下4种网络模式:
bridge 模式:使–net =bridge指定,默认设置;
默认选择bridge的情况下,容器启动后会通过DHCP获取一个地址
1 2 3 4 5 6 7 8 9 10 11 12 [root@docker ~]
host 模式:使–net =host指定;
Docker网络host模式是指共享宿主机的网络
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@docker ~]
none 模式:使–net =none指定;
1 2 3 4 5 6 7 Docker网络none模式是指创建的容器没有网络地址,只有lo网卡
container 模式:使用–net =container:NAME orID指定。
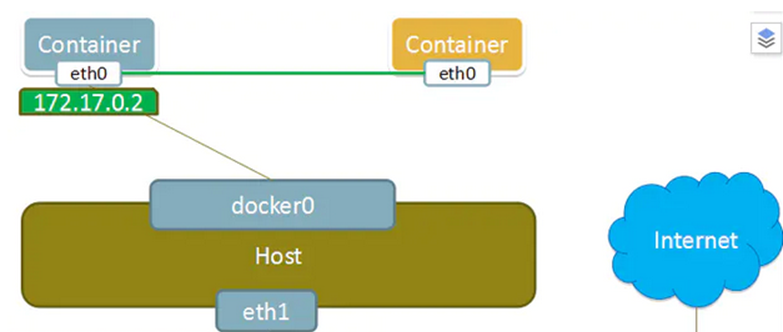
Docker网络container模式是指,创建新容器的时候,通过--net container参数,指定其和已经存在的某个容器共享一个 Network Namespace。如下图所示,右方黄色新创建的container,其网卡共享左边容器。因此就不会拥有自己独立的 IP,而是共享左边容器的 IP 172.17.0.2,端口范围等网络资源,两个容器的进程通过 lo 网卡设备通信。
1 2 3 4 5 6 7 [root@docker ~]
1.9.2docker 0 安装docker的时候,会生成一个docker0的虚拟网桥
每运行一个docker容器都会生成一个veth设备对,这个veth一个接口在容器里,一个接口在物理机上。
1.9.3 安装网桥管理工具 brctl show 可以查看到有一个docker0的网桥设备,下面有很多接口,每个接口都表示一个启动的docker容器
1 2 3 4 5 6 7 [root@docker ~]
1.10 实现容器间的互联 1.10.1 构建dockerfile镜像 1 2 3 4 5 6 7 8 [root@docker dockerfile]"/usr/sbin/nginx" ,"-g" ,"daemon off;" ]
1.10.2 构建容器 1 2 3 [root@docker dockerfile]
上述方法假如test1容器重启,那么在启动就会重新分配ip地址,所以为了使ip地址变了也可以访问可以采用下面的方法
1.10.3 docker link设置网络别名 可以给容器起一个代号,这样可以直接以代号访问,避免了容器重启ip变化带来的问题
1 2 3 4 5 6 7 8 9 10 11 [root@docker ~]
1.11 Docker资源配额及私有镜像仓库 1.11.1 限制docker容器的cpu、内存、磁盘io Docker通过cgroup来控制容器使用的资源限制,可以对docker限制的资源包括CPU、内存、磁盘
1.11.1.1 指定docker容器可以使用的cpu份额 1 2 3
CPU shares (relative weight) 在创建容器时指定容器所使用的CPU份额值。cpu-shares的值不能保证可以获得1个vcpu或者多少GHz的CPU资源,仅仅只是一个弹性的加权值。
默认每个docker容器的cpu份额值都是1024。在同一个CPU核心上,同时运行多个容器时,容器的cpu加权的效果才能体现出来。
例: 两个容器A、B的cpu份额分别为1000和500,结果会怎么样?
情况1:A和B正常运行,占用同一个CPU,在cpu进行时间片分配的时候,容器A比容器B多一倍的机会获得CPU的时间片。
情况2:分配的结果取决于当时其他容器的运行状态。比如容器A的进程一直是空闲的,那么容器B是可以获取比容器A更多的CPU时间片的; 比如主机上只运行了一个容器,即使它的cpu份额只有50,它也可以独占整个主机的cpu资源。
cgroups只在多个容器同时争抢同一个cpu资源时,cpu配额才会生效。因此,无法单纯根据某个容器的cpu份额来确定有多少cpu资源分配给它,资源分配结果取决于同时运行的其他容器的cpu分配和容器中进程运行情况。
例1:给容器实例分配512权重的cpu使用份额
1 2 3 [root@docker ~]
总结: 通过-c设置的 cpu share 并不是 CPU 资源的绝对数量,而是一个相对的权重值。某个容器最终能分配到的 CPU 资源取决于它的 cpu share 占所有容器 cpu share 总和的比例。通过 cpu share 可以设置容器使用 CPU 的优先级。
例2: 比如在 host 中启动了两个容器:
docker run –name “container_A” -c 1024 ubuntu
docker run –name “container_B” -c 512 ubuntu
container_A 的 cpu share 1024,是 container_B 的两倍。当两个容器都需要 CPU 资源时,container_A 可以得到的 CPU 是 container_B 的两倍。
需要注意的是,这种按权重分配 CPU只会发生在 CPU资源紧张的情况下。如果 container_A 处于空闲状态,为了充分利用 CPU资源,container_B 也可以分配到全部可用的 CPU。
1.11.1.2 cpu core核心设置 参数 :–cpuset可以绑定CPU
对多核CPU的服务器,docker还可以控制容器运行限定使用哪些cpu内核和内存节点,即使用–cpuset-cpus和–cpuset-mems参数。对具有NUMA拓扑(具有多CPU、多内存节点)的服务器尤其有用,可以对需要高性能计算的容器进行性能最优的配置。如果服务器只有一个内存节点,则–cpuset-mems的配置基本上不会有明显效果。
扩展 :
服务器架构一般分: SMP、NUMA、MPP体系结构介绍
从系统架构来看,目前的商用服务器大体可以分为三类:
\1. 即对称多处理器结构(SMP : Symmetric Multi-Processor) 例: x86 服务器,双路服务器。主板上有两个物理cpu
\2. 非一致存储访问结构 (NUMA : Non-Uniform Memory Access) 例: IBM 小型机 pSeries 690
\3. 海量并行处理结构 (MPP : Massive ParallelProcessing) 。 例: 大型机 Z14
1.11.1.3 cpu配额控制参数的混合使用 在上面这些参数中,cpu-shares控制只发生在容器竞争同一个cpu的时间片时有效。
如果通过cpuset-cpus指定容器A使用cpu 0,容器B只是用cpu1,在主机上只有这两个容器使用对应内核的情况,它们各自占用全部的内核资源,cpu-shares没有明显效果。
如何才能有效果?
容器A和容器B配置上cpuset-cpus值并都绑定到同一个cpu上,然后同时抢占cpu资源,就可以看出效果了。
例1:测试cpu-shares和cpuset-cpus混合使用运行效果,就需要一个压缩力测试工具stress来让容器实例把cpu跑满。
如何把cpu跑满?
如何把4核心的cpu中第一和第三核心跑满?可以运行stress,然后使用taskset绑定一下cpu。
stress命令
概述: linux系统压力测试软件Stress 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 [root@docker ~]' imposes certain types of compute stress on your system Usage: stress [OPTION [ARG]] ... -?, --help show this help statement --version show version statement -v, --verbose be verbose -q, --quiet be quiet -n, --dry-run show what would have been done -t, --timeout N timeout after N seconds --backoff N wait factor of N microseconds before work starts -c, --cpu N spawn N workers spinning on sqrt() -i, --io N spawn N workers spinning on sync() -m, --vm N spawn N workers spinning on malloc()/free() --vm-bytes B malloc B bytes per vm worker (default is 256MB) --vm-stride B touch a byte every B bytes (default is 4096) --vm-hang N sleep N secs before free (default none, 0 is inf) --vm-keep redirty memory instead of freeing and reallocating -d, --hdd N spawn N workers spinning on write()/unlink() --hdd-bytes B write B bytes per hdd worker (default is 1GB) -? 显示帮助信息 -v 显示版本号 -q 不显示运行信息 -n 显示已完成的指令情况 -t --timeout N 指定运行N秒后停止 --backoff N 等待N微妙后开始运行 -c 产生n个进程 :每个进程都反复不停的计算随机数的平方根,测试cpu -i 产生n个进程 :每个进程反复调用sync(),sync()用于将内存上的内容写到硬盘上,测试磁盘io -m --vm n 产生n个进程,每个进程不断调用内存分配malloc()和内存释放free()函数 ,测试内存 --vm-bytes B 指定malloc时内存的字节数 (默认256MB) --vm-hang N 指定在free栈的秒数 -d --hadd n 产生n个执行write和unlink函数的进程 -hadd-bytes B 指定写的字节数 --hadd-noclean 不unlink #注:时间单位可以为秒s,分m,小时h,天d,年y,文件大小单位可以为K,M,G
例1: 产生2个cpu进程,2个io进程,20秒后停止运行
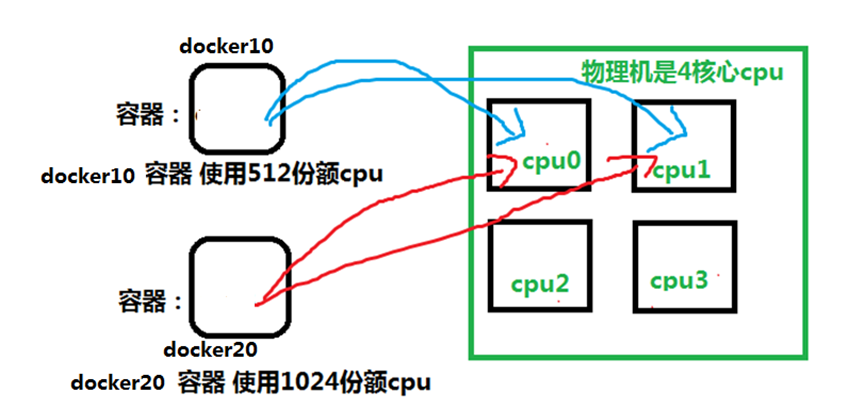
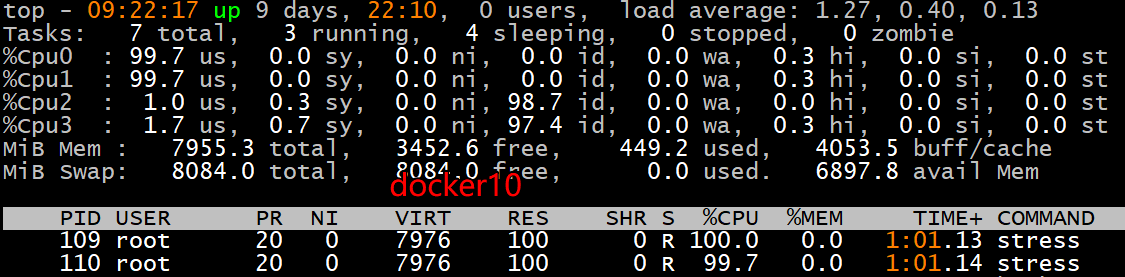
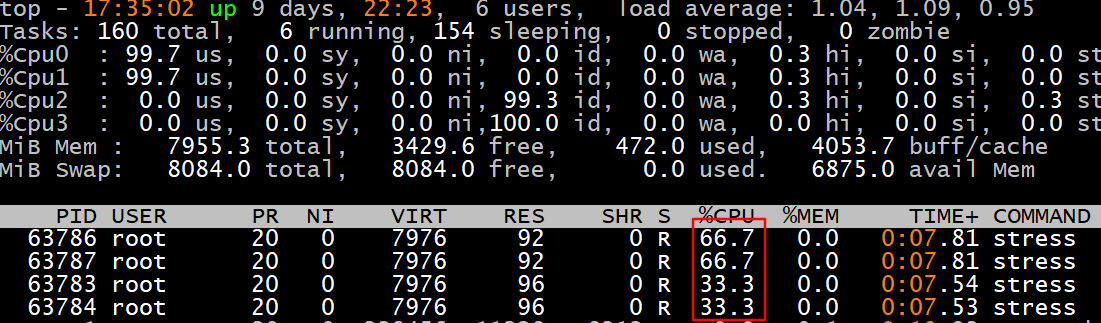
**例2:**创建两个容器实例:docker10 和docker20。 让docker10和docker20只运行在cpu0和cpu1上,最终测试一下docker10和docker20使用cpu的百分比。实验拓扑图如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@docker ~]
**注:**两个容器只在cpu0,1上运行,说明cpu绑定限制成功。而docker20是docker10使用cpu的2倍。说明–cpu-shares限制资源成功。
1.11.1.4 docker容器控制内存 Docker提供参数-m, –memory=””限制容器的内存使用量。
创建一个docker,只使用2个cpu核心,只能使用128M内存
1 2 3 4 [root@docker ~]
1.11.1.5 docker容器控制IO 1 2 3 4 5 6 7 8 read rate (bytes per second) from a
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 in
1.12 docker私有镜像仓库harbor Harbor介绍
Docker容器应用的开发和运行离不开可靠的镜像管理,虽然Docker官方也提供了公共的镜像仓库,但是从安全和效率等方面考虑,部署我们私有环境内的Registry也是非常必要的。Harbor是由VMware公司开源的企业级的Docker Registry管理项目,它包括权限管理(RBAC)、LDAP、日志审核、管理界面、自我注册、镜像复制和中文支持等功能。
官网地址:https://github.com/goharbor/harbor
1.12.1 为harbor自签发证书 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 [root@harbor ~]'.' , the field will be left blank.'s hostname) []: Email Address []: #生成一个3072位的key,也就是私钥 [root@harbor ssl]# openssl genrsa -out harbor.key 3072 Generating RSA private key, 3072 bit long modulus (2 primes) ......................................................................++++ ......................................................................................................................++++ e is 65537 (0x010001) #生成一个证书请求,一会签发证书时需要的 [root@harbor ssl]# openssl req -new -key harbor.key -out harbor.csr You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter ' .', the field will be left blank. ----- Country Name (2 letter code) [XX]:CN State or Province Name (full name) []:NJ Locality Name (eg, city) [Default City]:NJ Organization Name (eg, company) [Default Company Ltd]: Organizational Unit Name (eg, section) []: Common Name (eg, your name or your server' s hostname) []:harbor'extra' attributes
1.12.2 安装harbor 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
harbor的默认账号密码:admin/Harbor12345
1.12.3 安装docker-compose 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@harbor ~]
docker-compose项目是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。Docker-Compose的工程配置文件默认为docker-compose.yml,Docker-Compose运行目录下的必要有一个docker-compose.yml。docker-compose可以管理多个docker实例。
1 2 3
1.12.4 访问harbor web界面
1.12.5 配置docker主机访问harbor 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 "data-root" :"/data/docker" ,"registry-mirrors" : ["https://oym4jkot.mirror.aliyuncs.com" ],"insecure-registries" :["192.168.101.11" ,"harbor" ],"bip" :"172.101.10.1/24" ,"live-restore" :true
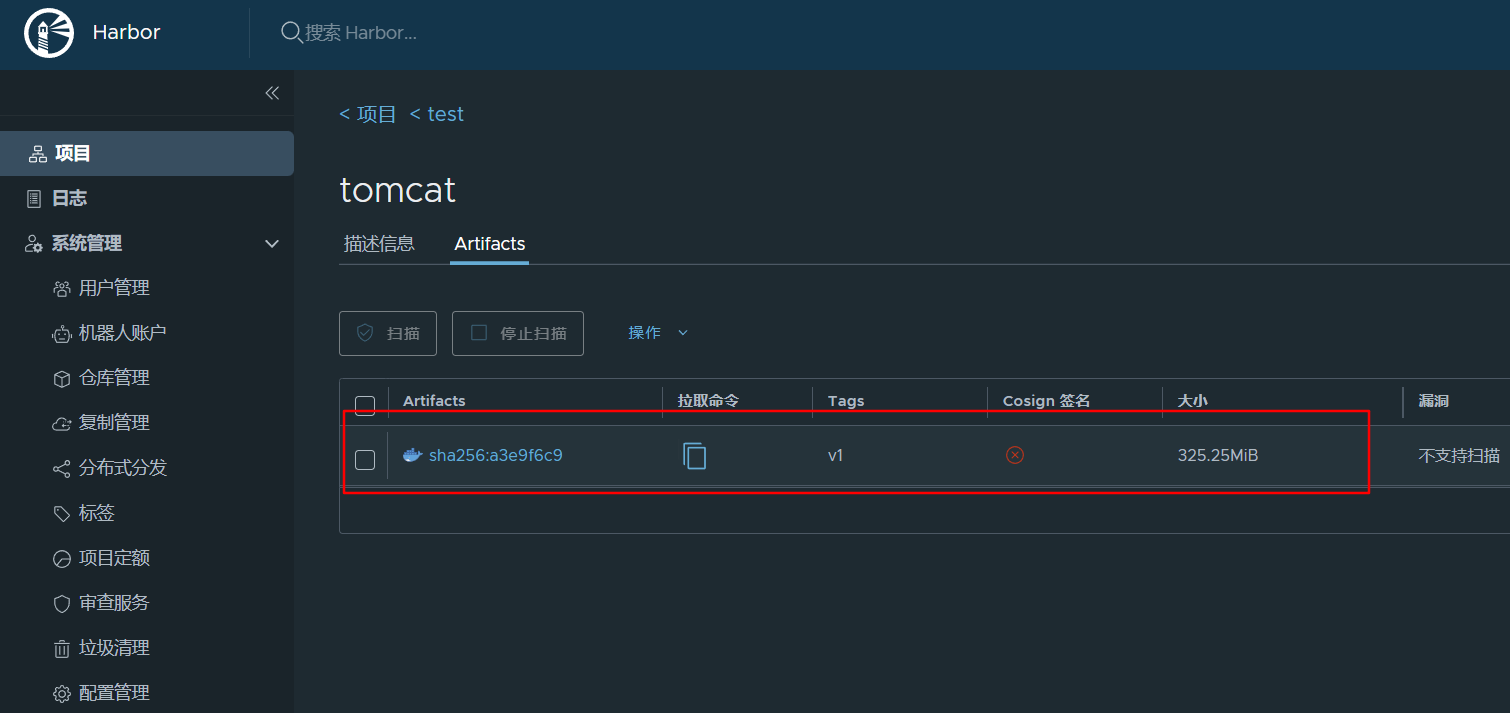
1.12.6 上传镜像到harbor的test项目中 1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@docker ~]test /tomcat]
1.12.7 从harbor上下载镜像 1 2 3 4 [root@docker ~]test /tomcat v1 921ef208ab56 11 months ago 668MB
2 、 kubeadm安装生产环境多master节点高可用集群 kubeadm和二进制安装k8s适用场景分析
kubeadm是官方提供的开源工具,是一个开源项目,用于快速搭建kubernetes集群,目前是比较方便和推荐使用的。kubeadm init 以及 kubeadm join 这两个命令可以快速创建 kubernetes 集群。Kubeadm初始化k8s,所有的组件都是以pod形式运行的,具备故障自恢复能力 。
kubeadm是工具,可以快速搭建集群,也就是相当于用程序脚本帮我们装好了集群,属于自动部署,简化部署操作,自动部署屏蔽了很多细节,使得对各个模块感知很少,如果对k8s架构组件理解不深的话,遇到问题比较难排查。
kubeadm: 适合需要经常部署k8s,或者对自动化要求比较高的场景下使用。
二进制: 在官网下载相关组件的二进制包,如果手动安装,对kubernetes理解也会更全面。
Kubeadm和二进制都适合生产环境,在生产环境运行都很稳定,具体如何选择,可以根据实际项目进行评估。
2.1 集群实验规划 **master1:**192.168.108.11
master2 :192.168.108.12
node1 :192.168.108.21
**node2:**192.168.108.22
2.2 初始化集群安装环境 2.2.1 配置主机hosts文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master1 ~]
2.2.2 配置主机间的免密登录 1 2 3 4 5
2.2.3关闭swap分区提升性能 为什么要关闭swap交换分区?
1 Swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装k8s的时候可以指定--ignore -preflight -errors =Swap来解决。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]
2.2.4 修改主机内核参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 [root@master1 ~]
2.2.5 关闭防火墙与selinux 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@master1 ~]
2.2.6 配置repo源 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 END [kubernetes] name=Kubernetes baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch enabled=1 gpgcheck=0 #repo_gpgcheck=0 #gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg #exclude=kubelet kubeadm kubectl END
2.2.7 配置时间同步 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master1 ~]
2.2.8 开启ipvs ipvs是什么?
ipvs (IP Virtual Server) 实现了传输层负载均衡,也就是我们常说的4层LAN交换,作为 Linux 内核的一部分。ipvs运行在主机上,在真实服务器集群前充当负载均衡器。ipvs可以将基于TCP和UDP的服务请求转发到真实服务器上,并使真实服务器的服务在单个 IP 地址上显示为虚拟服务。
ipvs和iptable对比分析
kube-proxy支持 iptables 和 ipvs 两种模式, 在kubernetes v1.8 中引入了 ipvs 模式,在 v1.9 中处于 beta 阶段,在 v1.11 中已经正式可用了。iptables 模式在 v1.1 中就添加支持了,从 v1.2 版本开始 iptables 就是 kube-proxy 默认的操作模式,ipvs 和 iptables 都是基于netfilter的,但是ipvs采用的是hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。那么 ipvs 模式和 iptables 模式之间有哪些差异呢?
1、ipvs 为大型集群提供了更好的可扩展性和性能
2、ipvs 支持比 iptables 更复杂的复制均衡算法(最小负载、最少连接、加权等等)
3、ipvs 支持服务器健康检查和连接重试 等功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@master1 ~]"ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack" for kernel_module in ${ipvs_modules} ; do ${kernel_module} > /dev/null 2>&1if [ 0 -eq 0 ]; then ${kernel_module} fi done
2.2.9 安装基础软件包 1 2 3 4 5 6 7 8 9 10 [root@master1 ~]
2.2.10 安装iptables(备用) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@master1 ~]
2.3 安装docker 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 [root@master1 ~]"data-root" :"/data/docker" ,"registry-mirrors" : ["https://oym4jkot.mirror.aliyuncs.com" ],"insecure-registries" :["registry.access.redhat.com" ,"quay.io" ],"bip" :"172.108.11.1/24" ,"live-restore" :true ,"exec-opts" : ["native.cgroupdriver=systemd" ]"data-root" :"/data/docker" ,"registry-mirrors" : ["https://oym4jkot.mirror.aliyuncs.com" ],"insecure-registries" :["registry.access.redhat.com" ,"quay.io" ],"bip" :"172.108.12.1/24" ,"live-restore" :true ,"exec-opts" : ["native.cgroupdriver=systemd" ]"data-root" :"/data/docker" ,"registry-mirrors" : ["https://oym4jkot.mirror.aliyuncs.com" ],"insecure-registries" :["registry.access.redhat.com" ,"quay.io" ],"bip" :"172.108.21.1/24" ,"live-restore" :true ,"exec-opts" : ["native.cgroupdriver=systemd" ]"data-root" :"/data/docker" ,"registry-mirrors" : ["https://oym4jkot.mirror.aliyuncs.com" ],"insecure-registries" :["registry.access.redhat.com" ,"quay.io" ],"bip" :"172.108.22.1/24" ,"live-restore" :true ,"exec-opts" : ["native.cgroupdriver=systemd" ]
2.4 安装初始化k8s需要的软件包 Kubeadm : 官方安装k8s的工具,kubeadm init,kubeadm join
**Kubelet:**启动、删除Pod需要用到的服务
**Kubectl:**操作k8s资源,创建资源、删除资源、修改资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]
2.5 通过keepalive-nginx实现k8s apiserver节点高可用 2.5.1 安装nginx主备 1 2 3 4 5 [root@master1 ~]
2.5.2 修改nginx配置文件,主备一致 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 [root@master1 ~]log /nginx/error.log;'$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent' ;log /nginx/k8s-access.log main;'$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"' ;log /nginx/access.log main;log /nginx/error.log;'$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent' ;log /nginx/k8s-access.log main;'$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"' ;log /nginx/access.log main;
2.5.3 配置keepalived 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 "/etc/keepalived/check_nginx.sh" "grep|$$" )if [ "$count " -eq 0 ];then fi "/etc/keepalived/check_nginx.sh" "grep|$$" )if [ "$count " -eq 0 ];then fi
2.6 kubeadm初始化k8s集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
2.7 扩容集群-添加master节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
2.8 扩容集群-添加node节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
注意: 上面状态都是NotReady状态,说明没有安装网络插件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~]
coredns为pending状态,这是因为还没有安装网络插件,等到下面安装好网络插件之后这个cordns就会变成running了
2.9 安装kubernetes网络组件-Calico 2.10 测试创建pod是否可以正常访问网络(加:修改apiserver参数) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~]'t see a command prompt, try pressing enter. / # / # ping www.baidu.com PING www.baidu.com (36.152.44.95): 56 data bytes 64 bytes from 36.152.44.95: seq=0 ttl=55 time=3.282 ms 64 bytes from 36.152.44.95: seq=1 ttl=55 time=3.275 ms /etc/kubernetes/manifests/kube-apiserver.yaml - --feature-gates=RemoveSelfLink=false systemctl restart kubelet
2.11 测试部署tomcat服务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 [root@master1 ~]type : NodePort
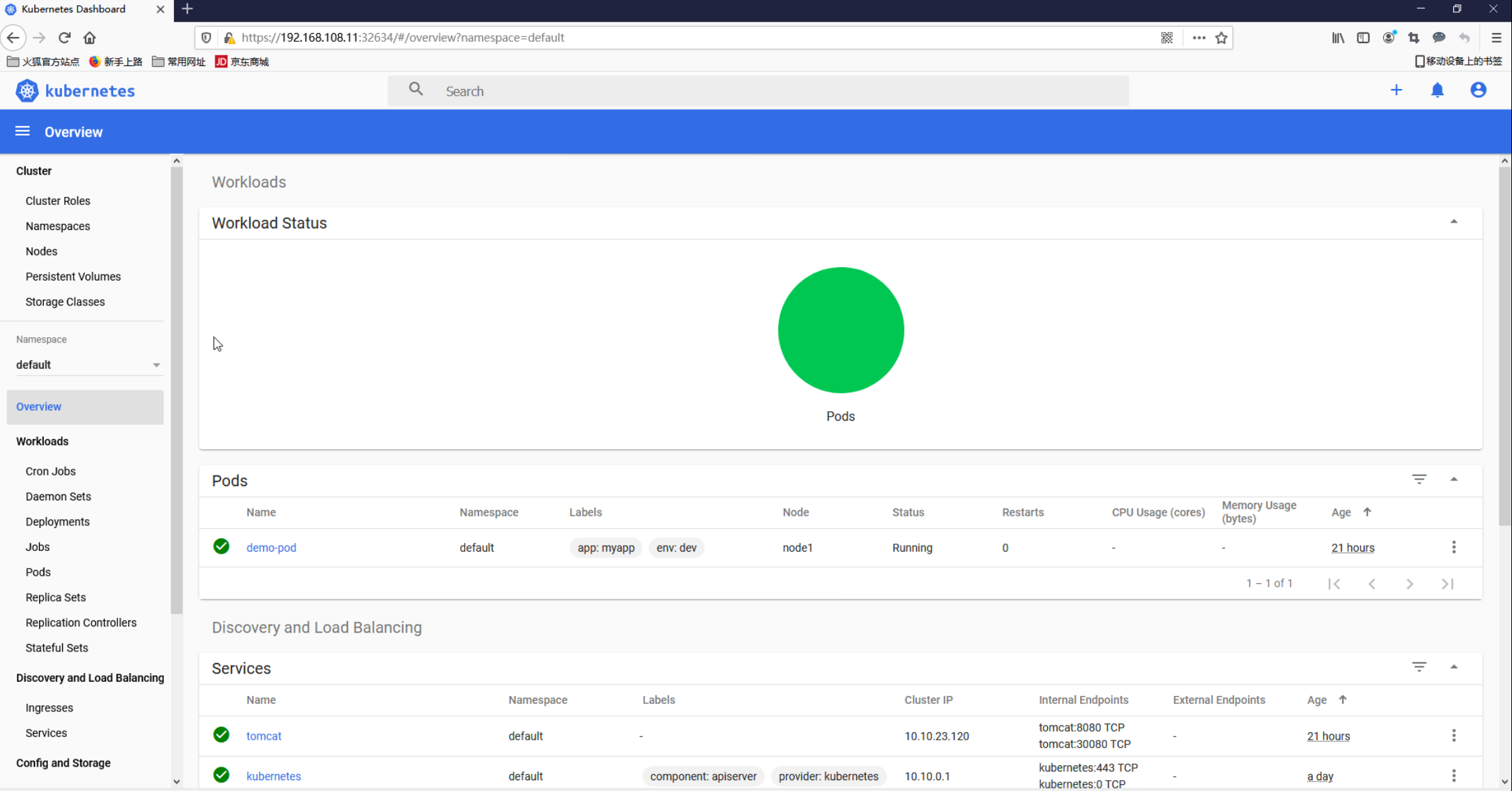
2.12 测试corednds是否正常 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~]'t see a command prompt, try pressing enter. / # nslookup kubernetes.default.svc.cluster.local Server: 10.10.0.10 Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.local Name: kubernetes.default.svc.cluster.local Address 1: 10.10.0.1 kubernetes.default.svc.cluster.local / # nslookup tomcat.default.svc.cluster.local Server: 10.10.0.10 Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.local Name: tomcat.default.svc.cluster.local Address 1: 10.10.23.120 tomcat.default.svc.cluster.local
2.13 安装可视化UI界面dashboard 2.13.1 安装dashboard 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@node1 ~]
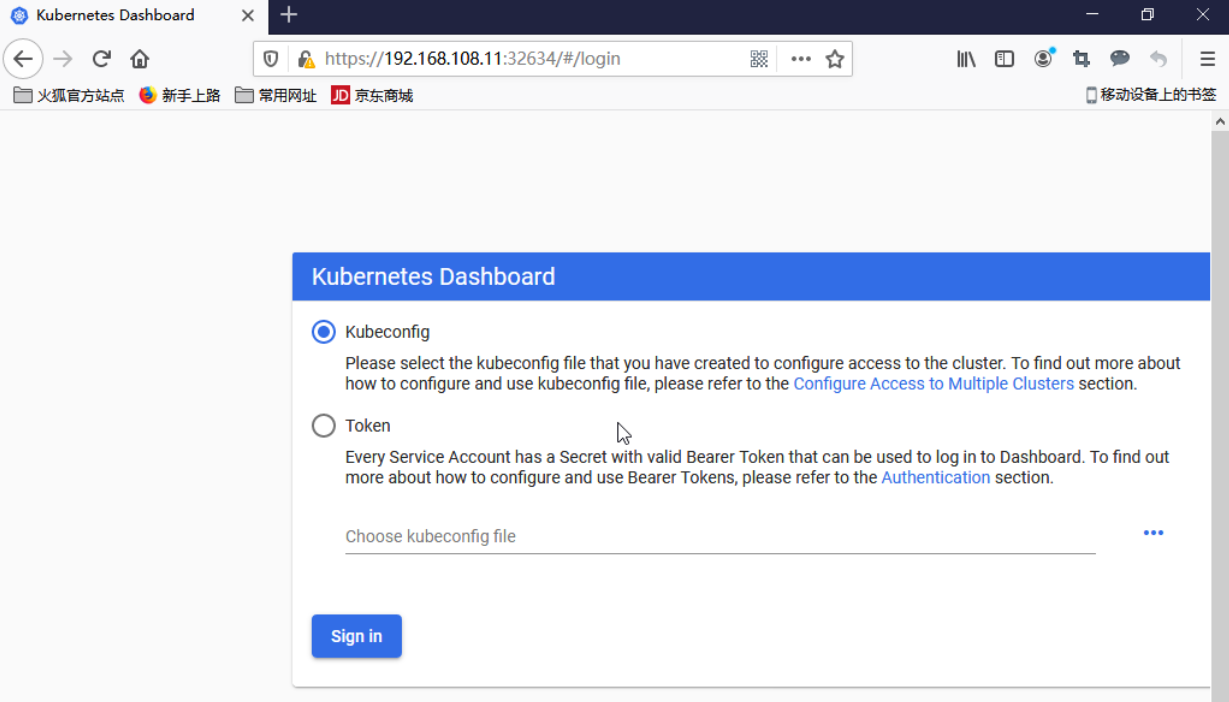
上面可看到service类型是NodePort,访问任何一个工作节点ip: 32728端口即可访问kubernetes dashboard,在浏览器(使用火狐浏览器)访问如下地址:
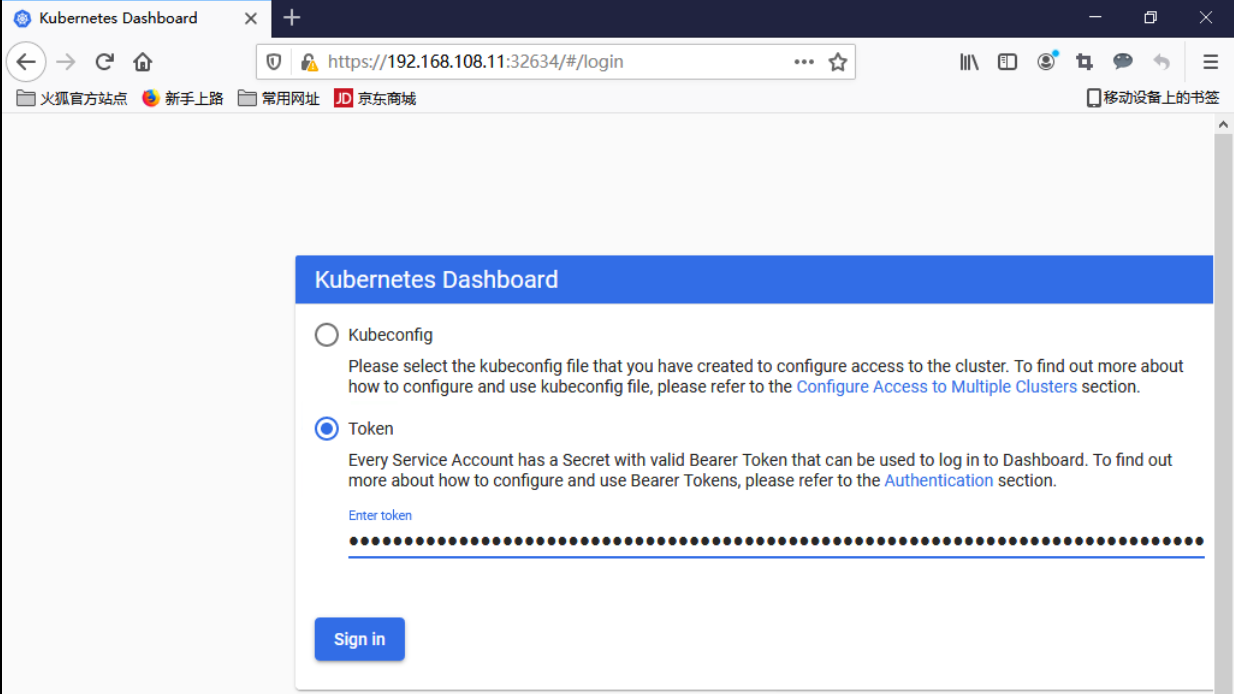
https://192.168.108.11:32634/
2.13.2 通过token令牌访问dashboard 创建管理员token,具有任何空间的权限,可以管理和查看所有资源
1 2 [root@master1 ~]
查看kubernetes-dashboard名称空间下的secret(存放密钥相关的东西)
1 2 3 4 5 6 7 [root@master1 ~]
**找到对应的带有token的kubernetes-dashboard-token-fm4vr **
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]
输入token登录dashboard
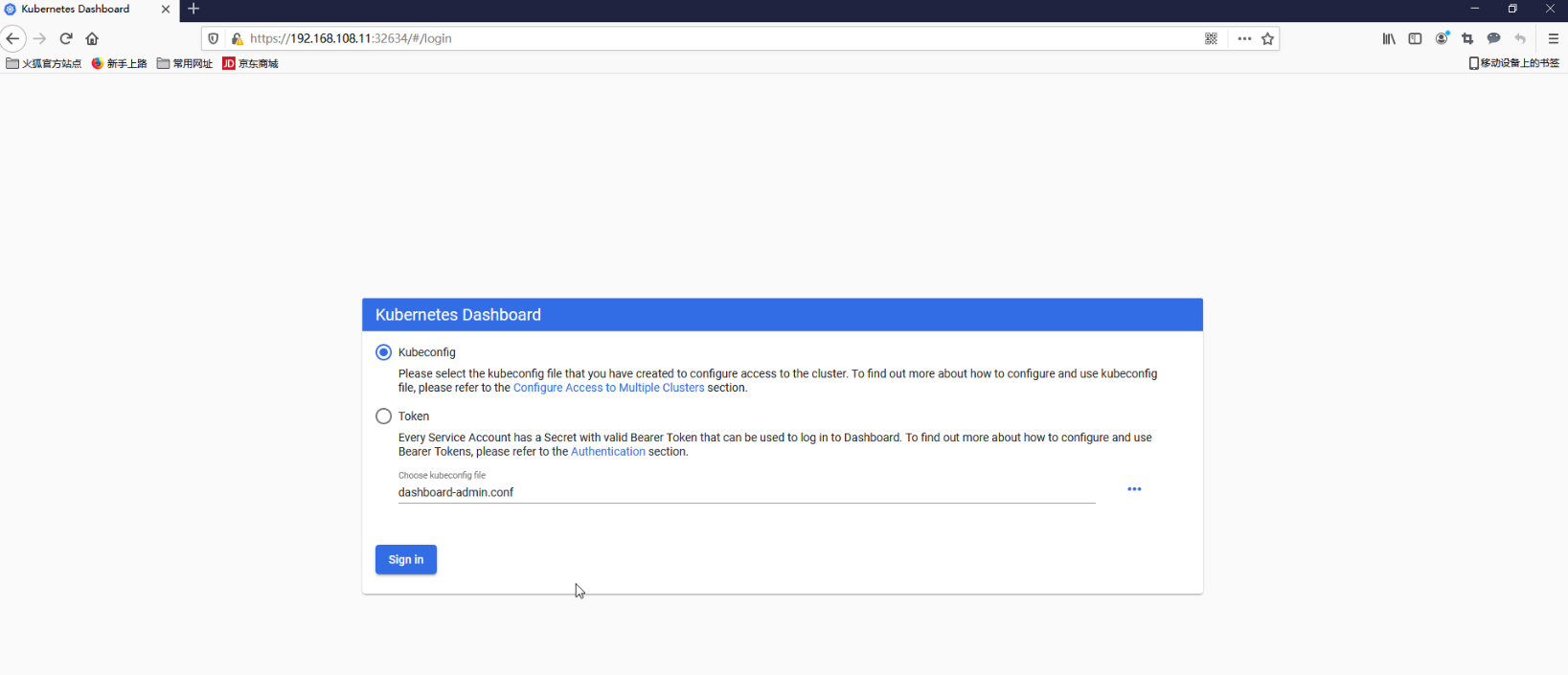
2.13.3 通过kubeconfig文件访问dashboard 创建cluster集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@master1 ~]"kubernetes" set .""
创建credentials(需要使用上面的kubernetes-dashboard-token-fm4vr对应的token信息) 1 2 3 4 5 [root@master1 ~]
创建dashboard-admin用户并使用token 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@master1 ~]"dashboard-admin" set .""
创建context 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@master1 ~]"dashboard-admin@kubernetes" created.""
切换context的current-context是dashboard-admin@kubernetes 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~]"dashboard-admin@kubernetes" .
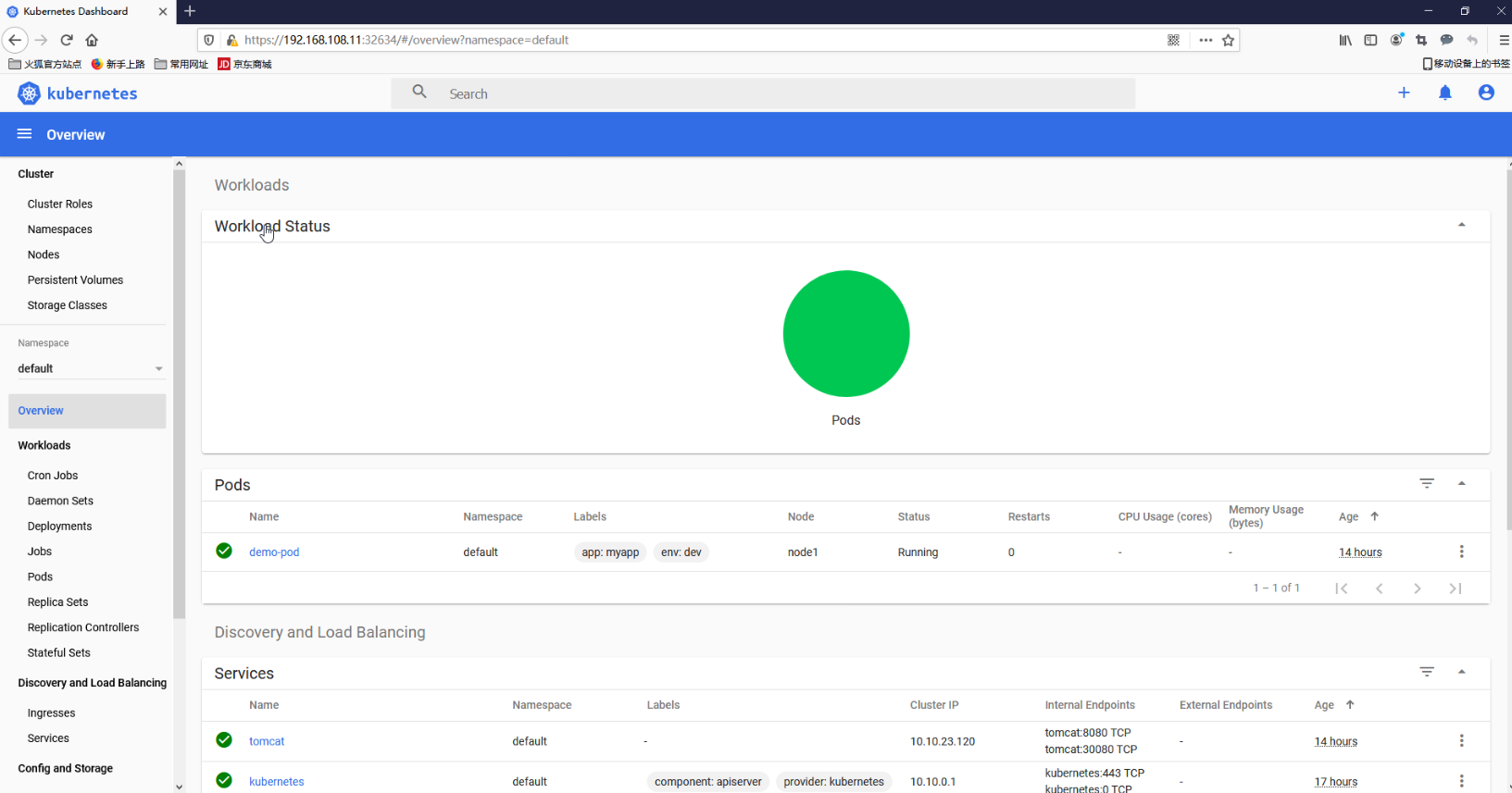
登录
3、K8S企业运维和落地实战 3.1 k8s最小调度单元Pod概述 3.1.1 Pod基本介绍 K8s官方文档: https://kubernetes.io/
K8s中文官方文档: https://kubernetes.io/zh/
K8s Github地址: https://github.com/kubernetes/
官方文档: https://kubernetes.io/docs/concepts/workloads/pods/
Pod是Kubernetes中的最小调度单元,k8s是通过定义一个Pod的资源,然后在Pod里面运行容器,容器需要指定一个镜像,这样就可以用来运行具体的服务。一个Pod封装一个容器(也可以封装多个容器),Pod里的容器共享存储、网络等。也就是说,应该把整个pod看作虚拟机,然后每个容器相当于运行在虚拟机的进程。
Pod中可以同时运行多个容器。同一个Pod中的容器会自动的分配到同一个 node 上。同一个Pod中的容器共享资源、网络环境,它们总是被同时调度,在一个Pod中同时运行多个容器是一种比较高级的用法,只有当你的容器需要紧密配合协作的时候才考虑用这种模式。例如,你有一个容器作为web服务器运行,需要用到共享的volume,有另一个“sidecar”容器来从远端获取资源更新这些文件。
一些Pod有init容器和应用容器。 在应用程序容器启动之前,运行初始化容器。
3.1.2 Pod网络 Pod是有IP地址的,每个pod都被分配唯一的IP地址(IP地址是靠网络插件calico、flannel、weave等分配的),POD中的容器共享网络名称空间,包括IP地址和网络端口。 Pod内部的容器可以使用localhost相互通信。 Pod中的容器也可以通过网络插件calico与其他节点的Pod通信。
3.1.3 Pod存储 创建Pod的时候可以指定挂载的存储卷。 POD中的所有容器都可以访问共享卷,允许这些容器共享数据。 Pod只要挂载持久化数据卷,Pod重启之后数据还是会存在的。
3.1.4 Pod的工作方式 在K8s中,所有的资源都可以使用一个yaml文件来创建,创建Pod也可以使用yaml配置文件。或者使用kubectl run在命令行创建Pod(不常用)。
1) 自主式Pod 直接定义一个Pod资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~]
导入所需镜像
1 2 3 4 [root@node1 ~]
更新资源清单文件
1 2 [root@master1 ~]
查看pod是否创建成功
1 2 3 [root@master1 ~]
自主式Pod存在一个问题,假如我们不小心删除了pod:
1 2 [root@master1 ~]"tomcat-test" deleted
查看pod是否还存在(结果是空,说明pod已经被删除了)
1 2 [root@master1 ~]in default namespace.
通过上面可以看到,如果直接定义一个Pod资源,那Pod被删除,就彻底被删除了,不会再创建一个新的Pod,这在生产环境还是具有非常大风险的,所以今后我们接触的Pod,都是控制器管理的。
2)控制器管理的Pod 常见的管理Pod的控制器: Replicaset、Deployment、Job、CronJob、Daemonset、Statefulset。
控制器管理的Pod可以确保Pod始终维持在指定的副本数运行。
通过Deployment管理Pod
解压镜像
1 2 3 4 [root@node1 ~]
创建一个资源清单文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~]
更新资源清单文件
1 2 [root@master1 ~]
查看deployment
1 2 3 [root@master1 ~]
查看Replicaset
1 2 3 [root@master1 ~]
查看pod
1 2 3 4 [root@master1 ~]
进行pod删除测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@master1 ~]"nginx-test-75c685fdb7-jcpsw" deleted
3.2 创建pod资源 3.2.1 K8s创建Pod流程 Pod是Kubernetes中最基本的部署调度单元,可以包含container,逻辑上表示某种应用的一个实例。例如一个web站点应用由前端、后端及数据库构建而成,这三个组件将运行在各自的容器中,那么我们可以创建包含三个container的pod。
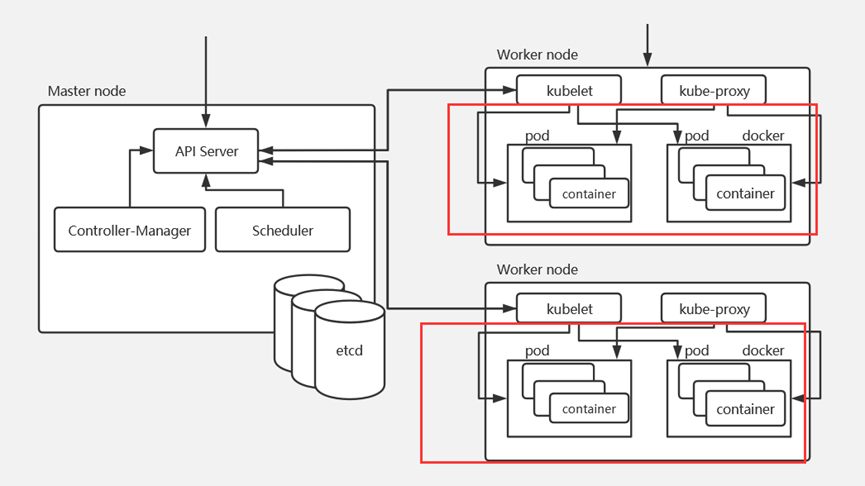
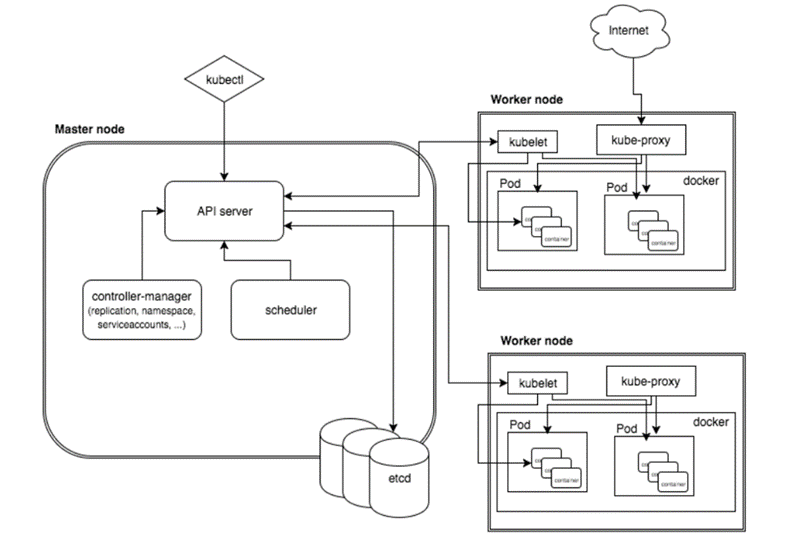
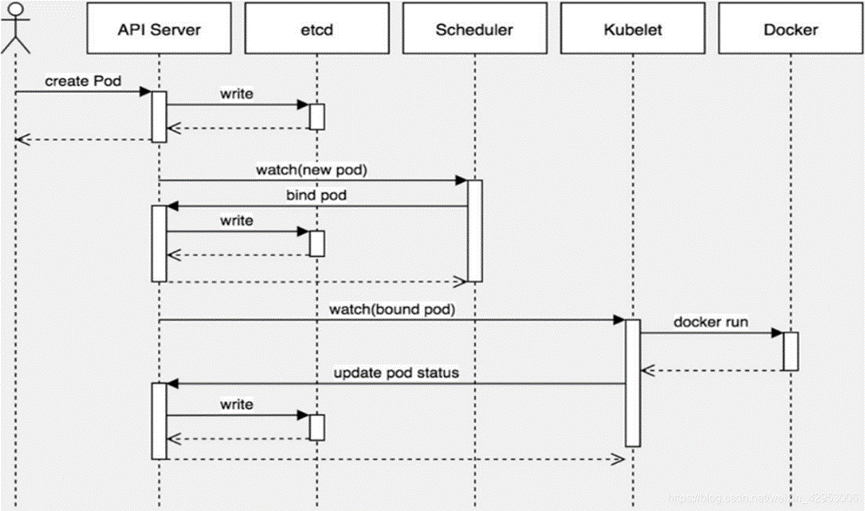
master节点:kubectl -> kube-api -> kubelet -> CRI容器环境初始化
第一步: 客户端提交创建Pod的请求,可以通过调用API Server的Rest API接口,也可以通过kubectl命令行工具。如kubectl apply -f filename.yaml(资源清单文件)
第二步: apiserver接收到pod创建请求后,会将yaml中的属性信息(metadata)写入etcd。
第三步: apiserver触发watch机制准备创建pod,信息转发给调度器scheduler,调度器使用调度算法选择node,调度器将node信息给apiserver,apiserver将绑定的node信息写入etcd
调度器用一组规则过滤掉不符合要求的主机。比如Pod指定了所需要的资源量,那么可用资源比Pod需要的资源量少的主机会被过滤掉。
scheduler 查看 k8s api ,类似于通知机制。
**ps:**同样上述操作的各种信息也要写到etcd数据库中
第四步: apiserver又通过watch机制,调用kubelet,指定pod信息,调用Docker API创建并启动pod内的容器。
第五步: 创建完成之后反馈给kubelet, kubelet又将pod的状态信息给apiserver,
3.2.2 资源清单yaml文件书写技巧 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~]
Pod资源清单编写技巧
通过kubectl explain 查看定义Pod资源包含哪些字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 [root@master1 ~]'s metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata spec <Object> Specification of the desired behavior of the pod. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status status <Object> Most recently observed status of the pod. This data may not be up to date. Populated by the system. Read-only. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status [root@master1 ~]# kubectl explain pod.metadata KIND: Pod VERSION: v1 RESOURCE: metadata <Object> DESCRIPTION: Standard object' s metadata. More info:which set by external tools to store and retrieve arbitrary metadata. Theywhich the object belongs to. This is used toin different clusters.set anywhere right now and apiserver is going to ignoreif set in create or update request.set in happens-before orderset this value. It isin RFC3339 form and is in UTC.for lists. More info:integer >for this object to gracefully terminate before itset when deletionTimestamp is alsoset . May only be shortened. Read-only.which this resource will beset by the server when a graceful deletion isin this field, once theset , this value may notunset or be set further into the future, although it may be shortened orin 30 seconds. The Kubelet will react byin the pod. Afterset , graceful deletion of the objectfor the responsible component that will remove the entry fromin in in order, then this canin which the component responsible for the firstin the list is waiting for a signal (field value, externalfor a finalizer laterin the list, resulting in a deadlock. Without enforced ordering finalizersin the list.return a 409 - instead, it will either return 201 Created or 500 within thein the Retry-After header).if Name is not specified. More info:integer >set of fields that arefor internal housekeeping, and't need to set or understand this field. A workflow can be the user' s name, a controller's name, or the name of a specific apply path like "ci-cd". The set of fields is always in the version that the workflow used when modifying the object. name <string> Name must be unique within a namespace. Is required when creating resources, although some resources may allow a client to request the generation of an appropriate name automatically. Name is primarily intended for creation idempotence and configuration definition. Cannot be updated. More info: http://kubernetes.io/docs/user-guide/identifiers#names namespace <string> Namespace defines the space within which each name must be unique. An empty namespace is equivalent to the "default" namespace, but "default" is the canonical representation. Not all objects are required to be scoped to a namespace - the value of this field for those objects will be empty. Must be a DNS_LABEL. Cannot be updated. More info: http://kubernetes.io/docs/user-guide/namespaces ownerReferences <[]Object> List of objects depended by this object. If ALL objects in the list have been deleted, this object will be garbage collected. If this object is managed by a controller, then an entry in this list will point to this controller, with the controller field set to true. There cannot be more than one managing controller. resourceVersion <string> An opaque value that represents the internal version of this object that can be used by clients to determine when objects have changed. May be used for optimistic concurrency, change detection, and the watch operation on a resource or set of resources. Clients must treat these values as opaque and passed unmodified back to the server. They may only be valid for a particular resource or set of resources. Populated by the system. Read-only. Value must be treated as opaque by clients and . More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#concurrency-control-and-consistency selfLink <string> SelfLink is a URL representing this object. Populated by the system. Read-only. DEPRECATED Kubernetes will stop propagating this field in 1.20 release and the field is planned to be removed in 1.21 release. uid <string> UID is the unique in time and space value for this object. It is typically generated by the server on successful creation of a resource and is not allowed to change on PUT operations. Populated by the system. Read-only. More info: http://kubernetes.io/docs/user-guide/identifiers#uids
3.2.3 创建第一个资源清单文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]
更新资源清单文件
查看pod日志
进入pod里的容器
上面创建的pod是一个自主式pod,也就是通过pod创建一个应用程序,如果pod出现故障停掉,那么我们通过pod部署的应用也就会停掉,不安全, 还有一种控制器管理的pod,通过控制器创建pod,可以对pod的生命周期做管理,可以定义pod的副本数,如果有一个pod意外停掉,那么会自动起来一个pod替代之前的pod,之后会讲解pod的控制器
3.2.4 通过kubectl run创建Pod 1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]
3.3 命名空间 Kubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为命名空间。
命名空间namespace是k8s集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的命名空间,例如,可以为test、devlopment、production环境分别创建各自的命名空间。
3.3.1 namespace应用场景 命名空间适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本不需要创建或考虑命名空间。
1)查看名称空间及其资源对象 k8s集群默认提供了几个名称空间用于特定目的,例如,kube-system主要用于运行系统级资源,存放k8s一些组件的。而default则为那些未指定名称空间的资源操作提供一个默认值。
使用kubectl get namespace可以查看namespace资源,使用kubectl describe namespace $NAME可以查看特定的名称空间的详细信息。
2)管理namespace资源 namespace资源属性较少,通常只需要指定名称即可创建,如“kubectl create namespace qa”。namespace资源的名称仅能由字母、数字、下划线、连接线等字符组成。删除namespace资源会级联删除其包含的所有其他资源对象。
3.3.2 namespace 基本操作 创建一个test命名空间
1 2 3 4 [root@master1 ~]test createdtest Active 21s
切换成kube-system命名空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~]"kubernetes-admin@kubernetes" modified.
查看资源是否属于命名空间级别的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [root@master1 ~]true Bindingtrue ConfigMaptrue Endpointstrue Eventtrue LimitRangetrue PersistentVolumeClaimtrue Podtrue PodTemplatetrue ReplicationControllertrue ResourceQuotatrue Secrettrue ServiceAccounttrue Servicetrue ControllerRevisiontrue DaemonSettrue Deploymenttrue ReplicaSettrue StatefulSettrue LocalSubjectAccessReviewtrue HorizontalPodAutoscalertrue CronJobjobs batch/v1 true Jobtrue Leasetrue NetworkPolicytrue NetworkSettrue EndpointSlicetrue Eventtrue Ingresstrue Ingresstrue NetworkPolicytrue PodDisruptionBudgettrue RoleBindingtrue Role
3.3.3 namespace资源限额 namespace是命名空间,里面有很多资源,那么我们可以对命名空间资源做个限制,防止该命名空间部署的资源超过限制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 "kubernetes-admin@kubernetes" modified.test createdfor i in {1..2}do $i >>/dev/nullif [$? == 0];then $i is upelse $i is false fi
编辑资源配额yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~ ]apiVersion: v1 kind: ResourceQuota metadata: name: mem-cpu-quota namespace: test spec: hard: requests.cpu: "2" requests.memory: 2Gi limits.cpu: "4" limits.memory: 4Gi
应用文件,对test名称空间进行限制
1 2 [root@master1 ~]
查看test名称空间资源限制情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@master1 ~]test
每个容器必须设置内存请求(memory request),内存限额(memory limit),cpu请求(cpu request)和cpu限额(cpu limit)。
limits的值需要大于等于request的值。 requests用于定义当容器请求这么多资源时,k8s会找到满足该条件的node运行该容器。 limits用于限制容器请求的资源最大值。
所有容器的内存请求总额不得超过2GiB。
所有容器的内存限额总额不得超过4 GiB。
所有容器的CPU请求总额不得超过2 CPU。
所有容器的CPU限额总额不得超过4CPU。
创建一个资源限额的pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 [root@master1 ~]test "100Mi" "500m" "2Gi" "2"
查看pod的详细信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 [root@master1 ~]test false for 300sfor 300s
3.4 Pod高级实战:基于污点、容忍度、亲和性的多种调度策略 3.4.1 label标签的使用 1) 标签定义 标签其实就一对 key/value ,被关联到对象上,比如Pod,标签的使用我们倾向于能够表示对象的特殊特点,就是一眼就看出了这个Pod是干什么的,标签可以用来划分特定的对象(比如版本,服务类型等),标签可以在创建一个对象的时候直接定义,也可以在后期随时修改,每一个对象可以拥有多个标签,但是,key值必须是唯一的。创建标签之后也可以方便我们对资源进行分组管理。如果对pod打标签,之后就可以使用标签来查看、删除指定的pod。
在k8s中,大部分资源都可以打标签。
2) 给pod资源打标签 1 2 3 4 5 6 7 8 9
3) 查看资源标签 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 test pod-first 1/1 Running 0 6h35m release=v1
3.4.2 定义pod完整清单文件解读 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 apiVersion: v1 command : [string] exec : command : [string] false false
3.4.3 调度pod到具体的pod节点 我们在创建pod资源的时候,pod会根据schduler进行调度,那么默认会调度到随机的一个工作节点,如果我们想要pod调度到指定节点或者调度到一些具有相同特点的node节点,怎么办呢?
可以使用pod中的nodeName或者nodeSelector字段指定要调度到的node节点
如果同时定义了nodeName或者nodeSelector,那么这个配置文件必须同时满足才可以让pod运行起来,有一个不满足pod都会调度启动失败
1) nodeName 指定pod节点运行在哪个具体node上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@master1 node]command :"/bin/sh" "-c" "sleep 3600"
2) nodeSelector 指定pod调度到具有哪些标签的node节点上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
定义pod的时候指定要调度到具有disk=ceph标签的node上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@master1 node]
3.4.4 pod调度策略之node节点污点和容忍度 1) node节点亲和性 node节点亲和性调度: nodeAffinity
Node节点亲和性针对的是pod和node的关系,Pod调度到node节点的时候匹配的条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 [root@master1 node]'s scheduling constraints Affinity is a group of affinity scheduling rules. FIELDS: nodeAffinity <Object> Describes node affinity scheduling rules for the pod. podAffinity <Object> Describes pod affinity scheduling rules (e.g. co-locate this pod in the same node, zone, etc. as some other pod(s)). podAntiAffinity <Object> Describes pod anti-affinity scheduling rules (e.g. avoid putting this pod in the same node, zone, etc. as some other pod(s)). #prefered表示有节点尽量满足这个位置定义的亲和性,这不是一个必须的条件,软亲和性 #require表示必须有节点满足这个位置定义的亲和性,这是个硬性条件,硬亲和性 [root@master1 node]# kubectl explain pods.spec.affinity.nodeAffinity KIND: Pod VERSION: v1 RESOURCE: nodeAffinity <Object> DESCRIPTION: Describes node affinity scheduling rules for the pod. Node affinity is a group of node affinity scheduling rules. FIELDS: preferredDuringSchedulingIgnoredDuringExecution <[]Object> The scheduler will prefer to schedule pods to nodes that satisfy the affinity expressions specified by this field, but it may choose a node that violates one or more of the expressions. The node that is most preferred is the one with the greatest sum of weights, i.e. for each node that meets all of the scheduling requirements (resource request, requiredDuringScheduling affinity expressions, etc.), compute a sum by iterating through the elements of this field and adding "weight" to the sum if the node matches the corresponding matchExpressions; the node(s) with the highest sum are the most preferred. requiredDuringSchedulingIgnoredDuringExecution <Object> If the affinity requirements specified by this field are not met at scheduling time, the pod will not be scheduled onto the node. If the affinity requirements specified by this field cease to be met at some point during pod execution (e.g. due to an update), the system may or may not try to eventually evict the pod from its node.
例1:使用requiredDuringSchedulingIgnoredDuringExecution硬亲和性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@node1 ~]
我们检查当前节点中有任意一个节点拥有zone标签的值是foo或者bar,就可以把pod调度到这个node节点的foo或者bar标签上的节点上
没有一个拥有zone的标签的值是foo或者bar的节点,使用的是硬亲和性,必须满足条件才能完成调度
1 2 3 4 5 6 7 8 9 10 11 12 13
例2:使用preferredDuringSchedulingIgnoredDuringExecution软亲和性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 [root@master1 node]"pod-nodeaffinity-2" deleted
2) Pod节点亲和性 pod自身的亲和性调度有两种表示形式
podaffinity: pod和pod更倾向腻在一起,把相近的pod结合到相近的位置,如同一区域,同一机架,这样的话pod和pod之间更好通信,比方说有两个机房,这两个机房部署的集群有1000台主机,那么我们希望把nginx和tomcat都部署同一个地方的node节点上,可以提高通信效率;
podunaffinity: pod和pod更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
第一个pod随机选则一个节点,做为评判后续的pod能否到达这个pod所在的节点上的运行方式,这就称为pod亲和性;我们怎么判定哪些节点是相同位置的,哪些节点是不同位置的;我们在定义pod亲和性时需要有一个前提,哪些pod在同一个位置,哪些pod不在同一个位置,这个位置是怎么定义的,标准是什么?以节点名称为标准,这个节点名称相同的表示是同一个位置,节点名称不相同的表示不是一个位置。
topologyKey:
位置拓扑的键,这个是必须字段
怎么判断是不是同一个位置:
rack=rack1
row=row1
使用rack的键是同一个位置
使用row的键是同一个位置
labelSelector:
我们要判断pod跟别的pod亲和,跟哪个pod亲和,需要靠labelSelector,通过labelSelector选则一组能作为亲和对象的pod资源
namespace:
labelSelector需要选则一组资源,那么这组资源是在哪个名称空间中呢,通过namespace指定,如果不指定namespaces,那么就是当前创建pod的名称空间
例1:亲和性 定义两个pod,第一个pod做为基准,第二个pod跟着它走 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 [root@master1 pod]command : ["sh" ,"-c" ,"sleep 3600" ]"myapp2" ]
例2:pod节点反亲和性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 [root@master1 pod]command : ["sh" ,"-c" ,"sleep 3600" ]"myapp1" ]
例3:换一个topologykey 在node1上和node2上打标签
1 2 3 4 5 6 [root@master1 pod]
编写资源配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 [root@master1 pod]command : ["sh" ,"-c" ,"sleep 3600" ]
应用资源配置文件
1 2 3 4 [root@master1 pod]
查看pod启动情况
第二个节点现是pending,因为两个节点是同一个位置,现在没有不是同一个位置的了,而且我们要求反亲和性,所以就会处于pending状态,如果在反亲和性这个位置把required改成preferred,那么也会运行。
podaffinity:pod节点亲和性,pod倾向于哪个pod
nodeaffinity:node节点亲和性,pod倾向于哪个node
1 2 3 [root@master1 pod]
3.4.5 污点、容忍度 给了节点选则的主动权,我们给节点打一个污点,不容忍的pod就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些pod;
taints是键值数据,用在节点上,定义污点;
tolerations是键值数据,用在pod上,定义容忍度,能容忍哪些污点
pod亲和性是pod属性;但是污点是节点的属性,污点定义在nodeSelector上
1)查看node节点的污点 1 2 3 4 5 6 7 8 [root@master1 pod]
2) taints的effect用来定义对pod对象的排斥等级(效果) NoSchedule:
仅影响pod调度过程,当pod能容忍这个节点污点,就可以调度到当前节点,后来这个节点的污点改了,加了一个新的污点,使得之前调度的pod不能容忍了,那这个pod会怎么处理,对现存的pod对象不产生影响
NoExecute:
既影响调度过程,又影响现存的pod对象,如果现存的pod不能容忍节点后来加的污点,这个pod就会被驱逐
PreferNoSchedule:
最好不,也可以,是NoSchedule的柔性版本
在pod对象定义容忍度的时候支持两种操作:
1.等值密钥:key和value上完全匹配
2.存在性判断:key和effect必须同时匹配,value可以是空
在pod上定义的容忍度可能不止一个,在节点上定义的污点可能多个,需要琢个检查容忍度和污点能否匹配,每一个污点都能被容忍,才能完成调度,如果不能容忍怎么办,那就需要看pod的容忍度了
3) 例1:将node2当成生产环境专用的,node1是测试的 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
4) 例2:将node1也打上污点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@master1 taint-test]"taint-pod" deleted
修改配置文件,定义pod容忍度精确匹配node上的污点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@master1 taint-test]"NoSchedule" "node-type" "Equal" "production"
将operator的值改为Exists(表示只要key存在,那么value自动匹配)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@master1 taint-test]"NoSchedule" "node-type" "Exists" ""
删除node节点的污点
1 2 3 4 5 6 7 [root@master1 taint-test]
3.4.6 Pod常见异常状态解决方案 1) pod的STATUS常见的状态 挂起(Pending) :我们在请求创建pod时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件,已经创建了pod但是没有适合它运行的节点叫做挂起,调度没有完成,处于pending的状态会持续一段时间:包括调度Pod的时间和通过网络下载镜像的时间。
运行中(Running): Pod已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
成功(Succeeded): Pod 中的所有容器都被成功终止,并且不会再重启。
失败(Failed): Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
未知(Unknown): 未知状态,所谓pod是什么状态是apiserver和运行在pod节点的kubelet进行通信获取状态信息的,如果节点之上的kubelet本身出故障,那么apiserver就连不上kubelet,得不到信息了,就会看Unknown
扩展:还有其他状态,如下:
Evicted状态: 出现这种情况,多见于系统内存或硬盘资源不足,可df-h查看docker存储所在目录的资源使用情况,如果百分比大于85%,就要及时清理下资源,尤其是一些大文件、docker镜像。
CrashLoopBackOff: 容器曾经启动了,但可能又异常退出了(pod内的容器经常重启就会变成这种状态)
Error 状态: Pod 启动过程中发生了错误
3.4.7 Pod的重启策略 Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据 RestartPolicy 的设置来进行相应的操作。
Pod的重启策略包括 Always、OnFailure和Never,默认值为Always。
Always: 当容器失败时,由kubelet自动重启该容器。
OnFailure: 当容器终止运行且退出码不为0时,由kubelet自动重启该容器。(也就是非正常退出才会重启pod)
Never: 不论容器运行状态如何,kubelet都不会重启该容器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master1 pod-restart]
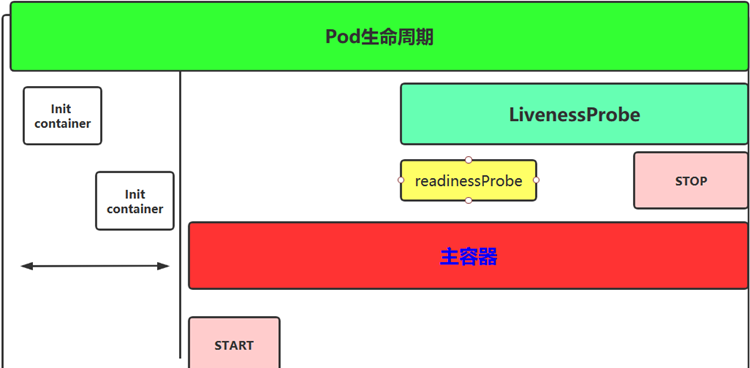
3.5 Pod高级实战-Pod健康探测和启动钩子、停止钩子
3.5.1 pod中初始化容器initcontainer概述 Pod 里面可以有一个或者多个容器,部署应用的容器可以称为主容器,在创建Pod时候,Pod 中可以有一个或多个先于主容器启动的Init容器,这个init容器就可以成为初始化容器,初始化容器一旦执行完,它从启动开始到初始化代码执行完就退出了,它不会一直存在,所以在主容器启动之前执行初始化,初始化容器可以有多个,多个初始化容器是要串行执行的,先执行初始化容器1,在执行初始化容器2等,等初始化容器执行完初始化就退出了,然后再执行主容器,主容器一退出,pod就结束了,主容器退出的时间点就是pod的结束点,它俩时间轴是一致的;
Init容器就是做初始化工作的容器。可以有一个或多个,如果多个按照定义的顺序依次执行,只有所有的初始化容器执行完后,主容器才启动。由于一个Pod里的存储卷是共享的,所以Init Container里产生的数据可以被主容器使用到,Init Container可以在多种K8S资源里被使用到,如Deployment、DaemonSet, StatefulSet、Job等,但都是在Pod启动时,在主容器启动前执行,做初始化工作。
Init容器与普通的容器区别是:
1、Init 容器不支持 Readiness,因为它们必须在Pod就绪之前运行完成
2、每个Init容器必须运行成功,下一个才能够运行
3、如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止,然而,如果Pod对应的restartPolicy值为 Never,它不会重新启动。
初始化容器的官方地址:
https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#init-containers-in-use
3.5.2 主容器 1)容器钩子 初始化容器启动之后,开始启动主容器,在主容器启动之前有一个post start hook(容器启动后钩子)和pre stop hook(容器结束前钩子),无论启动后还是结束前所做的事我们可以把它放两个钩子,这个钩子就表示用户可以用它来钩住一些命令,来执行它,做开场前的预设,结束前的清理,如awk有begin,end,和这个效果类似;
postStart: 该钩子在容器被创建后立刻触发,通知容器它已经被创建。如果该钩子对应的hook handler执行失败,则该容器会被杀死,并根据该容器的重启策略决定是否要重启该容器,这个钩子不需要传递任何参数。
preStop: 该钩子在容器被删除前触发,其所对应的hook handler必须在删除该容器的请求发送给Docker daemon之前完成。在该钩子对应的hook handler完成后不论执行的结果如何,Docker daemon会发送一个SGTERN信号量给Docker daemon来删除该容器,这个钩子不需要传递任何参数。
在k8s中支持两类对pod的检测,第一类叫做livenessprobe(pod存活性探测):
存活探针主要作用是,用指定的方式检测pod中的容器应用是否正常运行,如果检测失败,则认为容器不健康,那么Kubelet将根据Pod中设置的 restartPolicy来判断Pod 是否要进行重启操作,如果容器配置中没有配置 livenessProbe,Kubelet 将认为存活探针探测一直为成功状态。
第二类是状态检readinessprobe(pod就绪性探测):用于判断容器中应用是否启动完成,当探测成功后才使Pod对外提供网络访问,设置容器Ready状态为true,如果探测失败,则设置容器的Ready状态为false。
3.5.3 创建pod经过的阶段 当用户创建pod时,这个请求给apiserver,apiserver把创建请求的状态保存在etcd中;
接下来apiserver会请求scheduler来完成调度,如果调度成功,会把调度的结果(如调度到哪个节点上了,运行在哪个节点上了,把它更新到etcd的pod资源状态中)保存在etcd中,一旦存到etcd中并且完成更新以后,如调度到xianchaonode1上,那么xianchaonode1节点上的kubelet通过apiserver当中的状态变化知道有一些任务被执行了,所以此时此kubelet会拿到用户创建时所提交的清单,这个清单会在当前节点上运行或者启动这个pod,如果创建成功或者失败会有一个当前状态,当前这个状态会发给apiserver,apiserver在存到etcd中;在这个过程中,etcd和apiserver一直在打交道,不停的交互,scheduler也参与其中,负责调度pod到合适的node节点上,这个就是pod的创建过程
pod在整个生命周期中有非常多的用户行为:
1、初始化容器完成初始化
2、主容器启动后可以做启动后钩子
3、主容器结束前可以做结束前钩子
4、在主容器运行中可以做一些健康检测,如liveness probe,readness probe
3.5.4 pod容器探测和钩子 1) postStart和preStop postStart :容器创建成功后,运行前的任务,用于资源部署、环境准备等
preStop :在容器被终止前的任务,用于优雅关闭应用服务、通知其他系统等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 containers:exec :command :
以上示例中,定义了一个Pod,包含一个JAVA的web应用容器,其中设置了PostStart和PreStop回调函数。即在容器创建成功后,复制/sample.war到/app文件夹中。而在容器终止之前,发送HTTP请求到http://monitor.com:8080/waring,即向监控系统发送警告。
优雅的删除资源对象
当用户请求删除含有pod的资源对象时(如RC、deployment等),K8S为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S提供两种信息通知:
1)、默认:K8S通知node执行docker stop命令,docker会先向容器中PID为1的进程发送系统信号SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送SIGKILL的系统信号强行kill掉进程。
2)、使用pod生命周期(利用PreStop回调函数),它执行在发送终止信号之前。
默认情况下,所有的删除操作的优雅退出时间都在30秒以内。kubectl delete命令支持–grace-period=的选项,以运行用户来修改默认值。0表示删除立即执行,并且立即从API中删除pod。在节点上,被设置了立即结束的的pod,仍然会给一个很短的优雅退出时间段,才会开始被强制杀死。
1 2 3 4 5 6 7 8 9 10 11 12 spec:exec :command : ["/usr/local/nginx/sbin/nginx" ,"-s" ,"quit" ]
2) livenessProbe存活性探测和readinessProbe就绪性探测 livenessProbe:存活性探测
许多应用程序经过长时间运行,最终过渡到无法运行的状态,除了重启,无法恢复。通常情况下,K8S会发现应用程序已经终止,然后重启应用程序pod。有时应用程序可能因为某些原因(后端服务故障等)导致暂时无法对外提供服务,但应用软件没有终止,导致K8S无法隔离有故障的pod,调用者可能会访问到有故障的pod,导致业务不稳定。K8S提供livenessProbe来检测容器是否正常运行,并且对相应状况进行相应的补救措施。
readinessProbe:就绪性探测
在没有配置readinessProbe的资源对象中,pod中的容器启动完成后,就认为pod中的应用程序可以对外提供服务,该pod就会加入相对应的service,对外提供服务。但有时一些应用程序启动后,需要较长时间的加载才能对外服务,如果这时对外提供服务,执行结果必然无法达到预期效果,影响用户体验。比如使用tomcat的应用程序来说,并不是简单地说tomcat启动成功就可以对外提供服务的,还需要等待spring容器初始化,数据库连接上等等。
目前LivenessProbe和ReadinessProbe两种探针都支持下面三种探测方法:
1、ExecAction: 在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
2、TCPSocketAction: 通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
3、HTTPGetAction: 通过容器的IP地址、端口号及路径调用 HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康
探针探测结果有以下值:
1、Success:表示通过检测。
2、Failure:表示未通过检测。
3、Unknown:表示检测没有正常进行。
Pod探针相关的属性:
探针(Probe)有许多可选字段,可以用来更加精确的控制Liveness和Readiness两种探针的行为
initialDelaySeconds: Pod启动后首次进行检查的等待时间,单位“秒”。
periodSeconds: 检查的间隔时间,默认为10s,单位“秒”。
timeoutSeconds: 探针执行检测请求后,等待响应的超时时间,默认为1s,单位“秒”。
successThreshold:连续探测几次成功,才认为探测成功,默认为 1,在 Liveness 探针中必须为1,最小值为1。
failureThreshold: 探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod会被标记为未就绪,默认为 3,最小值为 1
两种探针区别:
ReadinessProbe 和 livenessProbe 可以使用相同探测方式,只是对 Pod 的处置方式不同:
readinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
livenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施。
LivenessProbe 探针使用示例 容器启动设置执行的命令:
/bin/sh -c “touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600”
容器在初始化后,首先创建一个 /tmp/healthy 文件,然后执行睡眠命令,睡眠 30 秒,到时间后执行删除 /tmp/healthy 文件命令。而设置的存活探针检检测方式为执行 shell 命令,用 cat 命令输出 healthy 文件的内容,如果能成功执行这条命令,存活探针就认为探测成功,否则探测失败。在前 30 秒内,由于文件存在,所以存活探针探测时执行 cat /tmp/healthy 命令成功执行。30 秒后 healthy 文件被删除,所以执行命令失败,Kubernetes 会根据 Pod 设置的重启策略来判断,是否重启 Pod。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@master1 livenessProbe]exec :command :
通过HTTP方式做健康探测
pod 中启动的容器是一个 SpringBoot 应用,其中引用了 Actuator 组件,提供了 /actuator/health 健康检查地址,存活探针可以使用 HTTPGet 方式向服务发起请求,请求 8081 端口的 /actuator/health 路径来进行存活判断:
任何大于或等于200且小于400的代码表示探测成功。
任何其他代码表示失败。
如果探测失败,则会杀死 Pod 进行重启操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@master1 livenessProbe]
通过tcp的方式做健康测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@master1 liveness]
TCP 检查方式和 HTTP 检查方式非常相似,在容器启动 initialDelaySeconds 参数设定的时间后,kubelet 将发送第一个 livenessProbe 探针,尝试连接容器的 80 端口 ,如果连接失败则将杀死 Pod 重启容器。
ReadinessProbe 探针使用示例 Pod 的ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种,只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。这里用一个 Springboot 项目,设置 ReadinessProbe 探测 SpringBoot 项目的 8081 端口下的 /actuator/health 接口,如果探测成功则代表内部程序以及启动,就开放对外提供接口访问,否则内部应用没有成功启动,暂不对外提供访问,直到就绪探针探测成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 [root@master1 liveness]type : NodePort
livenessprobe与readnessprobe配合使用案例 一般程序中需要设置两种探针结合使用,并且也要结合实际情况,来配置初始化检查时间和检测间隔