Filebeat采集日志->kafka topic存起来日志->logstash去kafka获取日志,进行格式转换->elasticsearch->kibana
1、安装zookeeper集群 准备三台机器安装zookeeper高可用集群
1 2 3 4 5 6 7 8 9 10 准备三台机器安装zookeeper高可用集群"s/^SELINUX.*/SELINUX=disabled/g" /etc/selinux/config
1.1 zookeeper简介 zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)、kafka消息系统的管理员, Apache Hbase 和 Apache Solr 的分布式集群都用到了 zookeeper;Zookeeper是一个分布式的、开源的程序协调服务,是 hadoop 项目下的一个子项目。它提供的主要功能包括:配置管理、名字服务、分布式锁、集群管理。
1.2 Zookeeper主要作用 1. 2.1 节点选举 Master节点,主节点挂了之后,从节点就会接手工作 ,并且,保证这个节点是唯一的,这就是首脑模式,从而保证集群的高可用
1.2.2 统一配置文件管理 只需要部署一台服务器
则可以把相同的配置文件,同步更新到其他所有服务器,比如,修改了Hadoop,Kafka,redis统一配置等
1.2.3 发布与订阅消息 类似于消息队列,发布者把数据存在znode节点上,订阅者会读取这个数据
1.2.4 集群管理 集群中保证数据的一致性
Zookeeper的选举机制===>过半机制安装的台数===>奇数台(否则无法过半机制)
一般情况下10台服务器需安装ZK3台
20台======>5台
50台=======>7台
100台=======>11台
1.2.5 zookeeper角色 leader 领导者 :负责发起选举和决议的,更新系统状态
follower 跟随者:接收客户端请求,给客户端返回结果,在选举的过程中参与投票
observer 观察者:接收客户端的连接,同步leader状态,不参与选主
1.3 解压zookeeper并作配置 1 2 3 scp apache-zookeeper-3.8.0-bin.tar.gz 192.168.101.31:/opt/
1 2 3
1 2 3
1 2 3 4 5 6 cd /opt/zookeeper/conf"s/^dataDir.*/dataDir=\/opt\/zookeeper/g" zoo.cfg echo "dataLogDir=/opt/zookeeper/zkLog" >> zoo.cfgecho -e "server.1=192.168.101.31:2188:3888\nserver.2=192.168.101.32:2188:3888\nserver.3=192.168.101.33:2188:3888" >>zoo.cfg
1 2 3 4 5 cd /opt/zookeeper/echo `hostname | awk -F "oo" {'print $2' }` > myidcd /opt/zookeeper/bin && nohup ./zkServer.sh start ../conf/zoo.cfg &
1 2 3 cd /opt/zookeeper/bin/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 test "zy" test test set /test "zyzy" test
2、单节点安装kafka集群 2.1 kafka介绍 Kafka 是一种高吞吐量的分布式发布订阅消息系统,即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。采用生产者消费者模型
基于 Kafka-ZooKeeper 的分布式消息队列系统总体架构如下:
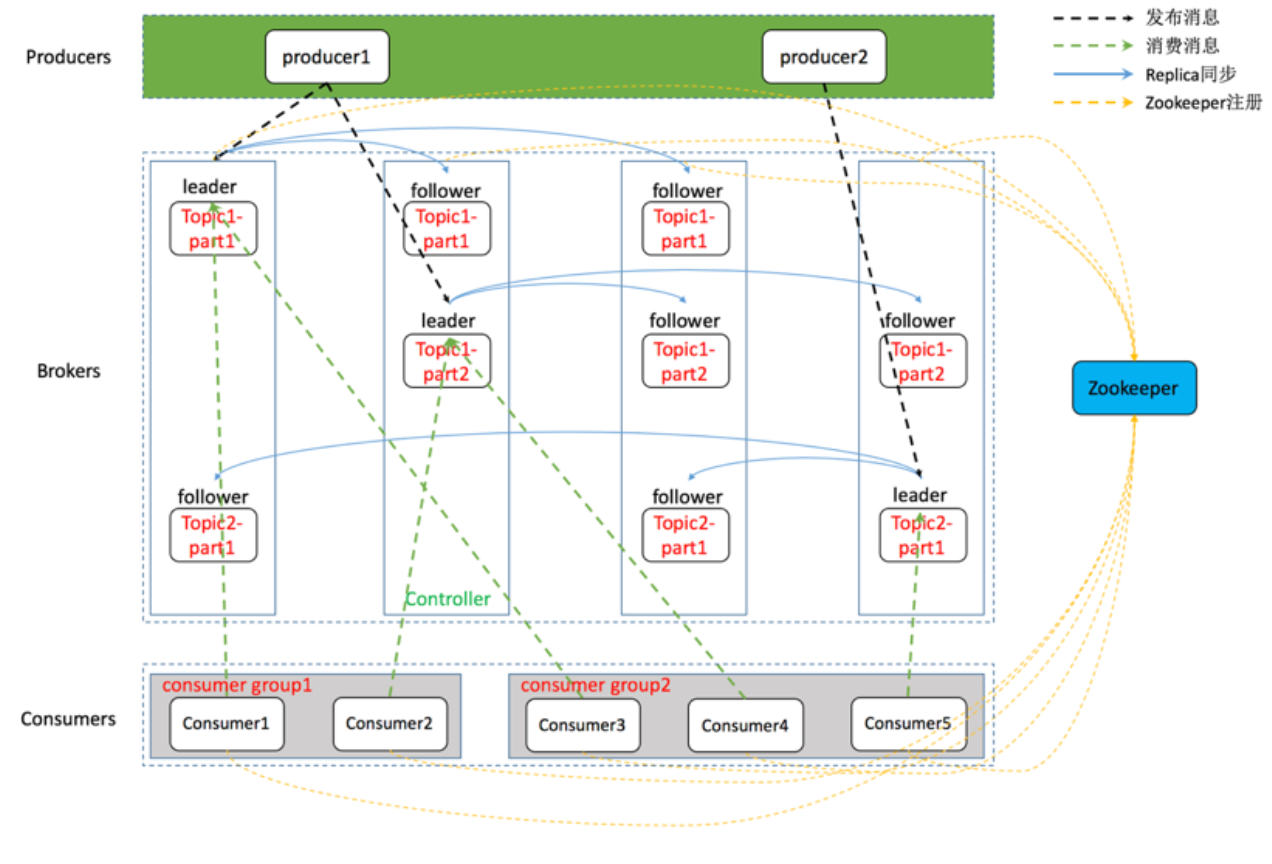
一个典型的 Kafka 体系架构包括若干 Producer(消息生产者),若干 broker(作为 Kafka 节点的服务器),若干 Consumer(Group),以及一个 ZooKeeper 集群。Kafka通过 ZooKeeper 管理集群配置、选举 Leader 以及在 consumer group 发生变化时进行 Rebalance(即消费者负载均衡,在下一课介绍)。Producer 使用 push(推)模式将消息发布到 broker,Consumer 使用 pull(拉)模式从 broker 订阅并消费消息。
上图仅描摹了一个总体架构,并没有对作为 Kafka 节点的 broker 进行深入刻画,事实上,它的内部细节相当复杂,如下图所示,Kafka 节点涉及 Topic、Partition 两个重要概念。
2.2 kafka相关术语 Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer:负责发布消息到Kafka broker,生产者,消息的发送者。
Consumer:消息消费者,向Kafka broker读取消息的客户端。
Consumer group:high-level consumer API 中,每个 consumer 都属于一个 consumer-group,每条消息只能被 consumer-group 中的一个 Consumer 消费,但可以被多个 consumer-group 消费;
replicas:partition 的副本,保障 partition 的高可用;
leader:replicas 中的一个角色, producer 和 consumer 只跟 leader 交互;
follower:replicas 中的一个角色,从 leader 中复制数据,作为副本,一旦 leader 挂掉,会从它的 followers 中选举出一个新的 leader 继续提供服务;
controller:Kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover;
ZooKeeper:Kafka 通过 ZooKeeper 来存储集群的 meta 信息等
2.3 配置kafka 1 2 3 4 5 6 7 8 9 10 cd /opt/kafka/config
zookeeper在kafka中的作用:管理broker、consumer,创建Broker后,向zookeeper注册新的broker信息,实现在服务器正常运行下的水平拓展。
2.4 启动kafka 1 cd /opt/kafka/bin && ./kafka-server-start.sh -daemon ../config/server.properties
2.5 登录zookeeper客户端查看/brokers/ids 1 2 3 4 5 6 [root@zoo3 bin]
3、生产者和消费者测试 3.1 创建主题quickstart-events 1 2 3 [root@zoo3 bin]
3.2 查看topic 1 2 3 [root@zoo3 bin]
3.3 topic写入消息 1 2 3 4 [root@zoo3 bin]
3.4 打开新的终端从topic读取消息 1 2 [root@zoo3 ~]
4、安装kafka高可用集群 将kafka安装文件拷贝到zoo1和zoo2中,这两台服务器不同的地方在于配置文件中的borker.id和listeners监听
1 2 3
4.1 修改kafka配置文件 1 2 3 4 5 6 7 8 9 10 11 12
4.2 启动kafka 1 2 3 [root@zoo1 ~]
4.3 登陆zookeeper客户端查看/brokers/ids 1 2 3 [root@zoo3 bin]
5、部署filebeat服务 在zoo2上部署
filebeat是轻量级的日志收集组件
zoo2安装nginx,利用filebeat采集nginx日志(测试用,看能否产生日志)
5.1 kafka集群创建topic(存放日志数据) 1 2 [root@zoo3 bin]
5.2 配置和安装filebeat服务 5.3 启动filebeat nginx模块 1 2 3 [root@zoo2 filebeat]
5.4 编写文件filebeat_nginx.yaml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@zoo2 filebeat]true "/var/log/nginx/access.log*" ]true "/var/log/nginx/error.log*" ]true '192.168.101.31:9092' , '192.168.101.32:9092' ,'192.168.101.33:9092' ]'test-topic' '%{[message]}'
5.5 启动filebeat(直接启动会报错) 修改filebeat参数,将false改成true
1 2 [root@zoo2 filebeat]true
5.6 进行测试 请求nginx
查看kafka topic是否有日志数据
1 2 [root@zoo3 bin]
6、部署logstash 6.1 解压与下载软件 在zoo2上部署
logsstash是日志收集组建,但是占用的资源较多,一半是用来对数据格式进行转换
1 2 3 4 5 6 [root@zoo2 ~]
6.2 添加logstash配置文件 bootstrap_servers =>指定kafka集群地址
hosts => 指定es主机地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@zoo2 ~]"192.168.101.31:9092,192.168.101.32:9092 ,192.168.101.33:9092" ]"latest" true "test-topic" ]"json" "192.168.101.32:9200" ]"kafkalog-%{+YYYY.MM.dd}"
6.3 启动logstash服务 1 2 [root@zoo2 config]
7、部署es和kibana服务 在zoo2上部署
elasticsearch是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。elasticsearch具有三大功能,搜索、分析、存储数据
7.1 安装es服务 安装docker
1 2 3 4 5 [root@zoo2 ~]
导入es镜像
创建es的docker容器
1 2 3 4 5 6 [root@zoo2 ~]"/tini -- /usr/local…" About a minute ago Up About a minute 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9330->9300/tcp, :::9330->9300/tcp es
7.2 安装kibana kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在Elasticsearch指标中的日志数据。Kibana功能众多,在“Visualize” 菜单界面可以将查询出的数据进行可视化展示,“Dev Tools” 菜单界面可以让户方便地通过浏览器直接与 Elasticsearch 进行交互,发送 RESTFUL对 Elasticsearch 数据进行增删改查。。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
解压docker镜像包
创建docker容器
修改kibana的配置
1 2 3 4 5 6 7 8 9 10 11 [root@zoo2 ~]"0" "http://192.168.101.32:9200" ]true
重启kibana容器
配置kibana ui界面
http://192.168.101.32:5601/app/home#/
回到kibana首页,点击Discover查看日志:
总结:
19.1 安装zookeeper
19.2 安装kafka
19.3 部署filebeat服务
19.4 部署logstash服务
19.5 部署es和kibana服务
19.6 配置kibana ui界面