PromQL基础
1. 简介
Prometheus 通过指标名称(metrics name)以及对应的一组标签(labelset)唯一定义一条时间序列。指标名称反映了监控样本的基本标识,而 label 则在这个基本特征上为采集到的数据提供了多种特征维度。用户可以基于这些特征维度过滤,聚合,统计从而产生新的计算后的一条时间序列。
PromQL 是 Prometheus 内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在 Prometheus 的日常应用当中,包括对数据查询、可视化、告警处理当中,可以这么说,PromQL 是 Prometheus 所有应用场景的基础。
2. 示例应用
为了尽可能详细地给大家演示 PromQL 指标查询,这里我们将 Fork 一个开源的 Prometheus 演示服务来进行查询,这样可以让我们更加灵活地对指标数据进行控制,项目仓库地址:https://github.com/juliusv/prometheus_demo_service,这是一个 Go 语言开发的服务,我们可以自己构建应用。
该演示服务模拟了一些用于我们测试的监控指标,包括:
- 暴露请求计数和响应时间(以
path、method和响应状态码status为标签 key)的 HTTP API 服务 - 一个定期的批处理任务,它暴露了最后一次成功运行的时间戳和处理的字节数
- 有关 CPU 数量及其使用情况的综合指标
- 有关内存使用情况的综合指标
- 有关磁盘总大小及其使用情况的综合指标
- 其他指标……
2.1 环境准备
首先准备 golang 环境:
1 | |
clone 代码构建:
1 | |
2.2 启动服务
1 | |
2.3 查看服务启动的端口
1 | |
2.4 验证指标数据是否成功
1 | |
3. 配置prometheus
3.1 下载prometheus
1 | |
3.2 修改配置文件
1 | |
3.3 启动服务
1 | |
4. 查询基础
4.1 结果类型
在查询 Prometheus 时,有两个类型的概念经常出现,区分它们很重要。
- 抓取目标报告的指标类型:
counter、gauge、histogram、summary。 - PromQL 表达式的结果数据类型:字符串、标量、瞬时向量或区间向量。
PromQL 实际上没有直接的指标类型的概念,只关注表达式的结果类型。每个 PromQL 表达式都有一个类型,每个函数、运算符或其他类型的操作都要求其参数是某种表达式类型。例如,rate() 函数要求它的参数是一个区间向量,但是 rate() 本身评估为一个瞬时向量输出。
PromQL 中可能的表达式类型包括:
string(字符串):字符串只会作为某些函数(如label_join()和label_replace())的参数出现。scalar(标量):一个单一的数字值,如 1.234,这些数字可以作为某些函数的参数,如topk(3, ...),也会出现在算术运算中。instant vector(瞬时向量):一组标记的时间序列,每个序列有一个样本,都在同一个时间戳,瞬时向量可以由 TSDB 时间序列选择器直接产生,如node_cpu_seconds_total,也可以由任何函数或其他转换来获取。
1 | |
range vector(区间向量):一组标记的时间序列,每个序列都有一个随时间变化的样本范围。在 PromQL 中只有两种方法可以生成区间向量:在查询中使用字面区间向量选择器(如node_cpu_seconds_total[5m]),或使用子查询表达式(如<expression>[5m:10s]),当想要在指定的时间窗口内聚合一个序列的行为时,区间向量非常有用,就像rate(node_cpu_seconds_total[5m])计算每秒增加率一样,在node_cpu_seconds_total指标的最近 5 分钟内求平均值。
1 | |
4.2 查询类型和评估时间
PromQL 查询中对时间的引用只有相对引用,比如 [5m],表示过去 5 分钟,那么如何指定一个绝对的时间范围,或在一个表格中显示查询结果的时间戳?在 PromQL 中,这样的时间参数是与表达式分开发送到 Prometheus 查询 API 的,确切的时间参数取决于你发送的查询类型,Prometheus 有两种类型的 PromQL 查询:瞬时查询和区间查询。
4.2.1 瞬时查询
瞬时查询用于类似表格的视图,你想在一个时间点上显示 PromQL 查询的结果。一个瞬时查询有以下参数:
- PromQL 表达式
- 一个评估的时间戳
在查询的时候可以选择查询过去的数据,比如 foo[1h] 表示查询 foo 序列最近 1 个小时的数据,访问过去的数据,对于计算一段时间内的比率或平均数等聚合会非常有用。
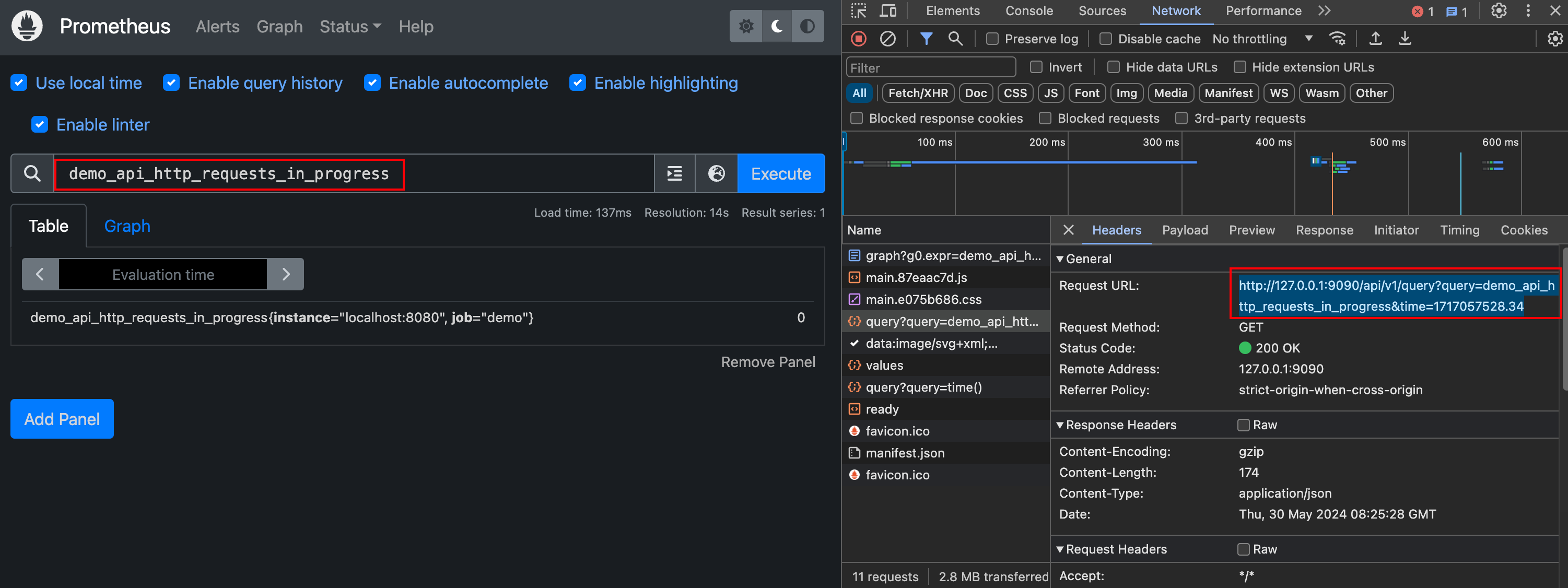
在 Prometheus 的 WebUI 界面中表格视图中的查询就是瞬时查询,API 接口 /api/v1/query?query=xxxx&time=xxxx 中的 query 参数就是 PromQL 表达式,time 参数就是评估的时间戳。瞬时查询可以返回任何有效的 PromQL 表达式类型(字符串、标量、即时和范围向量)。
4.2.2 区间查询
区间查询主要用于图形,想在一个指定的时间范围内显示一个 PromQL 表达式,范围查询的工作方式与即时查询完全相同,这些查询在指定时间范围的评估步长中进行评估。当然,这在后台是高度优化的,在这种情况下,Prometheus 实际上并没有运行许多独立的即时查询。区间查询包括以下一些参数:
- PromQL 表达式
- 开始时间
- 结束时间
- 评估步长
在开始时间和结束时间之间的每个评估步长上评估表达式后,单独评估的时间片被拼接到一个单一的区间向量中。区间查询允许传入瞬时向量类型或标量类型的表达式,但始终返回一个范围向量(标量或瞬时向量在一个时间范围内被评估的结果)。
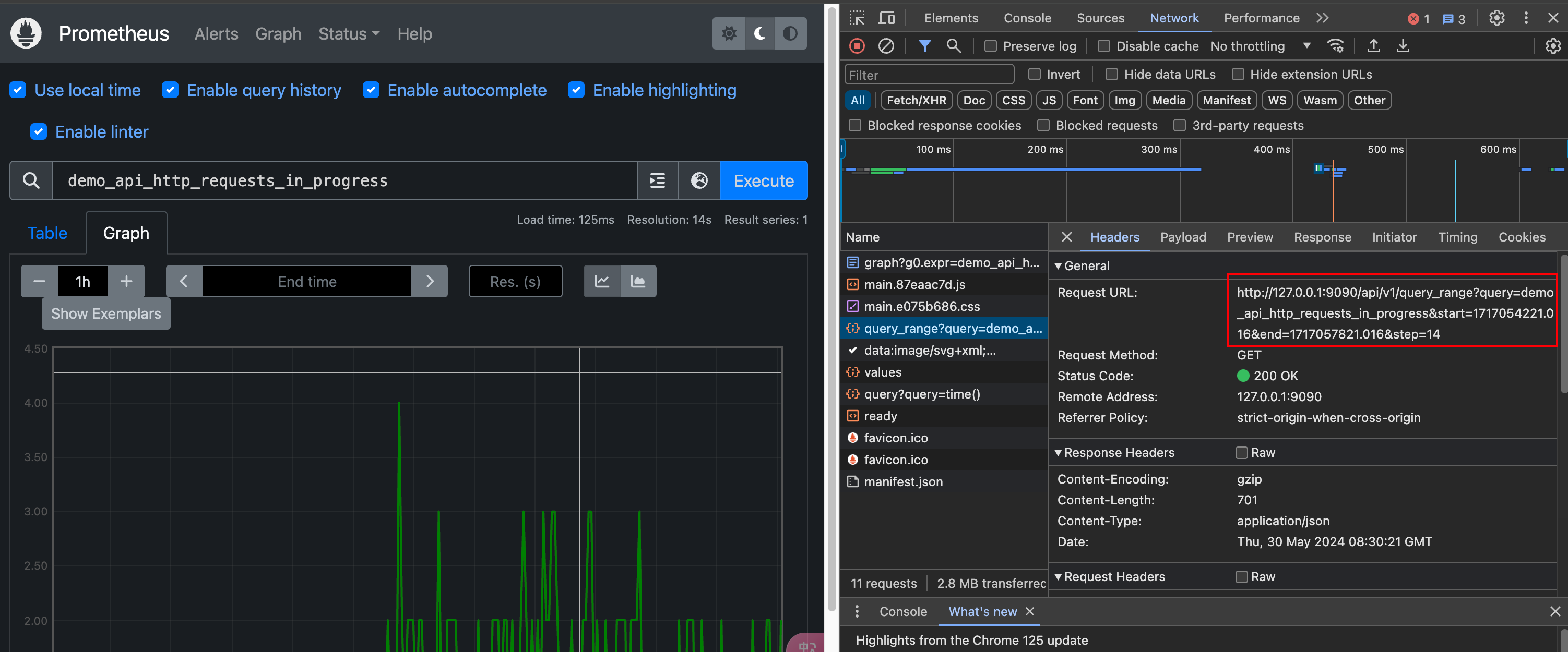
在 Prometheus 的 WebUI 界面中图形视图中的查询就是区间查询,API 接口 /api/v1/query_range?query=xxx&start=xxxxxx&end=xxxx&step=14 中的 query 参数就是 PromQL 表达式,start 为开始时间,end 为结束时间,step 为评估的步长。
4.3 选择序列
学习如何用不同的方式来选择数据,如何在单个时间戳或一段时间范围内基于标签过滤数据,以及如何使用移动时间的方式来选择数据。
4.3.1 过滤指标名称
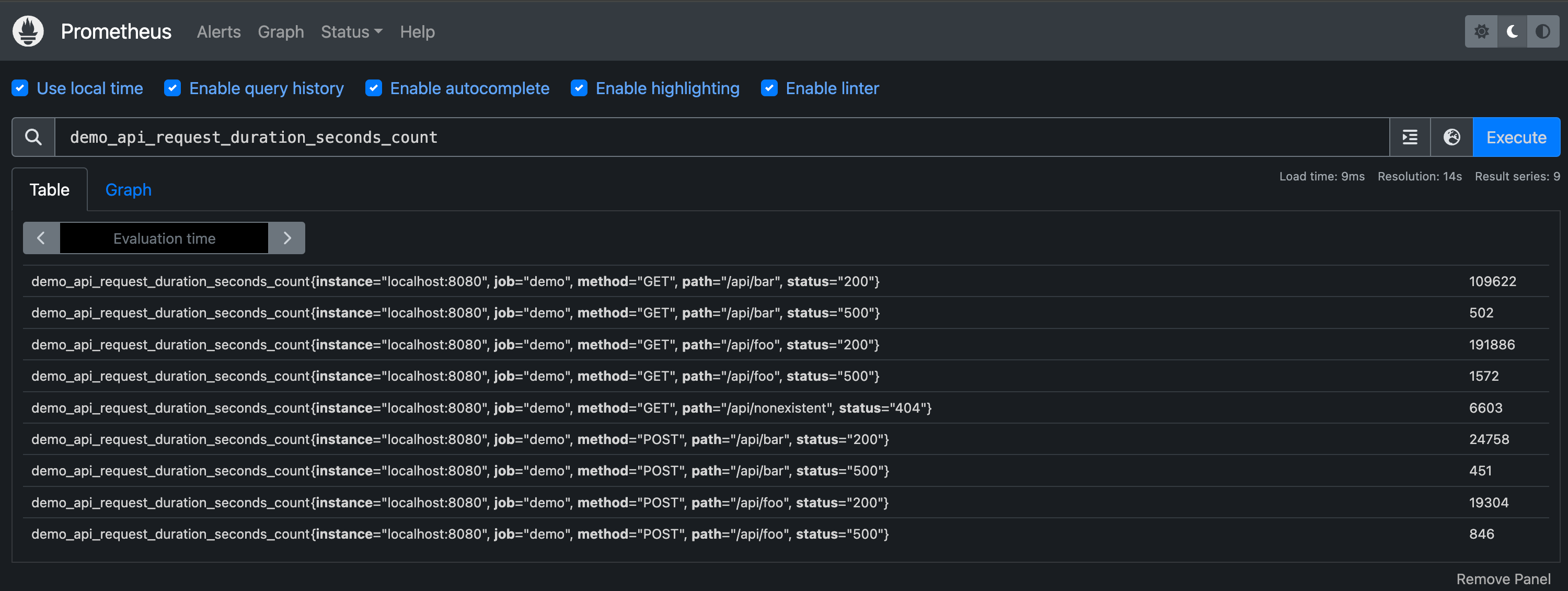
最简单的 PromQL 查询就是直接选择具有指定指标名称的序列,例如,以下查询将返回所有具有指标名称 demo_api_request_duration_seconds_count 的序列:
1 | |
该查询将返回许多具有相同指标名称的序列,但有不同的标签组合 instance、job、method、path 和 status 等。输出结果如下所示:
4.3.2 根据标签过滤
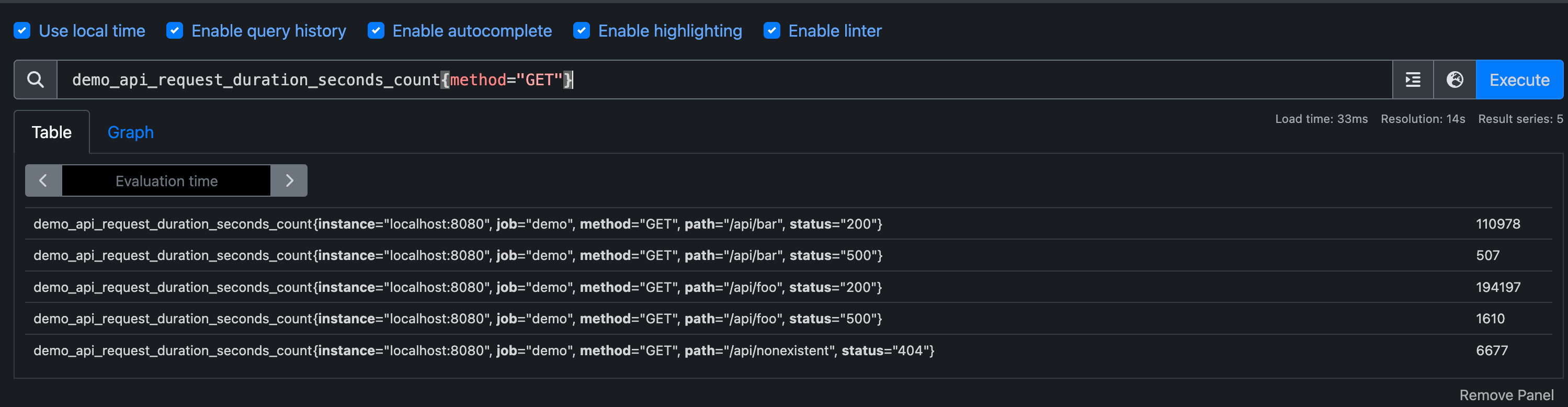
如果我们只查询 demo_api_request_duration_seconds_count 中具有 method="GET" 标签的那些指标序列,则可以在指标名称后用大括号加上这个过滤条件:
1 | |
此外我们还可以使用逗号来组合多个标签匹配器:
1 | |
上面将得到路径/api/foo并且状态码为200的指标序列数据:
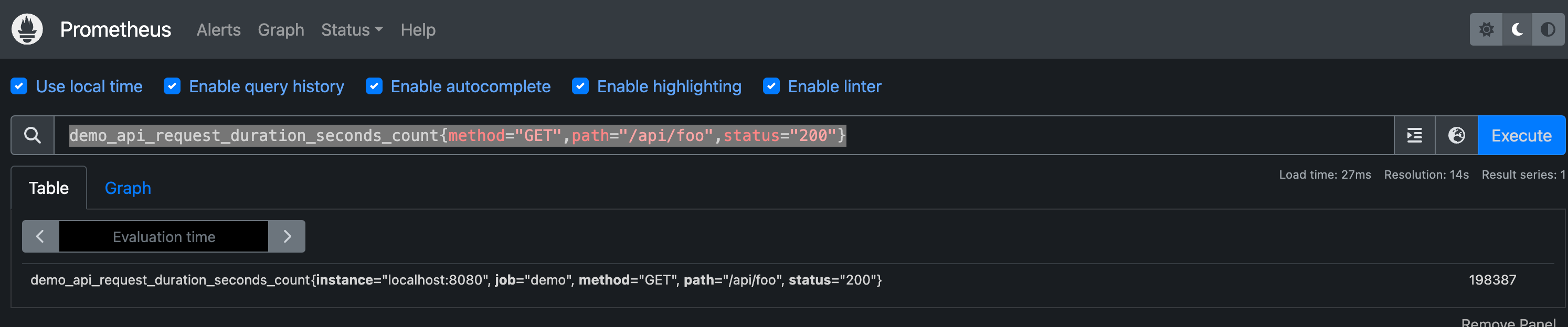
需要注意的是组合使用多个匹配条件的时候,是过滤所有条件都满足的时间序列。
除了相等匹配之外,Prometheus 还支持其他几种匹配器类型:
!=:不等于=~:正则表达式匹配!~:正则表达式不匹配
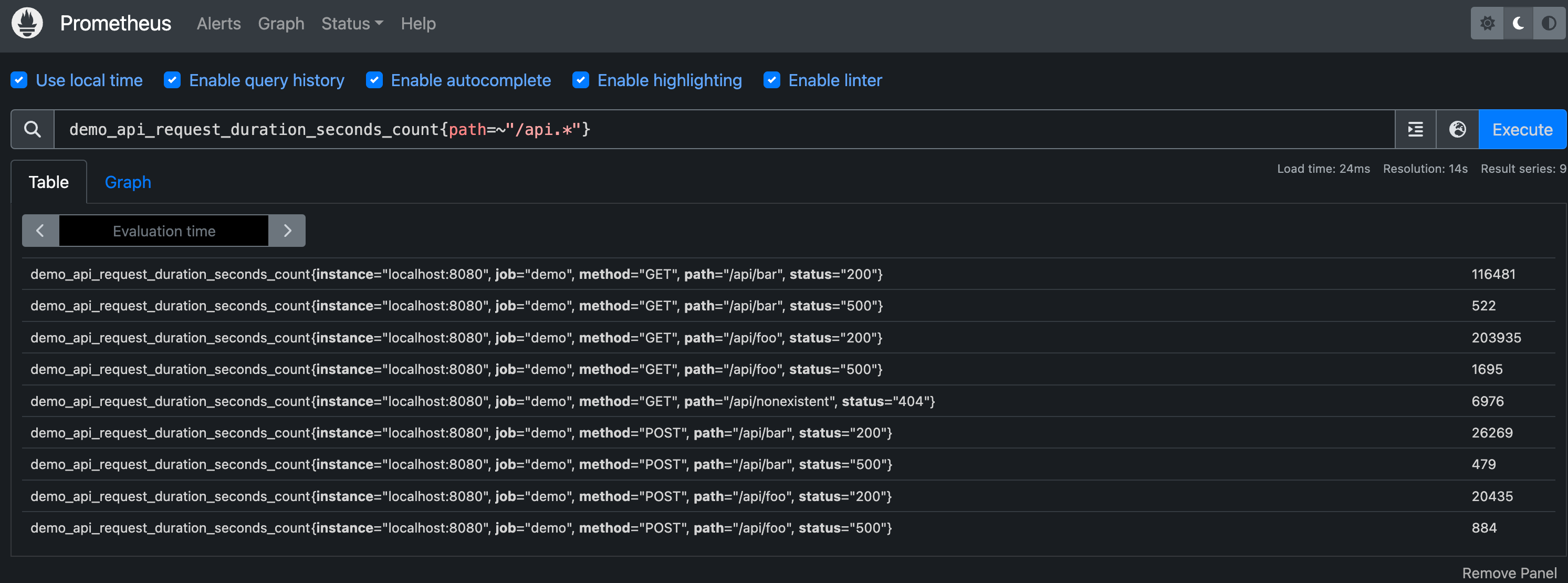
甚至我们还可以完全省略指标名称,比如直接查询所有 path 标签以 /api 开头的所有序列:
1 | |
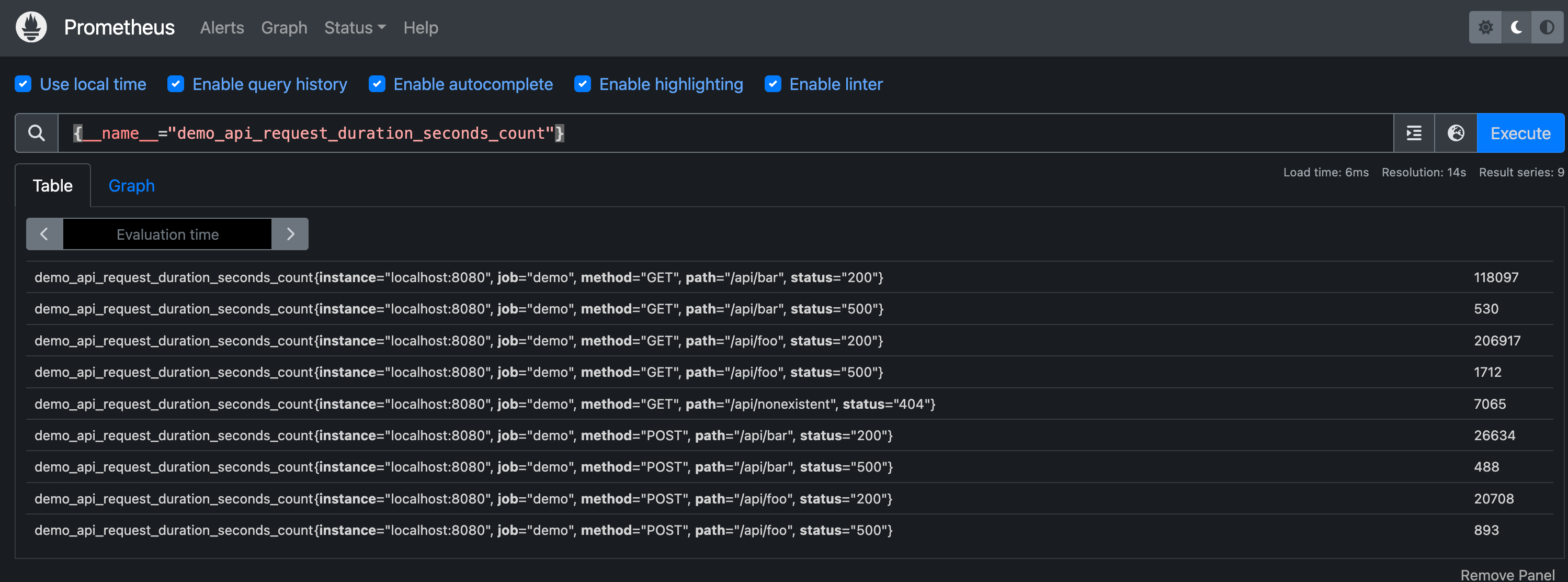
前面我们说过在 Prometheus 内部,指标名称本质上是一个名为 __name__ 的特性标签,所以查询 demo_api_request_duration_seconds_count 实际上和下面的查询方式是等效的:
1 | |
按上面的方法编写的选择器,可以得到一个瞬时向量,其中包含所有选定序列的单个最新值。事实上有些函数要求你不是传递一个单一的值,而是传递一个序列在一段时间范围内的值,也就是前面我们说的区间向量。这个时候我们可以通过附加一个[<数字><单位>]形式的持续时间指定符,将即时向量选择器改变为范围向量选择器(例如[5m]表示 5 分钟)。
比如要查询最近 5 分钟的可用内存,可以执行下面的查询语句:
1 | |
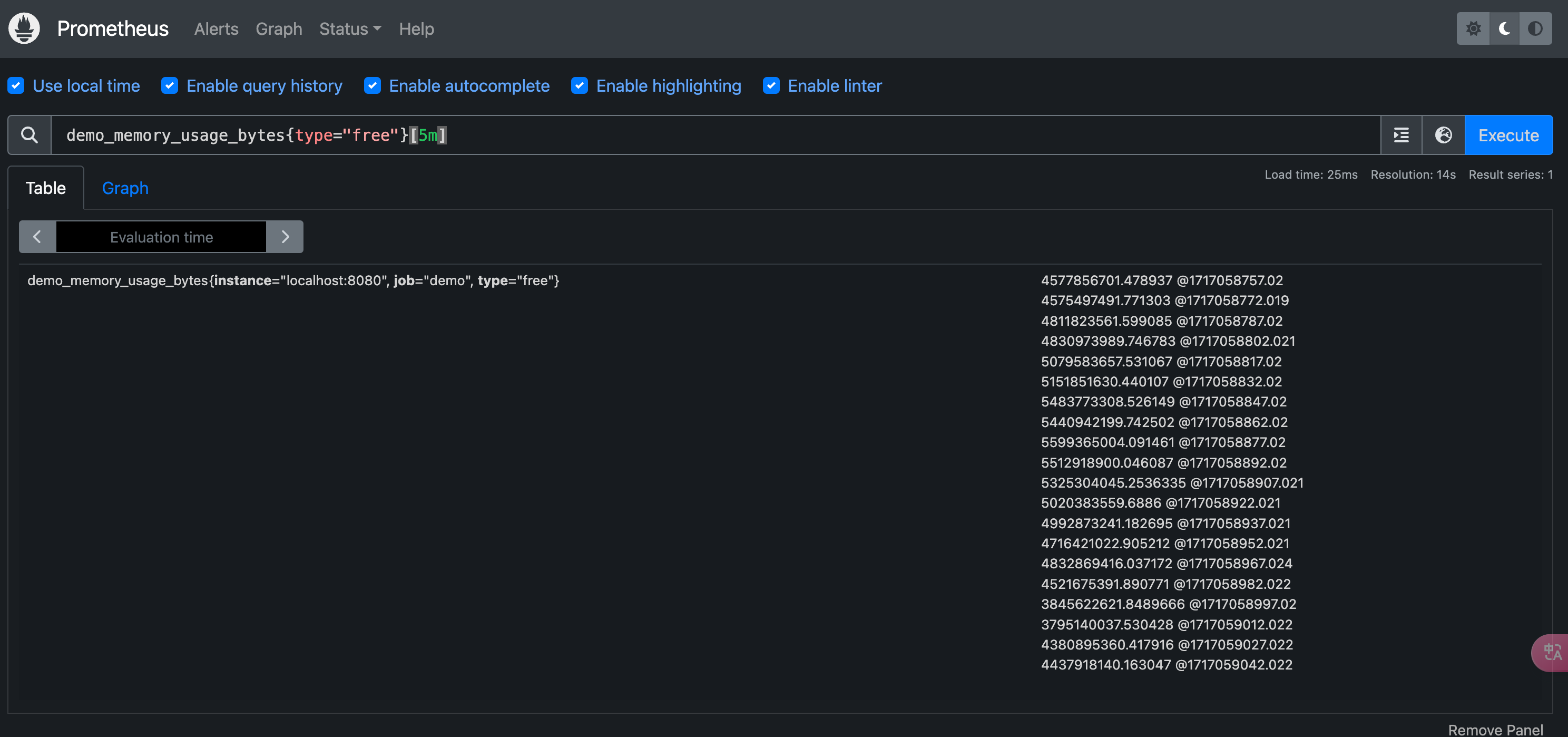
可以使用的有效的时间单位为:
ms-毫秒s-秒m- 分钟h- 小时d- 天y- 年
有时我们还需要以时移方式访问过去的数据,通常用来与当前数据进行比较。要将过去的数据时移到当前位置,可以使用 offset <duration> 修饰符添加到任何范围或即时序列选择器进行查询(例如 my_metric offset 5m 或 my_metric[1m] offset 7d)。
例如,要选择10分钟前的可用内存,可以使用下面的查询语句:
1 | |

4.4 变化率
通常来说直接绘制一个原始的 Counter 类型的指标数据用处不大,因为它们会一直增加,一般来说是不会去直接关心这个数值的,因为 Counter 一旦重置,总计数就没有意义了,比如我们直接执行下面的查询语句:
1 | |
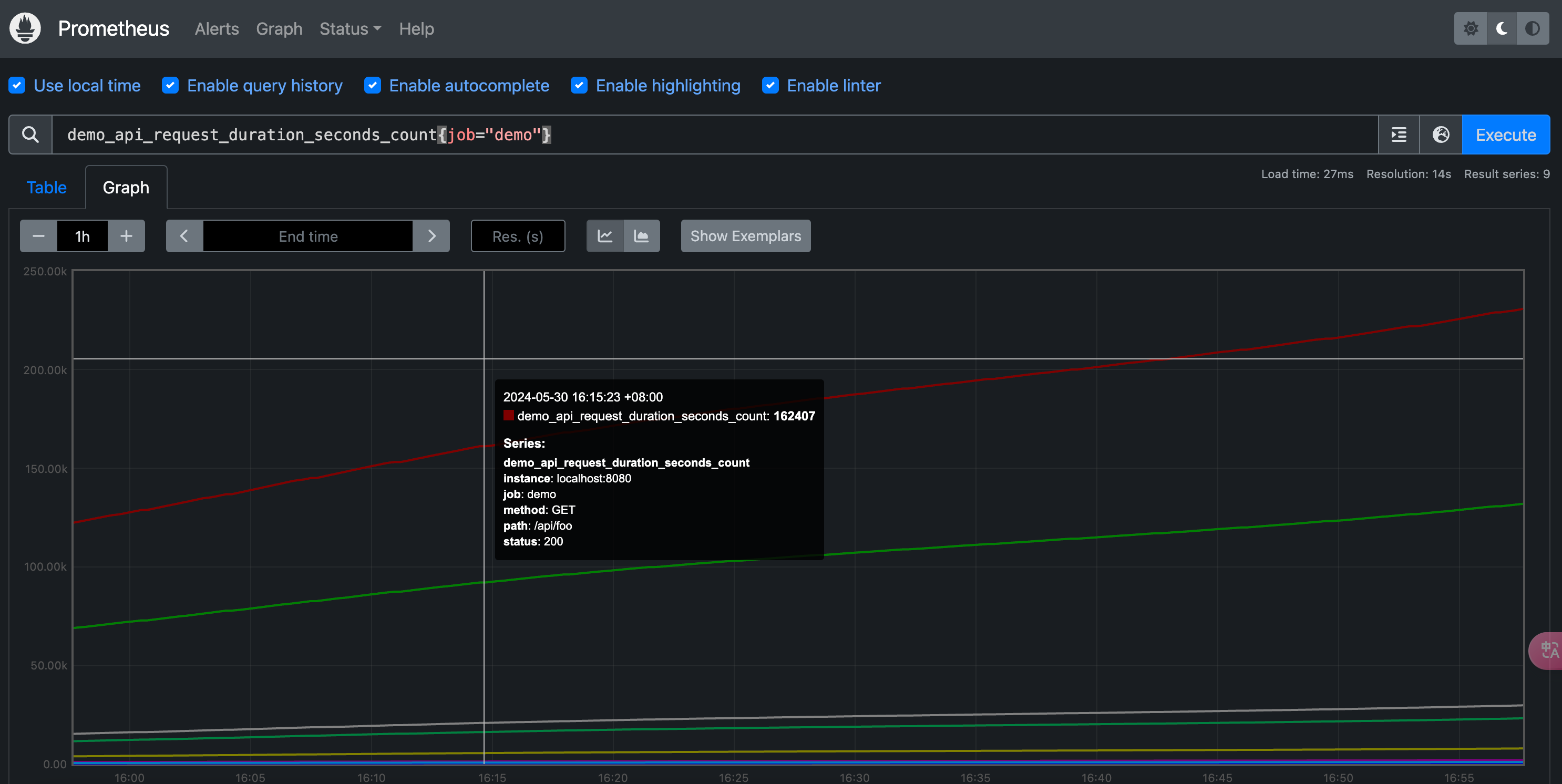
可以看到所有的都是不断增长的,一般来说我们更想要知道的是 Counter 指标的变化率,PromQL 提供了不同的函数来计算变化率。
4.4.1 rate
用于计算变化率的最常见函数是 rate(),rate() 函数用于计算在指定时间范围内计数器平均每秒的增加量。因为是计算一个时间范围内的平均值,所以我们需要在序列选择器之后添加一个范围选择器。
例如我们要计算 demo_api_request_duration_seconds_count 在最近五分钟内的每秒平均变化率,则可以使用下面的查询语句:
1 | |
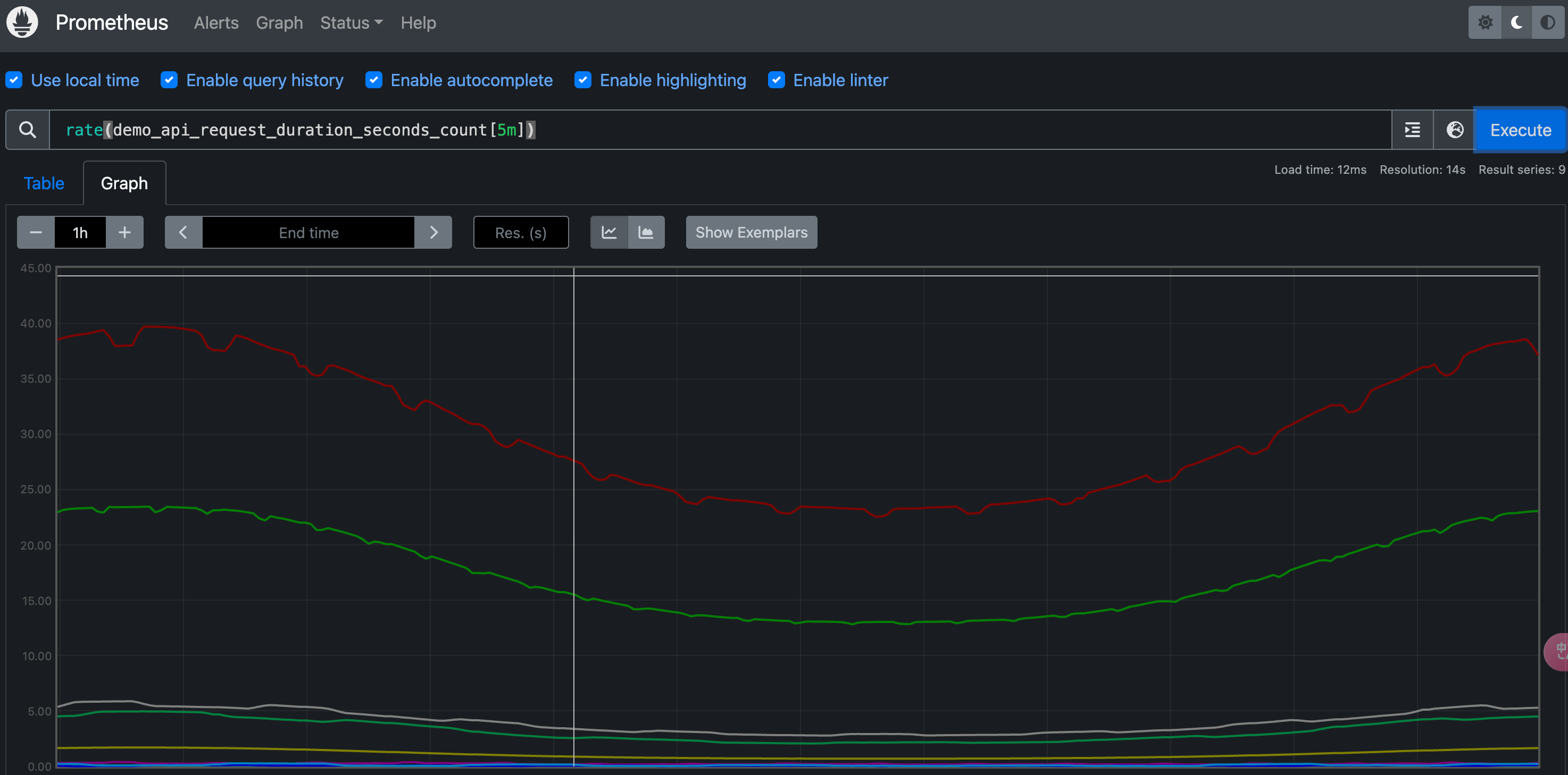
现在绘制的图形看起来显然更加有意义了,进行 rate 计算的时候是选择指定时间范围下的第一和最后一个样本进行计算,下图是表示的是计算方式:
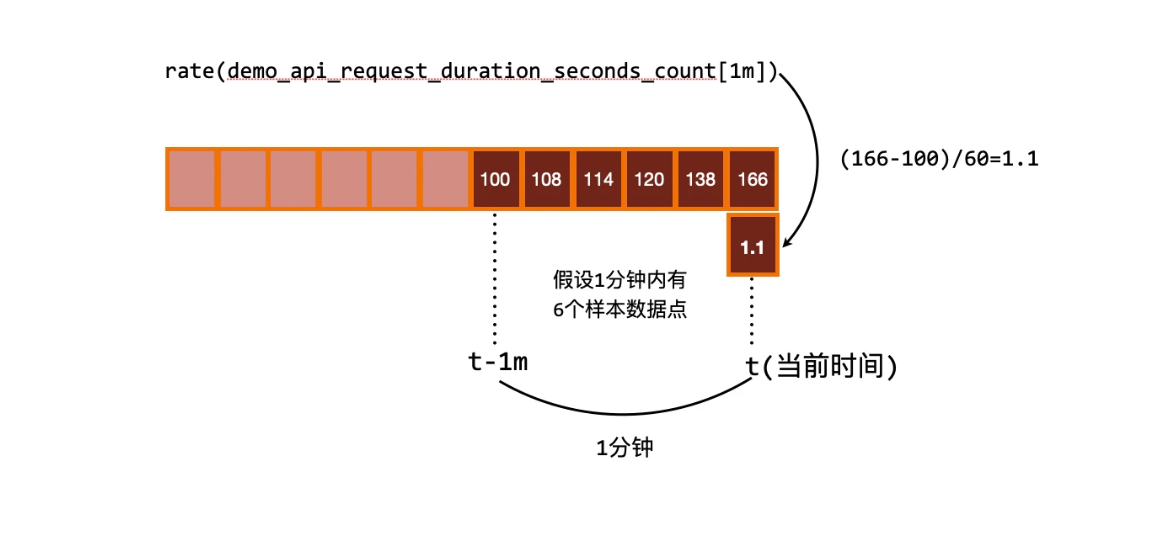
往往我们需要的是绘制一个图形,那么就需要进行区间查询,指定一个时间范围内进行多次计算,将结果串联起来形成一个图形:
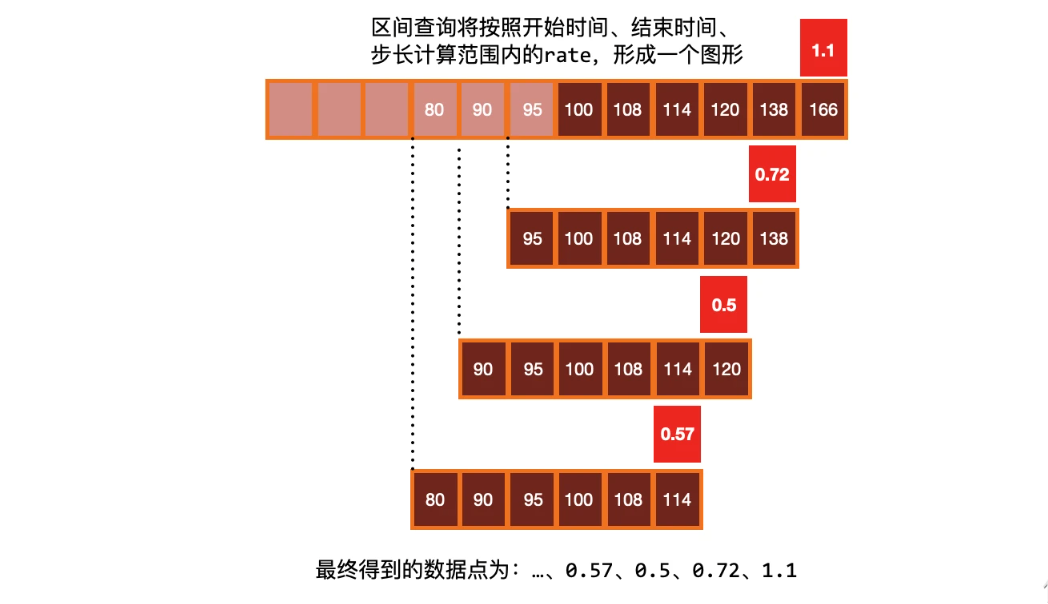
注意:当被抓取指标进的程重启时,Counter 指标可能会重置为 0,但 rate() 函数会自动处理这个问题,它会假设 Counter 指标的值只要是减少了就认为是被重置了,然后它可以调整后续的样本,例如,如果时间序列的值为 [5,10,4,6],则将其视为 [5,10,14,16]。
另外我们需要注意当把 rate() 与一个聚合运算符(例如 sum())或一个随时间聚合的函数(任何以 _over_time 结尾的函数)结合起来使用时,总是先取用 rate() 函数,然后再进行聚合,否则,当你的目标重新启动时,rate() 函数无法检测到 Counter 的重置。
4.4.2 irate
由于使用 rate 函数去计算样本的平均增长速率,容易陷入长尾问题当中,其无法反应在时间窗口内样本数据的突发变化。
例如,对于主机而言在 2 分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致 CPU 占用 100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
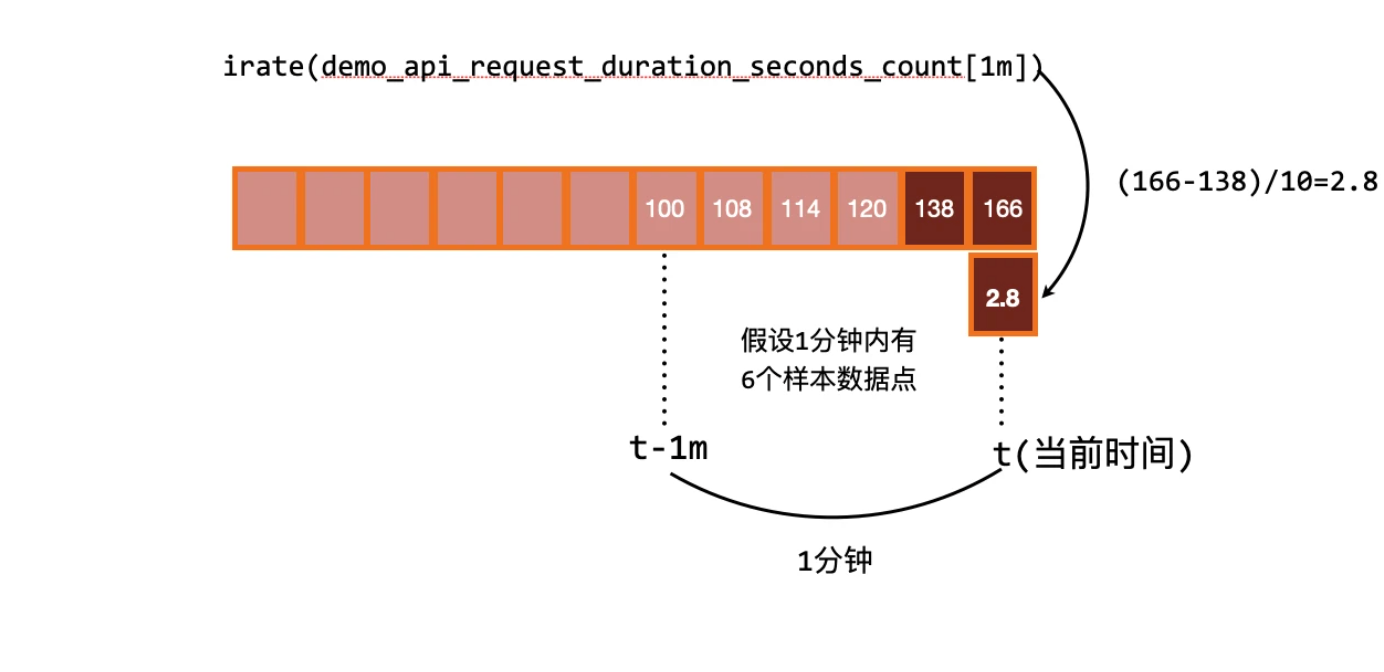
为了解决该问题,PromQL 提供了另外一个灵敏度更高的函数irate(v range-vector)。irate 同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。
irate 函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的长尾问题,并且体现出更好的灵敏度,通过 irate 函数绘制的图标能够更好的反应样本数据的瞬时变化状态。那既然是使用最后两个点计算,那为什么还要指定类似于 [1m] 的时间范围呢?这个 [1m] 不是用来计算的,irate 在计算的时候会最多向前在 [1m] 范围内找点,如果超过 [1m] 没有找到数据点,这个点的计算就放弃了。
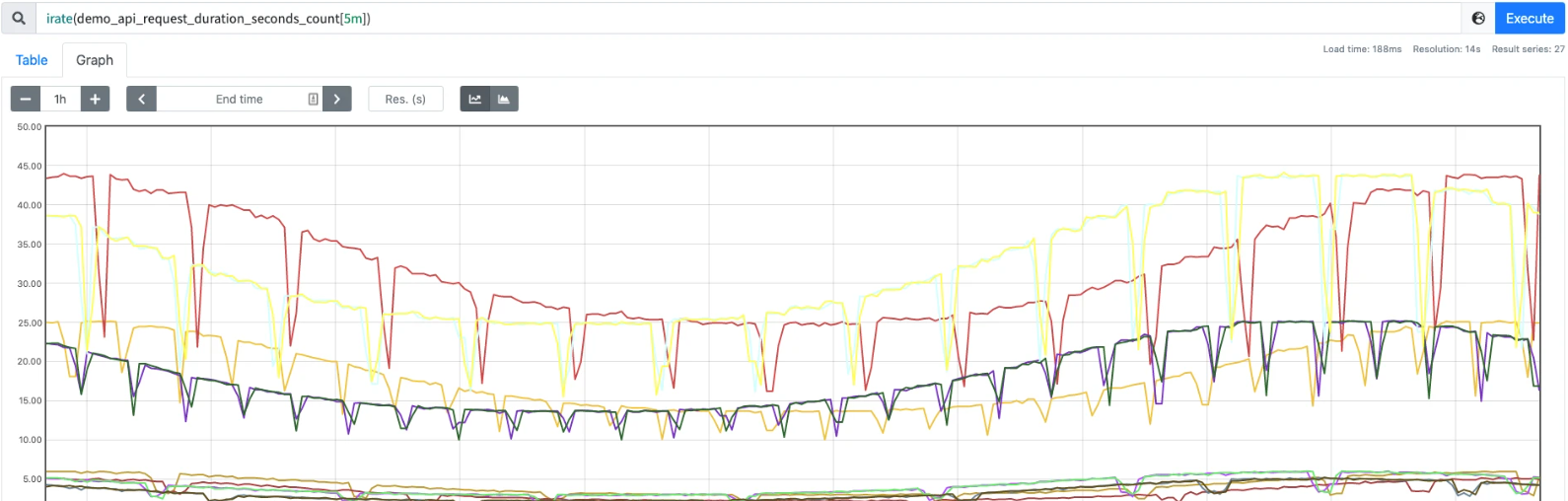
由于 rate() 提供了更平滑的结果,因此在长期趋势分析或者告警中更推荐使用 rate 函数,因为当速率只出现一个短暂的峰值时,不应该触发该报警。
使用 irate() 函数上面的表达式会出现一些短暂下降的图形:
4.4.3 increase
除了计算每秒速率,你还可以使用 increase() 函数查询指定时间范围内的总增量,它基本上相当于速率乘以时间范围选择器中的秒数:
1 | |
比如上面表达式的结果和使用 rate() 函数计算的结果整体图形趋势都是一样的,只是 Y 轴的数据不一样而已,一个表示数量,一个表示百分比。
还有另外一个 predict_linear() 函数可以预测一个 Gauge 类型的指标在未来指定一段时间内的值,例如我们可以根据过去 15 分钟的变化情况,来预测一个小时后的磁盘使用量是多少,可以用如下所示的表达式来查询:
1 | |
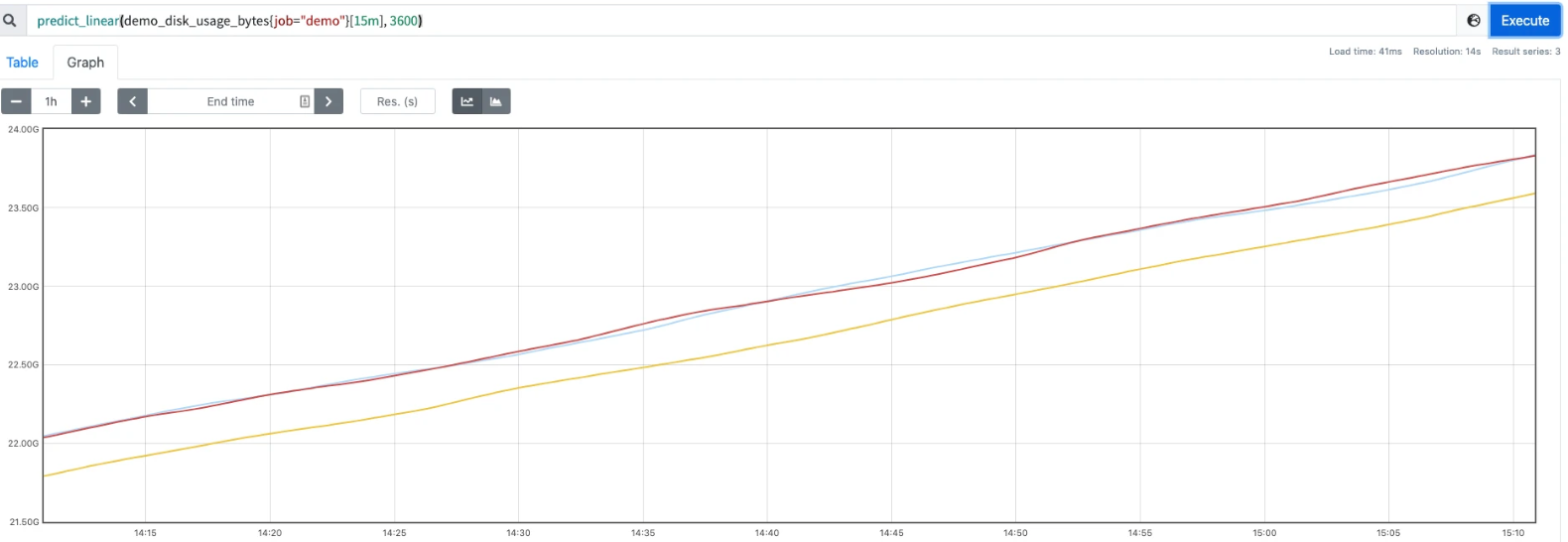
这个函数可以用于报警,告诉我们磁盘是否会在几个小时候内用完。
4.5 聚合
Prometheus 的时间序列数据是多维数据模型,经常就有根据各个维度进行汇总的需求。
4.5.1 基于标签聚合
例如我们想知道我们的 demo 服务每秒处理的请求数,那么可以将单个的速率相加就可以。
1 | |
可以得到如下所示的结果:
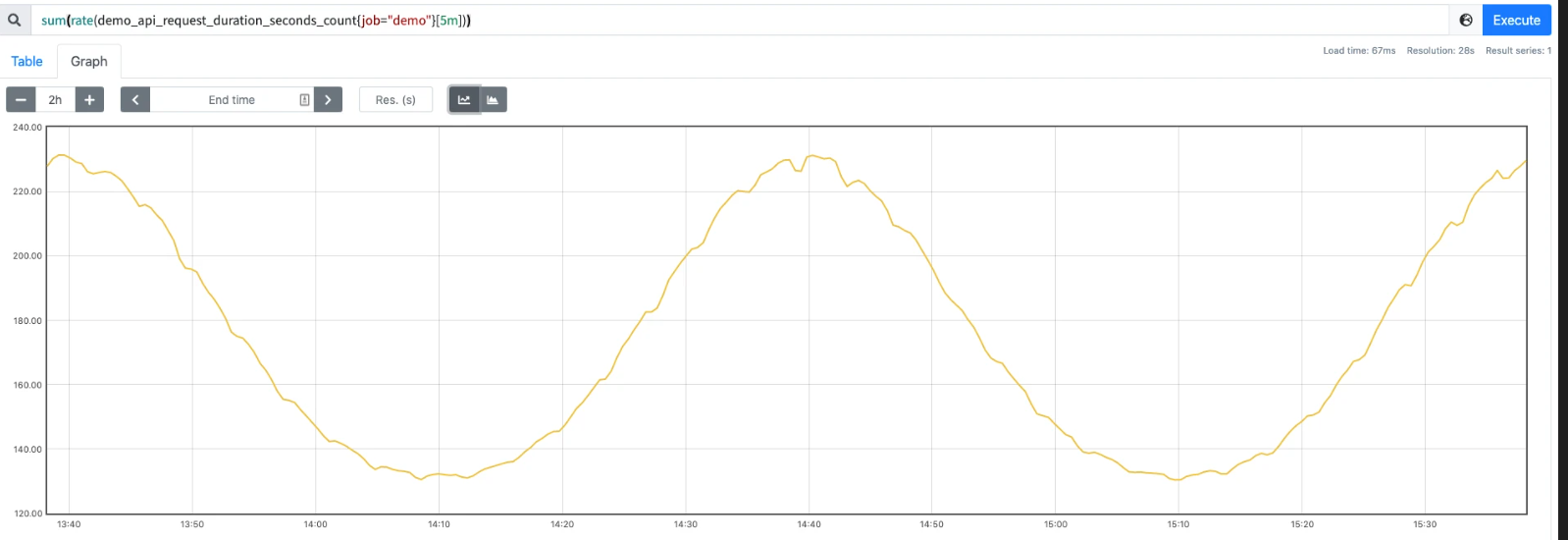
但是我们可以看到绘制出来的图形没有保留任何标签维度,一般来说可能我们希望保留一些维度,例如,我们可能更希望计算每个 instance 和 path 的变化率,但并不关心单个 method 或者 status 的结果,这个时候我们可以在 sum() 聚合器中添加一个 without() 的修饰符:
1 | |
上面的查询语句相当于用 by() 修饰符来保留需要的标签的取反操作:
1 | |
现在得到的 sum 结果是就是按照 instance、path、job 来进行分组去聚合的了:
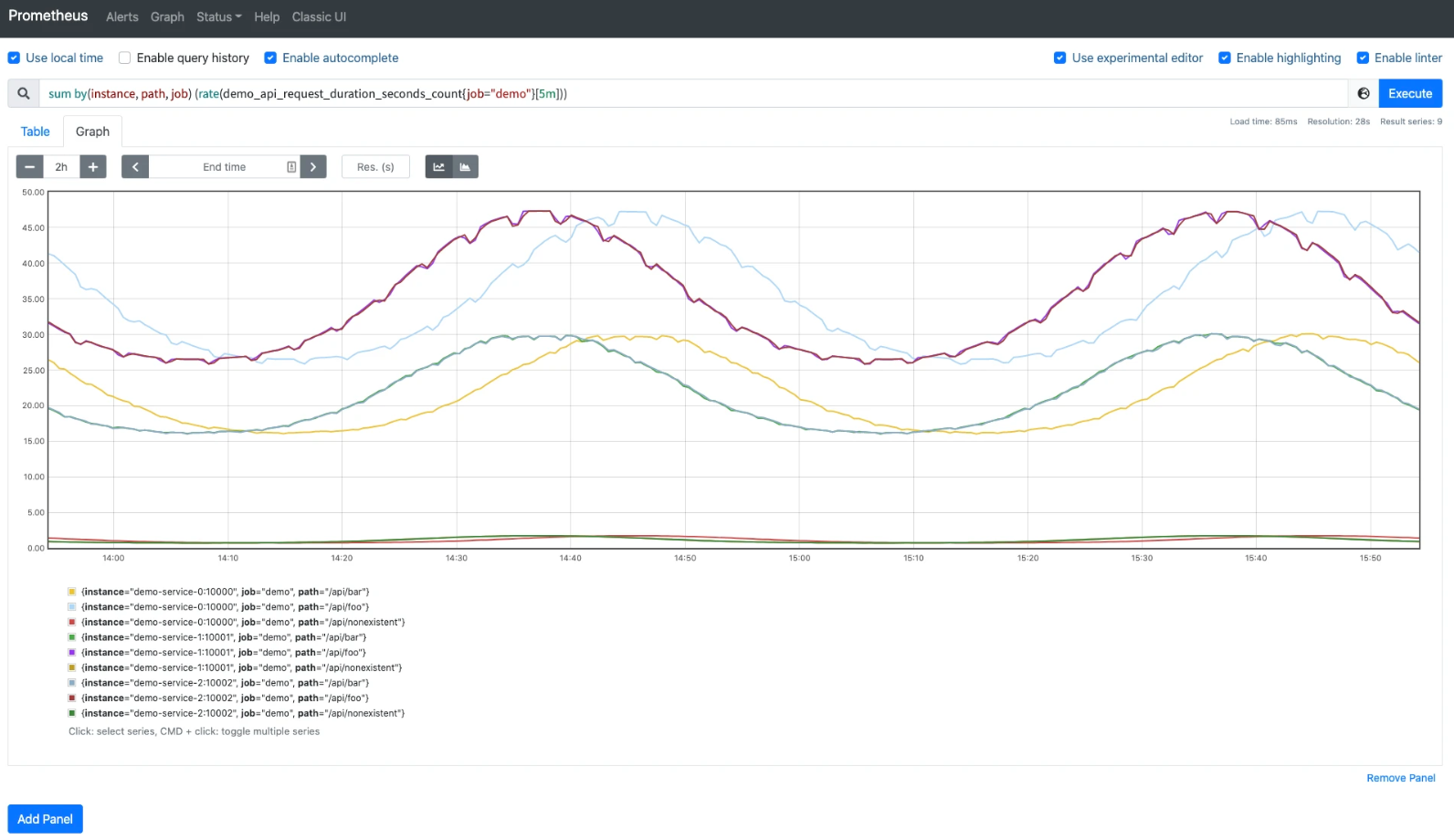
这里的分组概念和 SQL 语句中的分组去聚合就非常类似了。
除了 sum() 之外,Prometheus 还支持下面的这些聚合器:
sum():对聚合分组中的所有值进行求和min():获取一个聚合分组中最小值max():获取一个聚合分组中最大值avg():计算聚合分组中所有值的平均值stddev():计算聚合分组中所有数值的标准差stdvar():计算聚合分组中所有数值的标准方差count():计算聚合分组中所有序列的总数count_values():计算具有相同样本值的元素数量bottomk(k, ...):计算按样本值计算的最小的 k 个元素topk(k,...):计算最大的 k 个元素的样本值quantile(φ,...):计算维度上的 φ-分位数(0≤φ≤1)group(...):只是按标签分组,并将样本值设为 1。
4.5.2 基于时间聚合
前面我们已经学习了如何使用 sum()、avg() 和相关的聚合运算符从标签维度进行聚合,这些运算符在一个时间内对多个序列进行聚合,但是有时候我们可能想在每个序列中按时间进行聚合,例如想深入了解一个序列在一段时间内的最大值、最小值或者平均值。
为了基于时间来计算这些聚合,PromQL 提供了一些与标签聚合运算符类似的函数,但是在这些函数名前面附加了 _over_time():
avg_over_time(range-vector):区间向量内指标的平均值。min_over_time(range-vector):区间向量内指标的最小值。max_over_time(range-vector):区间向量内指标的最大值。sum_over_time(range-vector):区间向量内指标的求和。count_over_time(range-vector):区间向量内每个指标的样本数据个数。quantile_over_time(scalar, range-vector):区间向量内每个指标的样本数据值分位数。stddev_over_time(range-vector):区间向量内每个指标的总体标准差。stdvar_over_time(range-vector):区间向量内每个指标的总体标准方差。
例如,我们查询 demo 实例中使用的 goroutine 的原始数量,可以使用查询语句 go_goroutines{job="demo"},这会产生一些尖锐的峰值图:
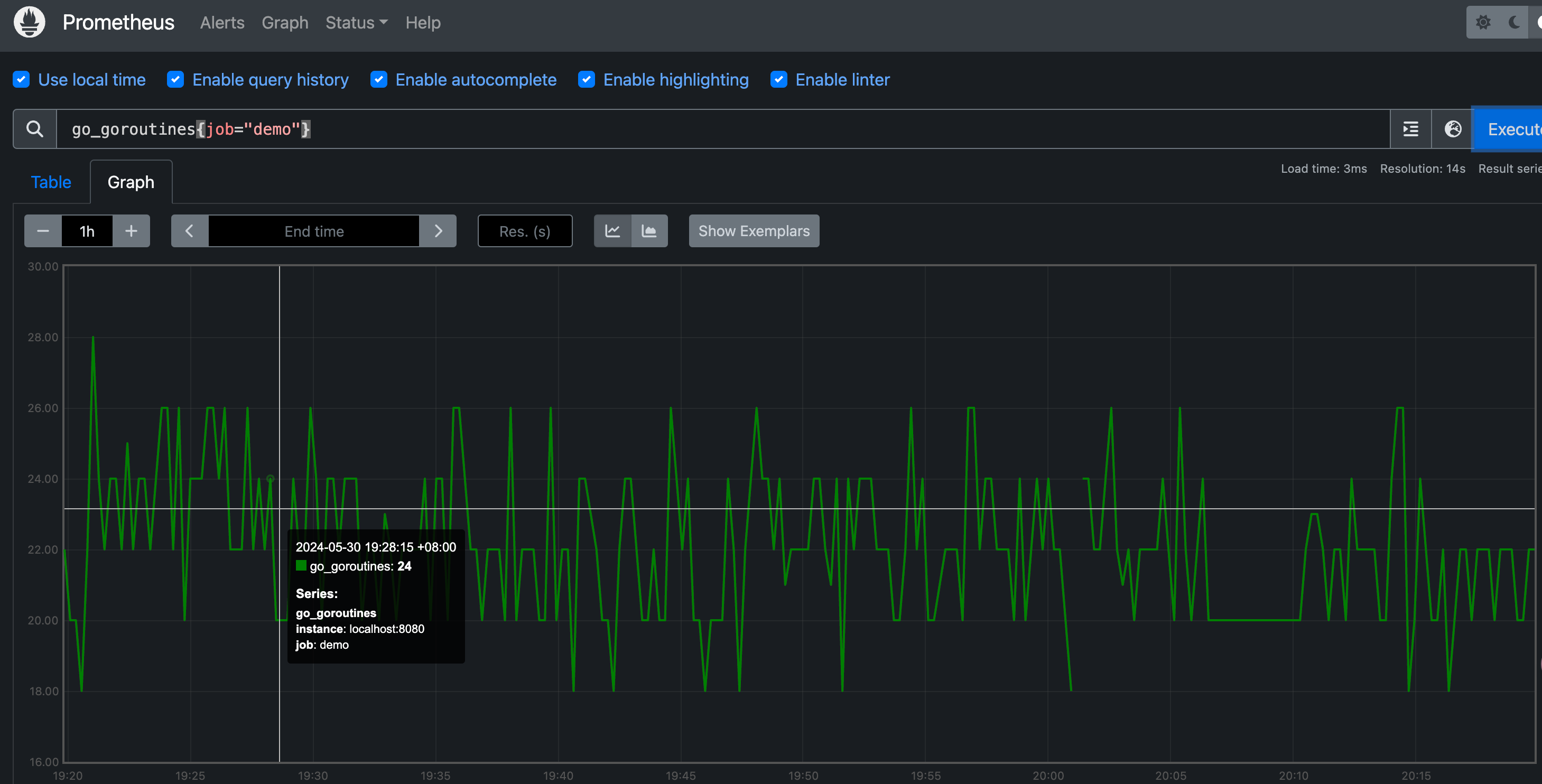
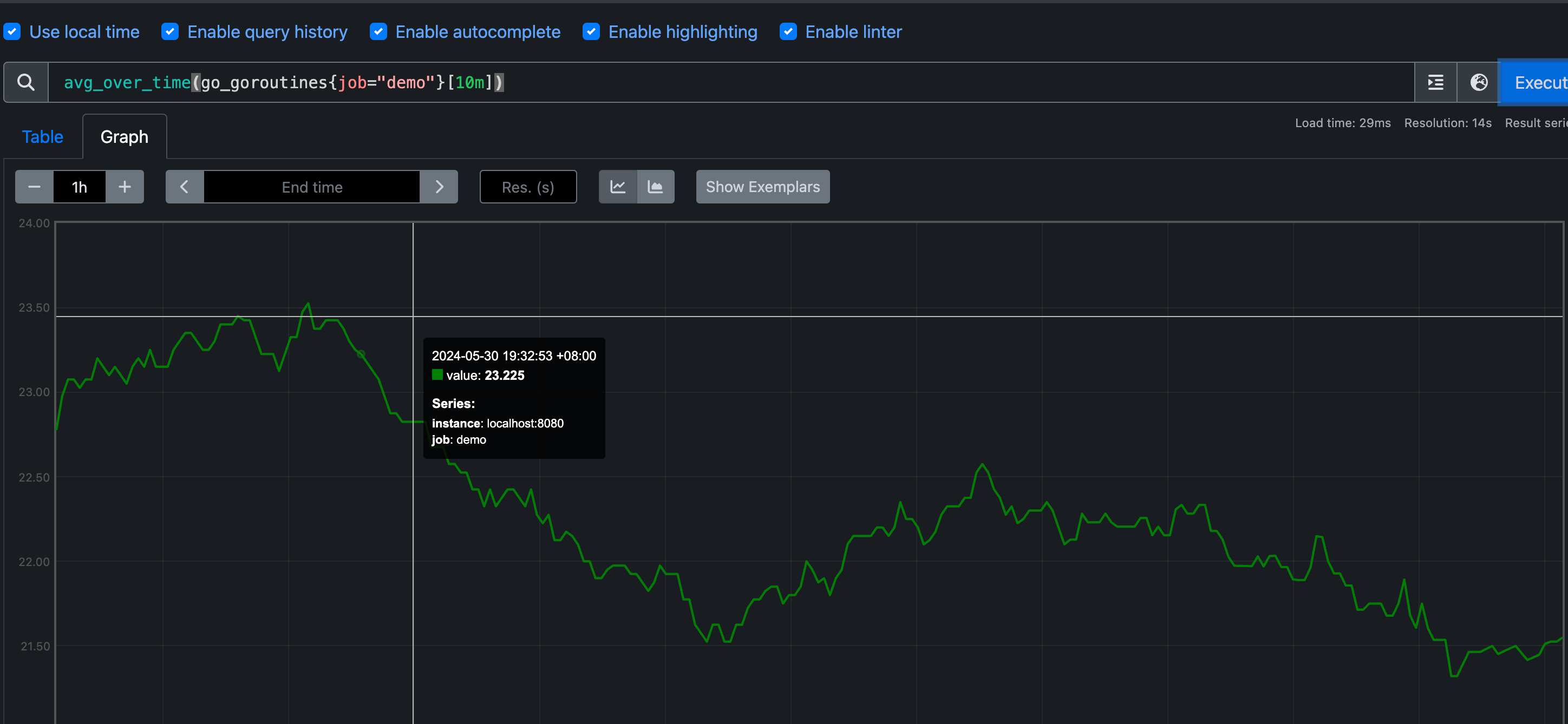
我们可以通过对图中的每一个点来计算 10 分钟内的 goroutines 数量进行平均来使图形更加平滑:
1 | |
4.5.3 子查询
上面所有的 _over_time() 函数都需要一个范围向量作为输入,通常情况下只能由一个区间向量选择器来产生,比如 my_metric[5m]。但是如果现在我们想使用例如 max_over_time() 函数来找出过去一天中 demo 服务的最大请求率应该怎么办呢?
请求率 rate 并不是一个我们可以直接选择时间的原始值,而是一个计算后得到的值,比如:
1 | |
如果我们直接将表达式传入 max_over_time() 并附加一天的持续时间查询的话就会产生错误:
1 | |
实际上 Prometheus 是支持子查询的,它允许我们首先以指定的步长在一段时间内执行内部查询,然后根据子查询的结果计算外部查询。子查询的表示方式类似于区间向量的持续时间,但需要冒号后添加了一个额外的步长参数:[<duration>:<resolution>]。
这样我们可以重写上面的查询语句,告诉 Prometheus 在一天的范围内评估内部表达式,步长分辨率为 15s:
1 | |
上面的语句相当于表示以 15s 为步长计算过去一天内的最大变化率。此外我们也可以省略冒号后的步长,在这种情况下,Prometheus 会使用配置的全局 evaluation_interval 参数进行评估内部表达式:
1 | |
这样就可以得到过去一天中 demo 服务最大的 5 分钟请求率,不过冒号仍然是需要的,以明确表示运行子查询。
4.6 运算
Prometheus 的查询语言支持基本的逻辑运算和算术运算。
4.6.1 算数运算符
在 Prometheus 系统中支持下面的二元算术运算符:
+加法-减法*乘法/除法%模^幂等
最简单的我们可以将一个数字计算当做一个 PromQL 语句,用于标量与标量之间计算,比如:
1 | |
可以得到如下所示的结果:

图形中返回的是一个值为 10 的标量(scalar)类型的数据。
二元运算同样适用于向量和标量之间,例如我们可以将一个字节数除以两次 1024 来转换为 MiB,如下查询语句:
1 | |
最后计算的结果就是 MiB 单位的了:

另外 PromQL 的一个强大功能就是可以让我们在向量与向量之间进行二元运算。
例如 demo_api_request_duration_seconds_sum 的数据包含了在 path、method、status 等不同维度上花费的总时间,指标 demo_api_request_duration_seconds_count 包含了上面同维度下的请求总次数。则我们可以用下面的语句来查询过去 5 分钟的平均请求持续时间:
1 | |
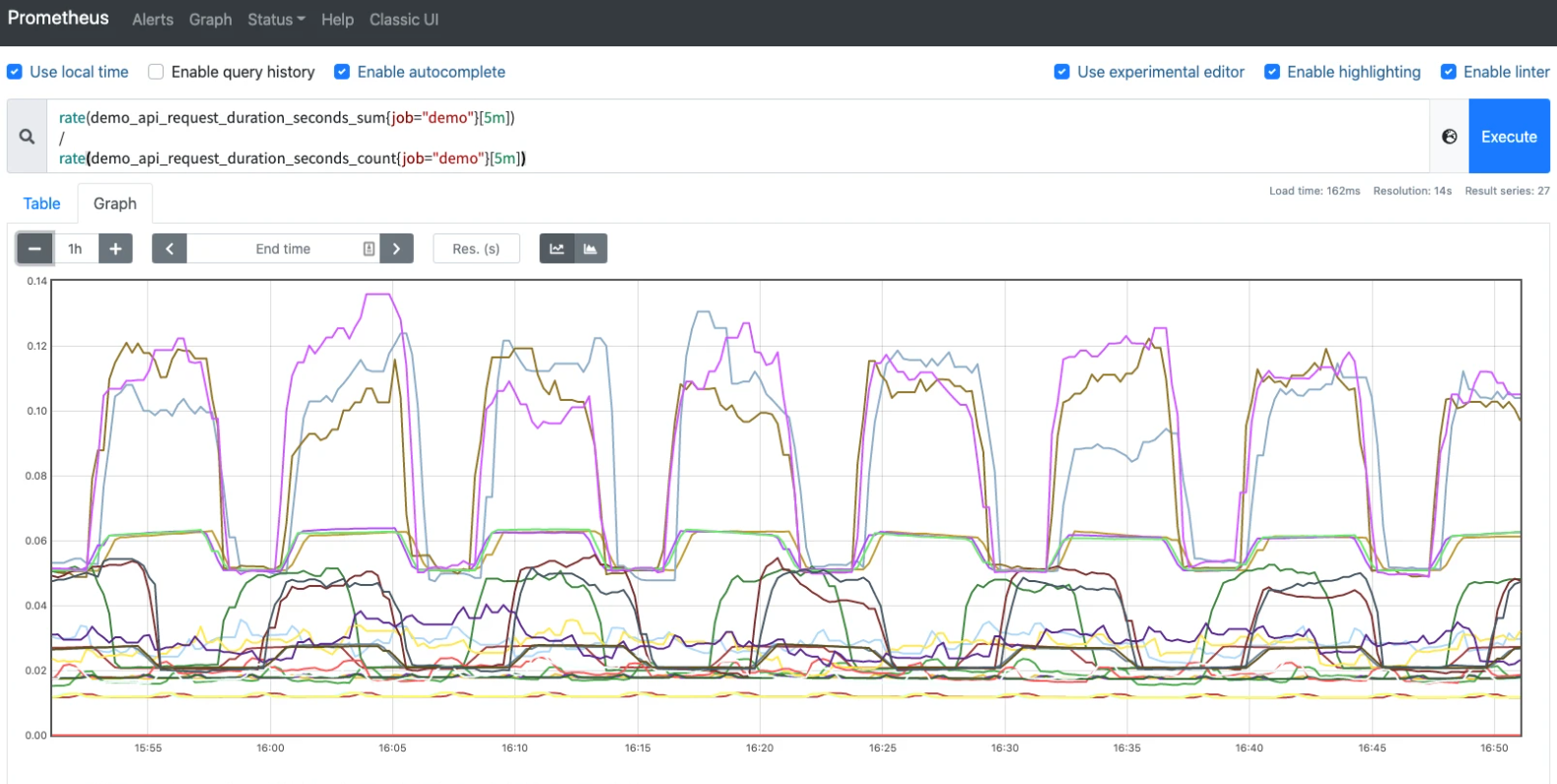
4.7 向量匹配
4.7.1 一对一
上面的示例其实就是一对一的向量匹配,但是一对一向量匹配也有两种情况,就是是否按照所有标签匹配进行计算,下图是匹配所有标签的情况:

图中我们两个指标 foo 和 bar,分别生成了 3 个序列:
1 | |
当我们执行查询语句 foo{} + bar{} 的时候,对于向量左边的每一个元素,操作符都会尝试在右边里面找到一个匹配的元素,匹配是通过比较所有的标签来完成的,没有匹配的元素会被丢弃,我们可以看到其中的 foo{color="green", size="medium"} 与 bar{color="green", size="xlarge"} 两个序列的标签是不匹配的,其余两个序列标签匹配,所以计算结果会抛弃掉不匹配的序列,得到的结果为其余序列的值相加。
上面例子中其中不匹配的标签主要是因为第二个 size 标签不一致造成的,那么如果我们在计算的时候忽略掉这个标签可以吗?如下图所示:

同样针对上面的两个指标,我们在进行计算的时候可以使用 on 或者 ignoring 修饰符来指定用于匹配的标签进行计算,由于示例中两边的标签都具有 color 标签,所以在进行计算的时候我们可以基于该标签(on (color))或者忽略其他的标签(ignoring (size))进行计算,这样得到的结果就是所以匹配的标签序列相加的结果,要注意结果中的标签也是匹配的标签。
4.7.2 一对多与多对一
上面讲解的一对一的向量计算是最直接的方式,在多数情况下,on 或者 ignoring 修饰符有助于是查询返回合理的结果,但通常情况用于计算的两个向量之间并不是一对一的关系,更多的是一对多或者多对一的关系,对于这种场景我们就不能简单使用上面的方式进行处理了。
多对一和一对多两种匹配模式指的是一侧的每一个向量元素可以与多侧的多个元素匹配的情况,在这种情况下,必须使用 group 修饰符:group_left 或者 group_right 来确定哪一个向量具有更高的基数(充当多的角色)。多对一和一对多两种模式一定是出现在操作符两侧表达式返回的向量标签不一致的情况,因此同样需要使用 ignoring 和 on 修饰符来排除或者限定匹配的标签列表。
例如 demo_num_cpus 指标告诉我们每个实例的 CPU 核心数量,只有 instance 和 job 这两个标签维度。

而 demo_cpu_usage_seconds_total 指标则多了一个 mode 标签的维度,将每个 mode 模式(idle、system、user)的 CPU 使用情况分开进行了统计。
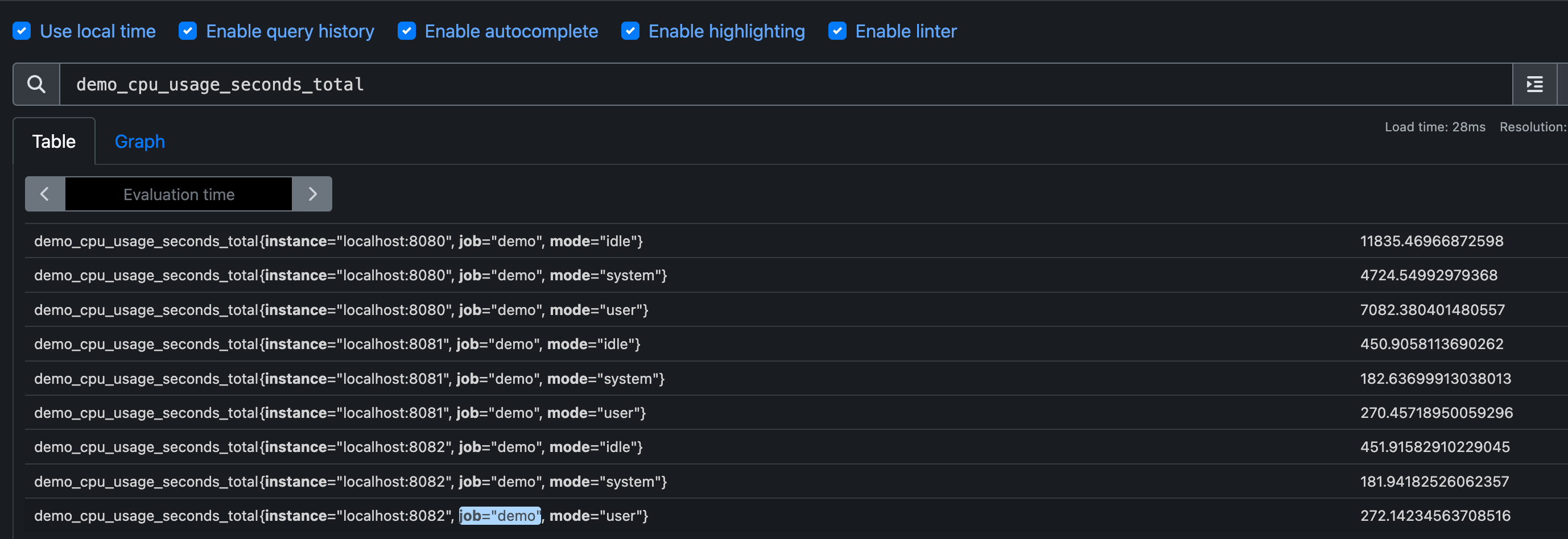
如果要计算每个模式的 CPU 使用量除以核心数,我们需要告诉除法运算符按照 demo_cpu_usage_seconds_total 指标上额外的 mode 标签维度对结果进行分组,我们可以使用 group_left(表示左边的向量具有更高的基数)修饰符来实现。同时,我们还需要通过 on() 修饰符明确将所考虑的标签集减少到需要匹配的标签列表:
1 | |
上面的表达式可以正常得到结果:
除了 on() 之外,还可以使用相反的 ignoring() 修饰符,可以用来将一些标签维度从二元运算操作匹配中忽略掉,如果在操作符的右侧有额外的维度,则应该使用 group_right(表示右边的向量具有更高的基数)修饰符。
比如上面的查询语句同样可以用 ignoring 关键字来完成:
1 | |
得到的结果和前面用 on() 查询的结果是一致的。
4.8 直方图
在这一节中,我们将学习直方图指标,了解如何根据这些指标来计算分位数。Prometheus 中的直方图指标允许一个服务记录一系列数值的分布。直方图通常用于跟踪请求的延迟或响应大小等指标值,当然理论上它是可以跟踪任何根据某种分布而产生波动数值的大小。Prometheus 直方图是在客户端对数据进行的采样,它们使用的一些可配置的(例如延迟)bucket 桶对观察到的值进行计数,然后将这些 bucket 作为单独的时间序列暴露出来。
下图是一个非累积直方图的例子:
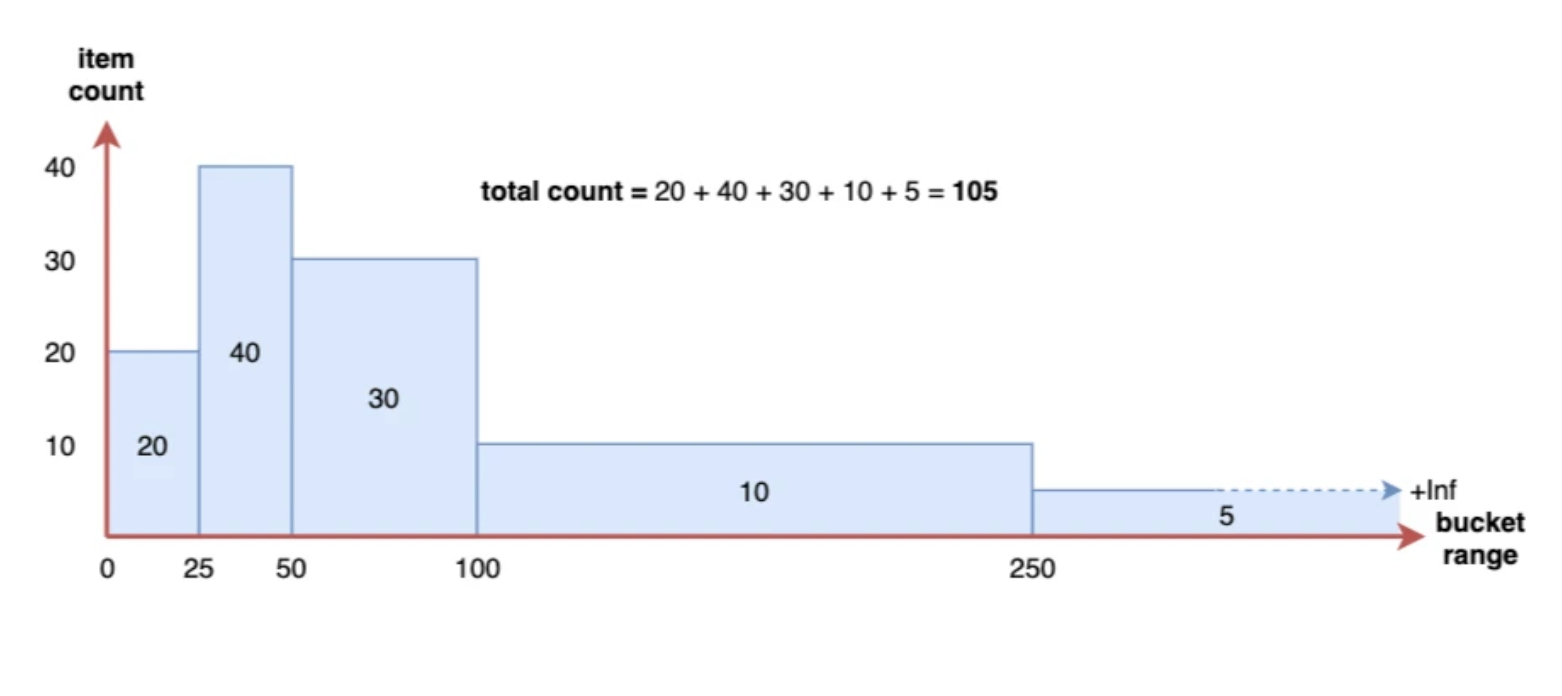
在 Prometheus 内部,直方图被实现为一组时间序列,每个序列代表指定桶的计数(例如 10ms 以下的请求数、25ms 以下的请求数、50ms 以下的请求数等)。在 Prometheus 中每个 bucket 桶的计数器是累加的,这意味着较大值的桶也包括所有低数值的桶的计数。在作为直方图一部分的每个时间序列上,相应的桶由特殊的 le 标签表示。le 代表的是小于或等于。
与上面相同的直方图在 Prometheus 中的累积直方图如下所示:
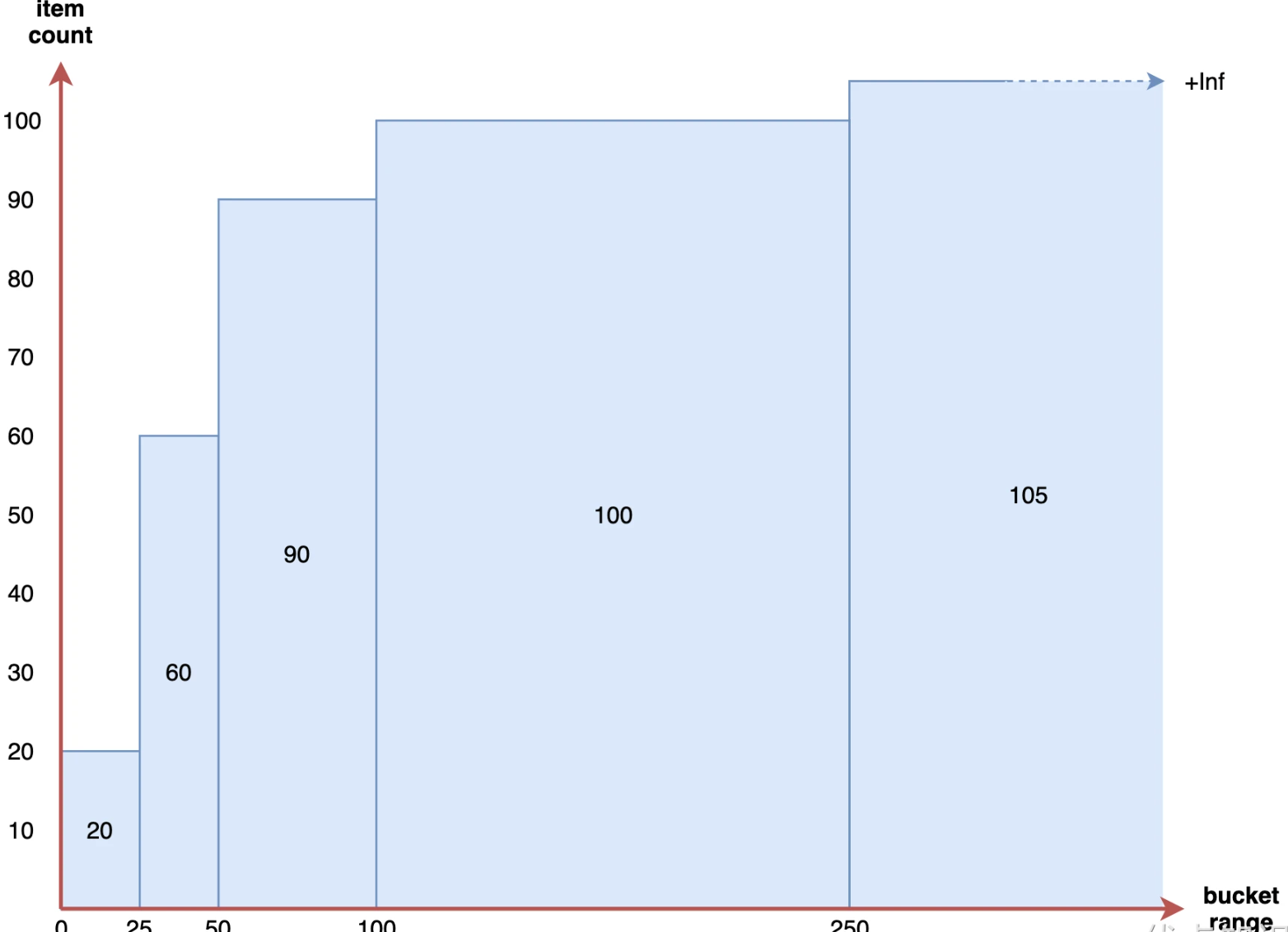
我们在演示的 demo 服务中暴露了一个直方图指标 demo_api_request_duration_seconds_bucket,用于跟踪 API 请求时长的分布,由于这个直方图为每个跟踪的维度导出了 26 个 bucket,因此这个指标有很多时间序列。我们可以先来看下来自一个服务实例的一个请求维度组合的直方图,查询语句如下所示:
1 | |
正常我们可以看到 26 个序列,每个序列代表一个 bucket,由 le 标签标识:
直方图可以帮助我们了解这样的问题,比如 “我有多少个请求超过了 100ms 的时间?” (当然需要直方图中配置了一个以 100ms 为边界的桶),又比如 **”我 99%的请求是在多少延迟下完成的?”**,这类数值被称为百分位数或分位数。在 Prometheus 中这两个术语几乎是可以通用,只是百分位数指定在 0-100 范围内,而分位数表示在 0 和 1 之间,所以第 99 个百分位数相当于目标分位数 0.99。
如果你的直方图桶粒度足够小,那么我们可以使用 histogram_quantile(φ scalar, b instant-vector) 函数用于计算历史数据指标一段时间内的分位数。该函数将目标分位数 (0 ≤ φ ≤ 1) 和直方图指标作为输入,就是大家平时讲的 pxx,p50 就是中位数,参数 b 一定是包含 le 这个标签的瞬时向量,不包含就无从计算分位数了,但是计算的分位数是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的,预估的准确度取决于 bucket 区间划分的粒度,粒度越大,准确度越低。
回到我们的演示服务,我们可以尝试计算所有维度在所有时间内的第 90 个百分位数,也就是 90% 的请求的持续时间。
1 | |
但是这个查询方式是有一点问题的,当单个服务实例重新启动时,bucket 的 Counter 计数器会被重置,而且我们常常想看看现在的延迟是多少(比如在过去 5 分钟内),而不是整个时间内的指标。我们可以使用 rate() 函数应用于底层直方图计数器来实现这一点,该函数会自动处理 Counter 重置,又可以只计算每个桶在指定时间窗口内的平均增长。
我们可以这样去计算过去 5 分钟内第 90 个百分位数的 API 延迟:
1 | |
这个查询就好很多了。
这个查询会显示每个维度(job、instance、path、method 和 status)的第 90 个百分点,但是我们可能对单独的这些维度并不感兴趣,想把他们中的一些指标聚合起来,这个时候我们可以在查询的时候使用 Prometheus 的 sum 运算符与 histogram_quantile() 函数结合起来,计算出聚合的百分位,假设在我们想要聚合的维度之间,直方图桶的配置方式相同(桶的数量相同,上限相同),我们可以将不同维度之间具有相同 le 标签值的桶加在一起,得到一个聚合直方图。然后,我们可以使用该聚合直方图作为 histogram_quantile() 函数的输入。
下面的查询计算了第 90 个百分位数的延迟,但只按 job、instance 和 path 维度进行聚合结果:
4.9 集合操作
有的时候我们需要过滤或将一组时间序列与另一组时间序列进行合并,Prometheus 提供了 3 个在瞬时向量之间操作的集合运算符。
and(集合交集):比如对较高错误率触发报警,但是只有当对应的总错误率超过某个阈值的时候才会触发报警or(集合并集):对序列进行并集计算unless(除非):比如要对磁盘空间不足进行告警,除非它是只读文件系统。

对于 and 运算符,如果找到一个匹配的,左边的序列就会成为输出结果的一部分,如果右边没有匹配的序列,则不会输出任何结果。
例如我们想筛选出第 90 个百分位延迟高于 50ms 的所有 HTTP 端点,但只针对每秒收到多个请求的维度组合,查询方式如下所示:
1 | |
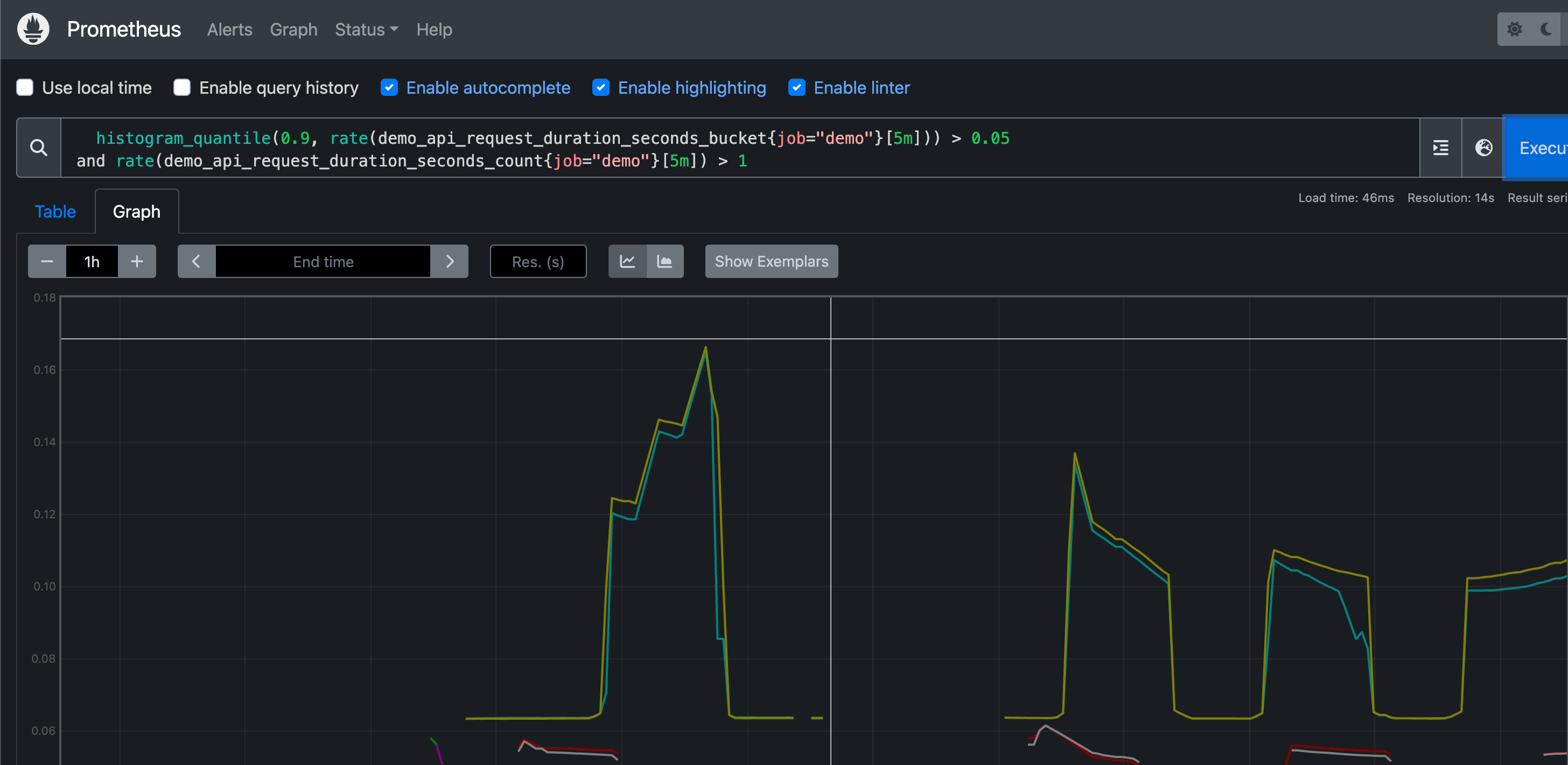
有的时候我们也需要对两组时间序列进行合并操作,而不是交集,这个时候我们可以使用 or 集合运算符,产生的结果是运算符左侧的序列,加上来自右侧但左侧没有匹配标签集的时间序列。比如我们要列出所有低于 10 或者高于 30 的请求率,则可以用下面的表达式来查询:
1 | |
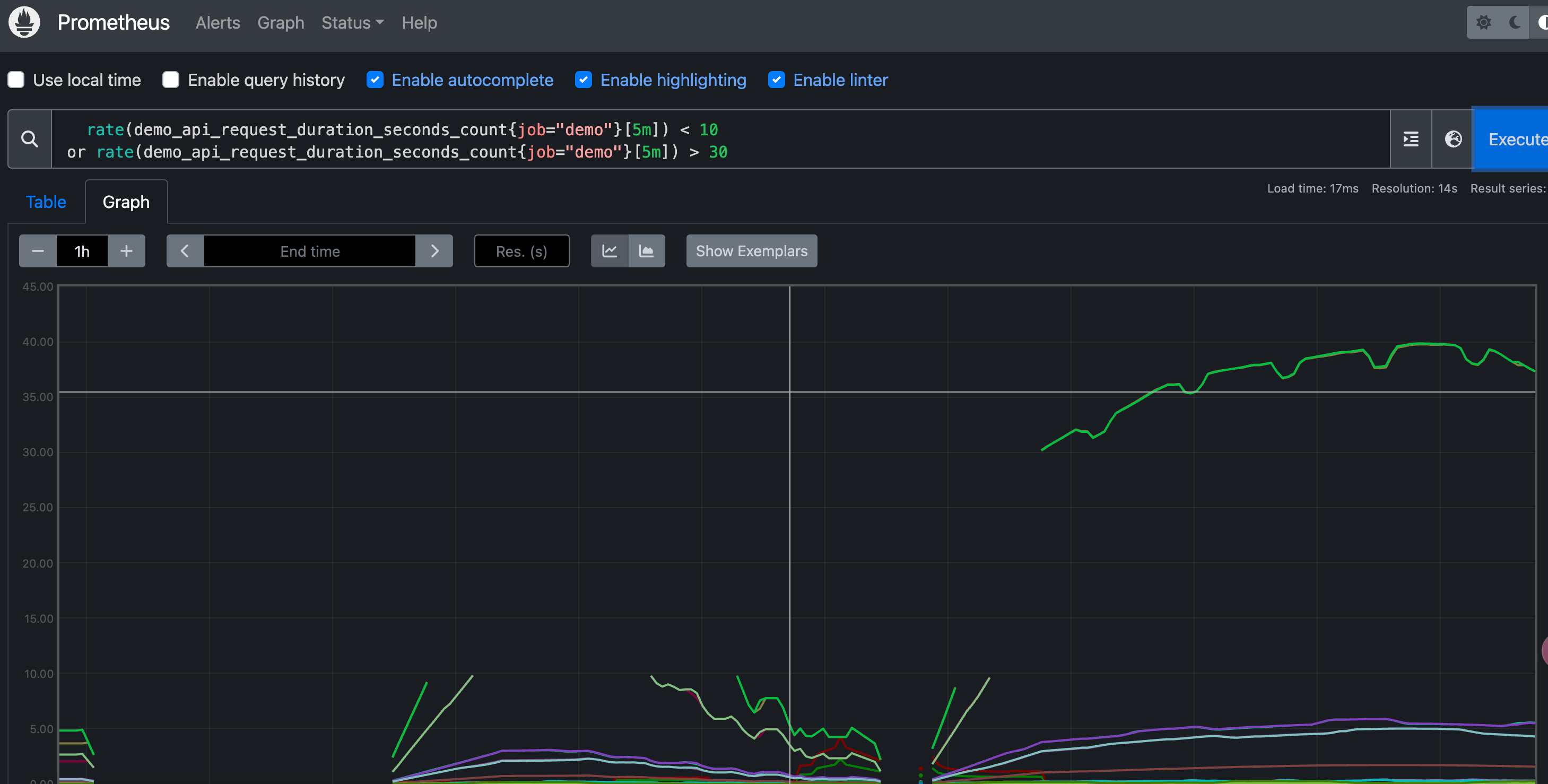
我们可以看到在图中使用值过滤器和集合操作会导致时间序列在图中有断点现象,这取决于他们在图中的时间间隔下是否能够与过滤器进行匹配,所以一般情况下,我们建议只在告警规则中使用这种过滤操作。
还有一个 unless 操作符,它只会保留左边的时间序列,如果右边不存在相等的标签集合的话。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!