Kubernetes监控
1. 安装
由于 Prometheus 是 Golang 编写的程序,所以要安装的话也非常简单,只需要将二进制文件下载下来直接执行即可,前往地址:https://prometheus.io/download 下载最新版本即可。
Prometheus 是通过一个 YAML 配置文件来进行启动的,如果我们使用二进制的方式来启动的话,可以使用下面的命令:
1 | |
其中 prometheus.yml 文件的基本配置如下:
1 | |
上面这个配置文件中包含了 3 个模块:global、rule_files 和 scrape_configs。
global模块控制Prometheus Server的全局配置:scrape_interval:表示 prometheus 抓取指标数据的频率,默认是 15s,我们可以覆盖这个值evaluation_interval:用来控制评估规则的频率,prometheus 使用规则产生新的时间序列数据或者产生警报rule_files:指定了报警规则所在的位置,prometheus 可以根据这个配置加载规则,用于生成新的时间序列数据或者报警信息,当前我们没有配置任何报警规则。scrape_configs用于控制 prometheus 监控哪些资源。
由于 prometheus 通过 HTTP 的方式来暴露的它本身的监控数据,prometheus 也能够监控本身的健康情况。在默认的配置里有一个单独的 job,叫做 prometheus,它采集 prometheus 服务本身的时间序列数据。这个 job 包含了一个单独的、静态配置的目标:监听 localhost 上的 9090 端口。prometheus 默认会通过目标的 /metrics 路径采集 metrics。所以,默认的 job 通过 URL:http://localhost:9090/metrics 采集 metrics。收集到的时间序列包含 prometheus 服务本身的状态和性能。如果我们还有其他的资源需要监控的话,直接配置在 scrape_configs 模块下面就可以了。
1.1 创建名称空间
由于我们这里是要运行在 Kubernetes 集群中,所以我们直接用 Docker 镜像的方式运行。为了方便管理,我们将监控相关的所有资源对象都安装在 monitor 这个 namespace 下面,没有的话可以提前创建。
1 | |
1.2 创建prometheus的ConfigMap
为了能够方便的管理配置文件,我们这里将 prometheus.yml 文件用 ConfigMap 的形式进行管理:
1 | |
1.3 创建prometheus的pod资源
配置文件创建完成了,以后如果我们有新的资源需要被监控,我们只需要将上面的 ConfigMap 对象更新即可。现在我们来创建 prometheus 的 Pod 资源:
prometheus-rbac.yaml
由于 prometheus 可以访问 Kubernetes 的一些资源对象,所以需要配置 rbac 相关认证,这里我们使用了一个名为 prometheus 的 serviceAccount 对象:
1 | |
由于我们要获取的资源信息,在每一个 namespace 下面都有可能存在,所以我们这里使用的是 ClusterRole 的资源对象,值得一提的是我们这里的权限规则声明中有一个 nonResourceURLs 的属性,是用来对非资源型 metrics 进行操作的权限声明,这个在以前我们很少遇到过,然后直接创建上面的资源对象即可:
prometheus-pvc.yaml
⚠️:使用storageClassName无法使用selector,因为这个是匹配后端pv的
1 | |
prometheus-deploy.yaml
1 | |
prometheus-svc.yaml
Pod 创建成功后,为了能够在外部访问到 prometheus 的 webui 服务,我们还需要创建一个 Service 对象:
1 | |
1.4 测试访问
这里使用的是kubectl port-forward svc/prometheus 9091:9090 -n monitor将端口转发到本地的9091端口
1 | |

2. 应用监控
Prometheus 的数据指标是通过一个公开的 HTTP(S) 数据接口获取到的,我们不需要单独安装监控的 agent,只需要暴露一个 metrics 接口,Prometheus 就会定期去拉取数据;对于一些普通的 HTTP 服务,我们完全可以直接重用这个服务,添加一个 /metrics 接口暴露给 Prometheus;而且获取到的指标数据格式是非常易懂的,不需要太高的学习成本。
现在很多服务从一开始就内置了一个 /metrics 接口,比如 Kubernetes 的各个组件、istio 服务网格都直接提供了数据指标接口。有一些服务即使没有原生集成该接口,也完全可以使用一些 exporter 来获取到指标数据,比如 mysqld_exporter、node_exporter,这些 exporter 就有点类似于传统监控服务中的 agent,作为服务一直存在,用来收集目标服务的指标数据然后直接暴露给 Prometheus。
2.1 普通应用
对于普通应用只需要能够提供一个满足 prometheus 格式要求的 /metrics 接口就可以让 Prometheus 来接管监控,比如 Kubernetes 集群中非常重要的 CoreDNS 插件,一般默认情况下就开启了 /metrics 接口:
1 | |
上面 ConfigMap 中 prometheus :9153 就是开启 prometheus 的插件:
1 | |
尝试手动访问下 /metrics 接口,如果能够手动访问到那证明接口是没有任何问题的:
1 | |
我们可以看到可以正常访问到,从这里可以看到 CoreDNS 的监控数据接口是正常的了,然后我们就可以将这个 /metrics 接口配置到 prometheus.yml 中去了,直接加到默认的 prometheus 这个 job 下面:
1 | |
当然,我们这里只是很简单的配置,scrape_configs下可以支持很多的参数,例如:
basic_auth和bearer_token:比如我们提供的/metrics接口需要 basic 认证的时候,通过传统的用户名/密码或者在请求的 header 中添加对应的 token 都可以支持kubernetes_sd_configs或consul_sd_configs:可以用来自动发现一些应用的监控数据
现在我们重新更新这个 ConfigMap 资源对象:
1 | |
现在 Prometheus 的配置文件内容已经更改了,隔一会儿被挂载到 Pod 中的 prometheus.yml 文件也会更新,由于我们之前的 Prometheus 启动参数中添加了 --web.enable-lifecycle 参数,所以现在我们只需要执行一个 reload 命令即可让配置生效:
1 | |
由于 ConfigMap 通过 Volume 的形式挂载到 Pod 中去的热更新需要一定的间隔时间才会生效,所以需要稍微等一小会儿。
这个时候我们再去看 Prometheus 的 Dashboard 中查看采集的目标数据:
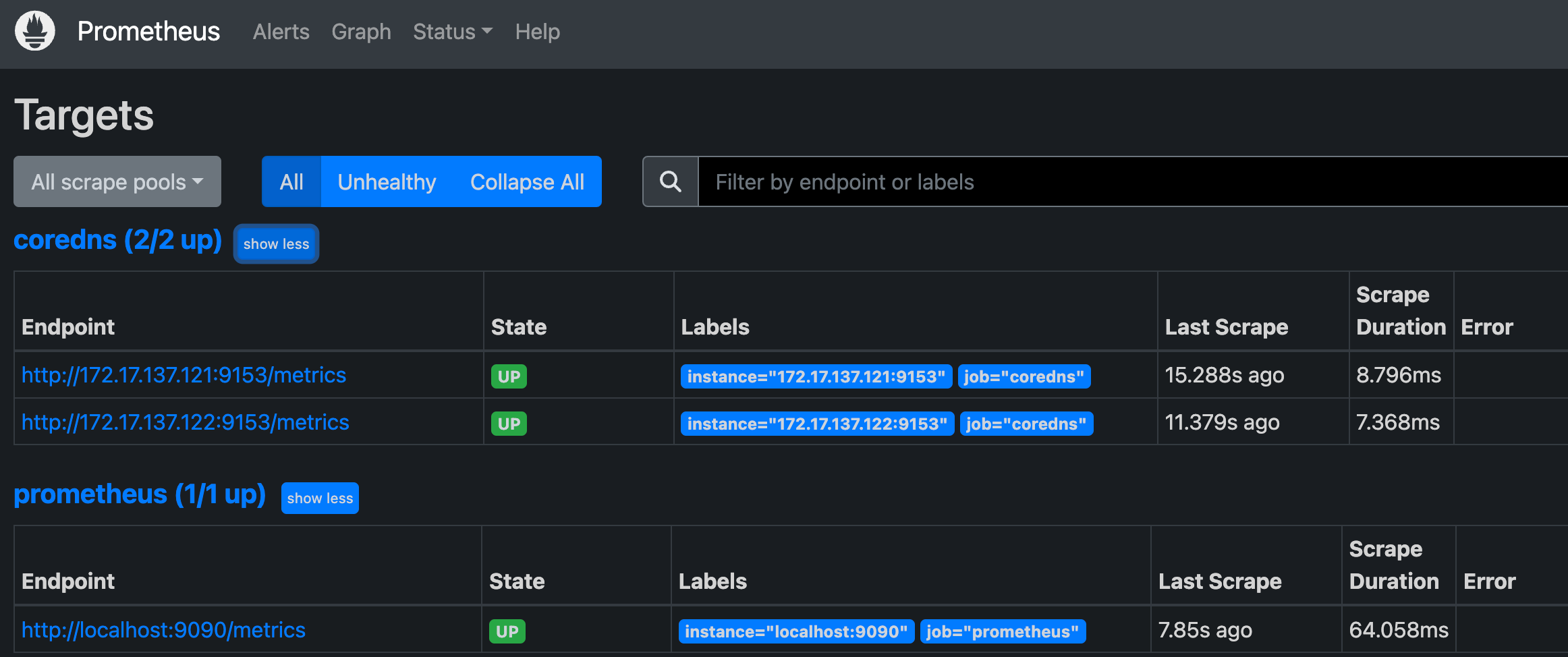
可以看到我们刚刚添加的 coredns 这个任务已经出现了,然后同样的我们可以切换到 Graph 下面去,我们可以找到一些 CoreDNS 的指标数据,至于这些指标数据代表什么意义,一般情况下,我们可以去查看对应的 /metrics 接口,里面一般情况下都会有对应的注释。
到这里我们就在 Prometheus 上配置了第一个 Kubernetes 应用。
2.2 使用expoter监控
上面我们也说过有一些应用可能没有自带 /metrics 接口供 Prometheus 使用,在这种情况下,我们就需要利用 exporter 服务来为 Prometheus 提供指标数据了。Prometheus 官方为许多应用就提供了对应的 exporter 应用,也有许多第三方的实现,我们可以前往官方网站进行查看:exporters,当然如果你的应用本身也没有 exporter 实现,那么就要我们自己想办法去实现一个 /metrics 接口了,只要你能提供一个合法的 /metrics 接口,Prometheus 就可以监控你的应用。
比如我们这里通过一个 redis-exporter 的服务来监控 redis 服务,对于这类应用,我们一般会以 sidecar 的形式和主应用部署在同一个 Pod 中,比如我们这里来部署一个 redis 应用,并用 redis-exporter 的方式来采集监控数据供 Prometheus 使用,如下资源清单文件:
promettheus-redis-deploy.yaml
1 | |
可以看到上面我们在 redis 这个 Pod 中包含了两个容器,一个就是 redis 本身的主应用,另外一个容器就是 redis_exporter。现在直接创建上面的应用:
1 | |
通过 9121 端口来校验是否能够采集到数据:
1 | |
同样的,现在我们只需要更新 Prometheus 的配置文件:
1 | |
由于我们这里是通过 Service 去配置的 redis 服务,当然直接配置 Pod IP 也是可以的,因为和 Prometheus 处于同一个 namespace,所以我们直接使用 servicename 即可。配置文件更新后,重新加载:
1 | |
这个时候我们再去看 Prometheus 的 Dashboard 中查看采集的目标数据:
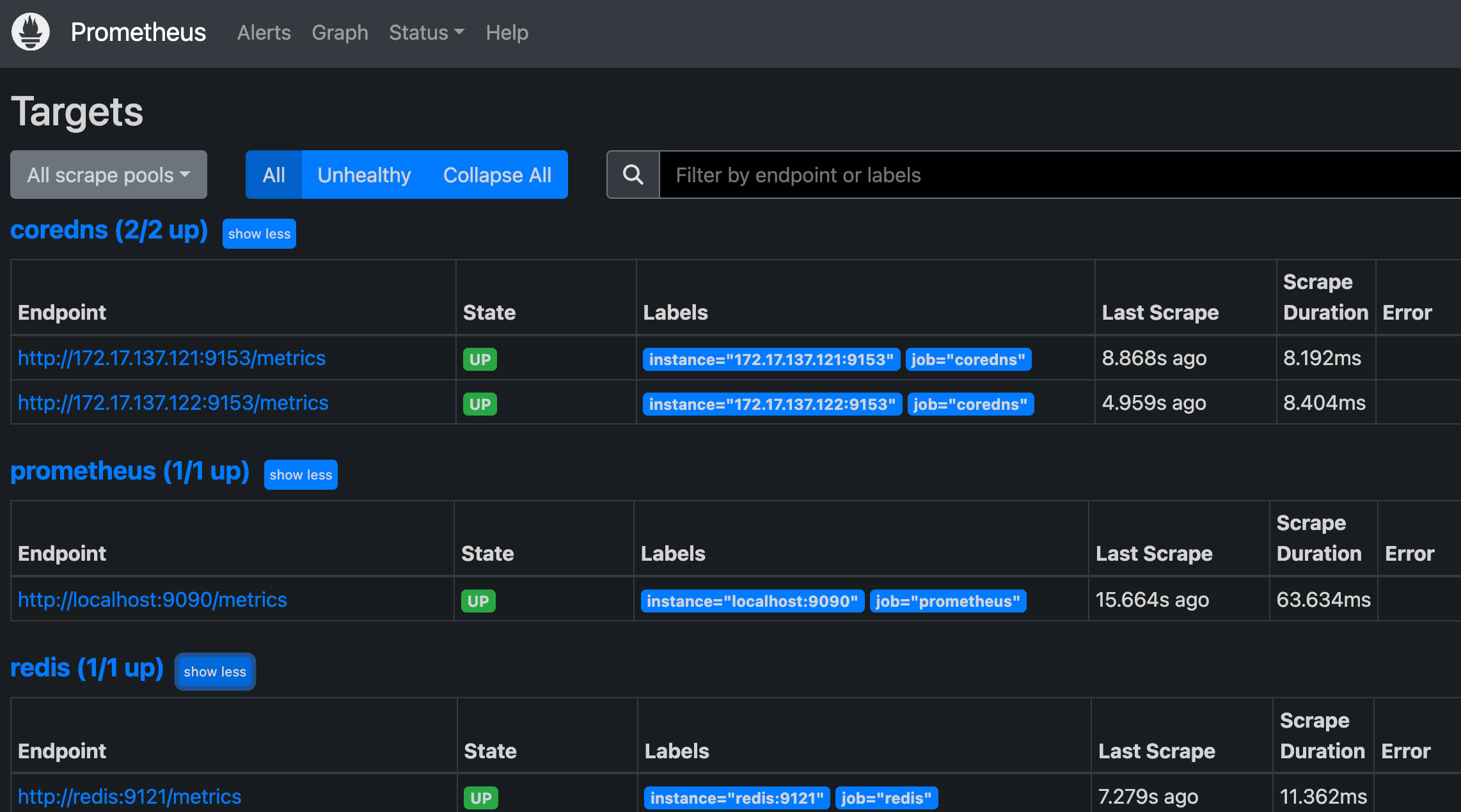
可以看到配置的 redis 这个 job 已经生效了。切换到 Graph 下面可以看到很多关于 redis 的指标数据,我们选择任意一个指标,比如 redis_exporter_scrapes_total,然后点击执行就可以看到对应的数据图表了:
3. 集群节点
对于集群的监控一般我们需要考虑以下几个方面:
- Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
- 内部系统组件的状态:比如 kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
- 编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标
Kubernetes 集群的监控方案目前主要有以下几种方案:
- cAdvisor:cAdvisor 是 Google 开源的容器资源监控和性能分析工具,它是专门为容器而生,本身也支持 Docker 容器。
- kube-state-metrics:kube-state-metrics 通过监听 API Server 生成有关资源对象的状态指标,比如 Deployment、Node、Pod,需要注意的是 kube-state-metrics 只是简单提供一个 metrics 数据,并不会存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储。
- metrics-server:metrics-server 也是一个集群范围内的资源数据聚合工具,是 Heapster 的替代品,同样的,metrics-server 也只是显示数据,并不提供数据存储服务。
不过 kube-state-metrics 和 metrics-server 之间还是有很大不同的,二者的主要区别如下:
- kube-state-metrics 主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等
- metrics-server 主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标。
3.1 监控集群节点
要监控节点其实我们已经有很多非常成熟的方案了,比如 Nagios、zabbix,甚至我们自己来收集数据也可以,我们这里通过 Prometheus 来采集节点的监控指标数据,可以通过 node_exporter 来获取,顾名思义,node_exporter 就是抓取用于采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat 等,详细的监控点列表可以参考其 Github 仓库。
我们可以通过 DaemonSet 控制器来部署该服务,这样每一个节点都会自动运行一个这样的 Pod,如果我们从集群中删除或者添加节点后,也会进行自动扩展。
在部署 node-exporter 的时候有一些细节需要注意,如下资源清单文件:
1 | |
由于我们要获取到的数据是主机的监控指标数据,而我们的 node-exporter 是运行在容器中的,所以我们在 Pod 中需要配置一些 Pod 的安全策略,这里我们就添加了 hostPID: true、hostIPC: true、hostNetwork: true 3 个策略,用来使用主机的 PID namespace、IPC namespace 以及主机网络,这些 namespace 就是用于容器隔离的关键技术,要注意这里的 namespace 和集群中的 namespace 是两个完全不相同的概念。
另外我们还将主机的 /dev、/proc、/sys这些目录挂载到容器中,这些因为我们采集的很多节点数据都是通过这些文件夹下面的文件来获取到的,比如我们在使用 top 命令可以查看当前 cpu 使用情况,数据就来源于文件 /proc/stat,使用 free 命令可以查看当前内存使用情况,其数据来源是来自 /proc/meminfo 文件。
另外由于我们集群使用的是 kubeadm 搭建的,所以如果希望 master 节点也一起被监控,则需要添加相应的容忍,然后直接创建上面的资源对象:
1 | |
部署完成后,我们可以看到在几个节点上都运行了一个 Pod,由于我们指定了 hostNetwork=true,所以在每个节点上就会绑定一个端口 9100,我们可以通过这个端口去获取到监控指标数据:
1 | |
当然如果你觉得上面的手动安装方式比较麻烦,我们也可以使用 Helm 的方式来安装:
1 | |
3.2 服务发现
由于我们这里每个节点上面都运行了 node-exporter 程序,如果我们通过一个 Service 来将数据收集到一起用静态配置的方式配置到 Prometheus 去中,就只会显示一条数据,我们得自己在指标数据中去过滤每个节点的数据,当然我们也可以手动的把所有节点用静态的方式配置到 Prometheus 中去,但是以后要新增或者去掉节点的时候就还得手动去配置,那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?这就是 Prometheus 里面非常重要的服务发现功能了。
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,主要支持 5 中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
我们通过 kubectl 命令可以很方便的获取到当前集群中的所有节点信息:
1 | |
但是要让 Prometheus 也能够获取到当前集群中的所有节点信息的话,我们就需要利用 Node 的服务发现模式,同样的,在 prometheus.yml 文件中配置如下的 job 任务即可:
1 | |
通过指定 kubernetes_sd_configs 的模式为 node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口。
prometheus 的 ConfigMap 更新完成后,同样的我们执行 reload 操作,让配置生效:
1 | |
配置生效后,我们再去 prometheus 的 dashboard 中查看 Targets 是否能够正常抓取数据

我们可以看到上面的 nodes 这个 job 任务已经自动发现了我们 4个 node 节点,但是在获取数据的时候失败了,出现了类似于下面的错误信息:
1 | |
这个是因为 prometheus 去发现 Node 模式的服务的时候,访问的端口默认是 10250,而默认是需要认证的 https 协议才有权访问的,但实际上我们并不是希望让去访问 10250 端口的 /metrics 接口,而是 node-exporter 绑定到节点的 9100 端口,所以我们应该将这里的 10250 替换成 9100,但是应该怎样替换呢?
这里我们就需要使用到 Prometheus 提供的 relabel_configs 中的 replace 能力了,relabel 可以在 Prometheus 采集数据之前,通过 Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配 __address__ 这个 Label 标签,然后替换掉其中的端口,如果你不知道有哪些 Label 标签可以操作的话,可以在 Service Discovery 页面获取到相关的元标签,这些标签都是我们可以进行 Relabel 的标签:
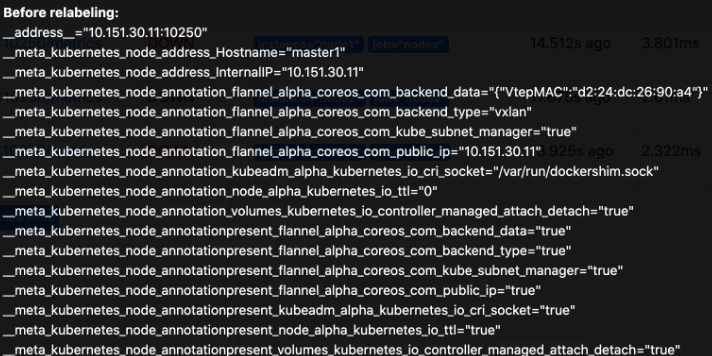
现在我们来替换掉端口,修改 ConfigMap:
1 | |
这里就是一个正则表达式,去匹配 __address__ 这个标签,然后将 host 部分保留下来,port 替换成了 9100,现在我们重新更新配置文件,执行 reload 操作,然后再去看 Prometheus 的 Dashboard 的 Targets 路径下面 kubernetes-nodes 这个 job 任务是否正常了:
1 | |
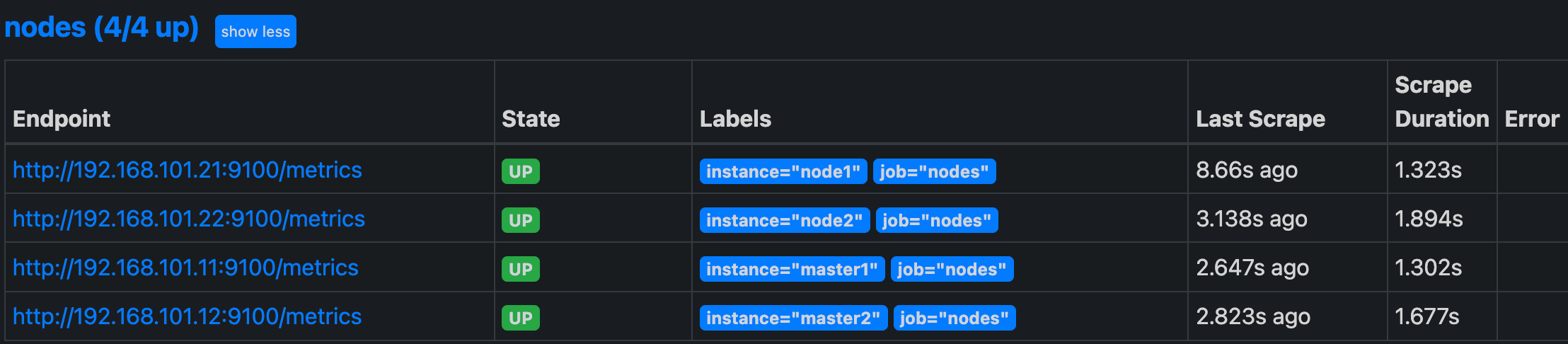
我们可以看到现在已经正常了,但是还有一个问题就是我们采集的指标数据 Label 标签就只有一个节点的 hostname,这对于我们在进行监控分组分类查询的时候带来了很多不方便的地方,要是我们能够将集群中 Node 节点的 Label 标签也能获取到就很好了。这里我们可以通过 labelmap 这个属性来将 Kubernetes 的 Label 标签添加为 Prometheus 的指标数据的标签:
1 | |
添加了一个 action 为 labelmap,正则表达式是 __meta_kubernetes_node_label_(.+) 的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中去。
对于 kubernetes_sd_configs 下面可用的元信息标签如下:
__meta_kubernetes_node_name:节点对象的名称_meta_kubernetes_node_label:节点对象中的每个标签_meta_kubernetes_node_annotation:来自节点对象的每个注释_meta_kubernetes_node_address:每个节点地址类型的第一个地址(如果存在)
关于 kubernets_sd_configs 更多信息可以查看官方文档:kubernetes_sd_config
另外由于 kubelet 也自带了一些监控指标数据,就上面我们提到的 10250 端口,所以我们这里也把 kubelet 的监控任务也一并配置上:
1 | |
但是这里需要特别注意的是这里必须使用 https 协议访问,这样就必然需要提供证书,我们这里是通过配置 insecure_skip_verify: true 来跳过了证书校验,但是除此之外,要访问集群的资源,还必须要有对应的权限才可以,也就是对应的 ServiceAccount 棒的 权限允许才可以,我们这里部署的 prometheus 关联的 ServiceAccount 对象前面我们已经提到过了,这里我们只需要将 Pod 中自动注入的 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt 和 /var/run/secrets/kubernetes.io/serviceaccount/token 文件配置上,就可以获取到对应的权限了。
现在我们再去更新下配置文件,执行 reload 操作,让配置生效,然后访问 Prometheus 的 Dashboard 查看 Targets 路径:
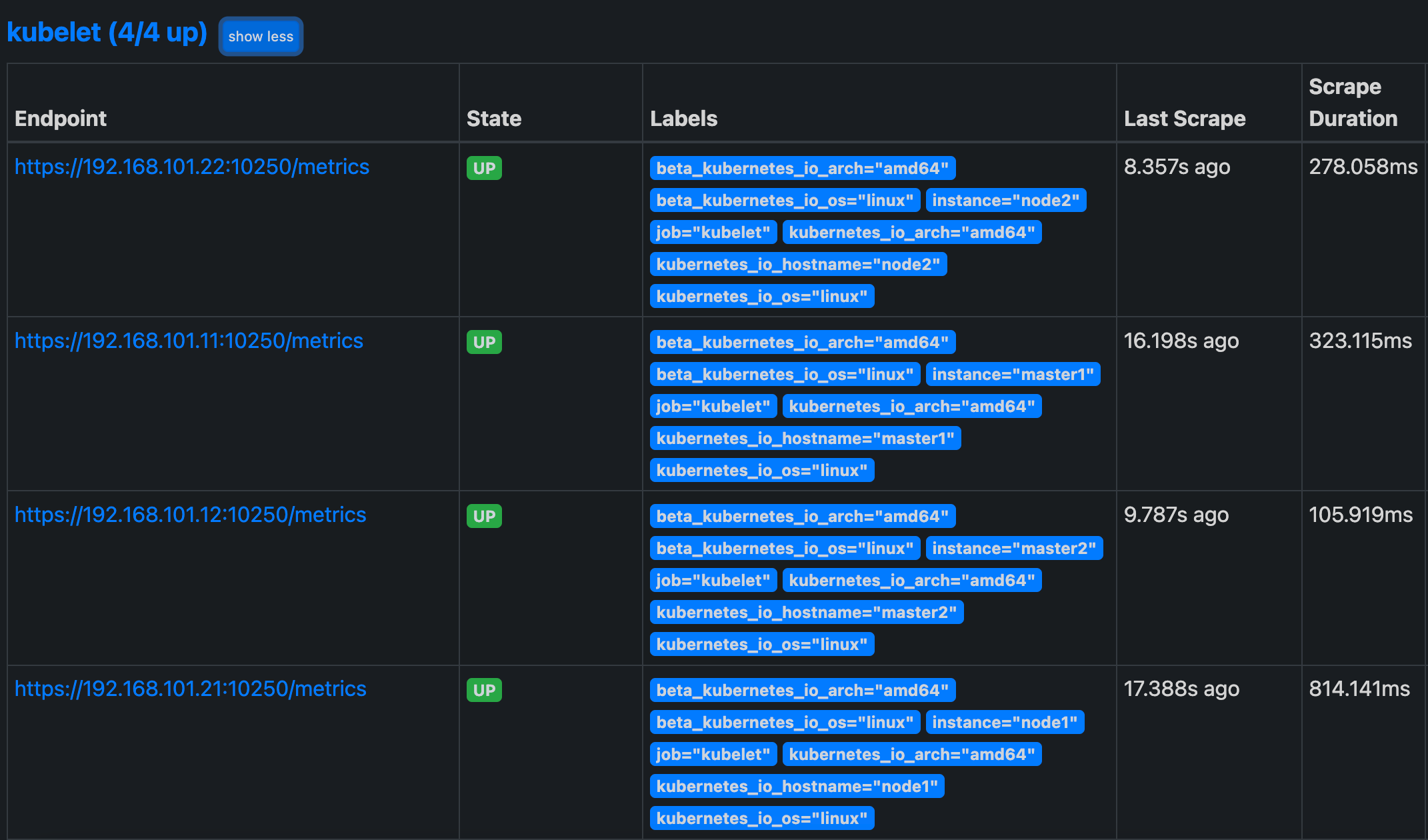
现在可以看到我们上面添加的 kubernetes-kubelet 和 kubernetes-nodes 这两个 job 任务都已经配置成功了,而且二者的 Labels 标签都和集群的 node 节点标签保持一致了。
现在我们就可以切换到 Graph 路径下面查看采集的一些指标数据了,比如查询 node_load1 指标:
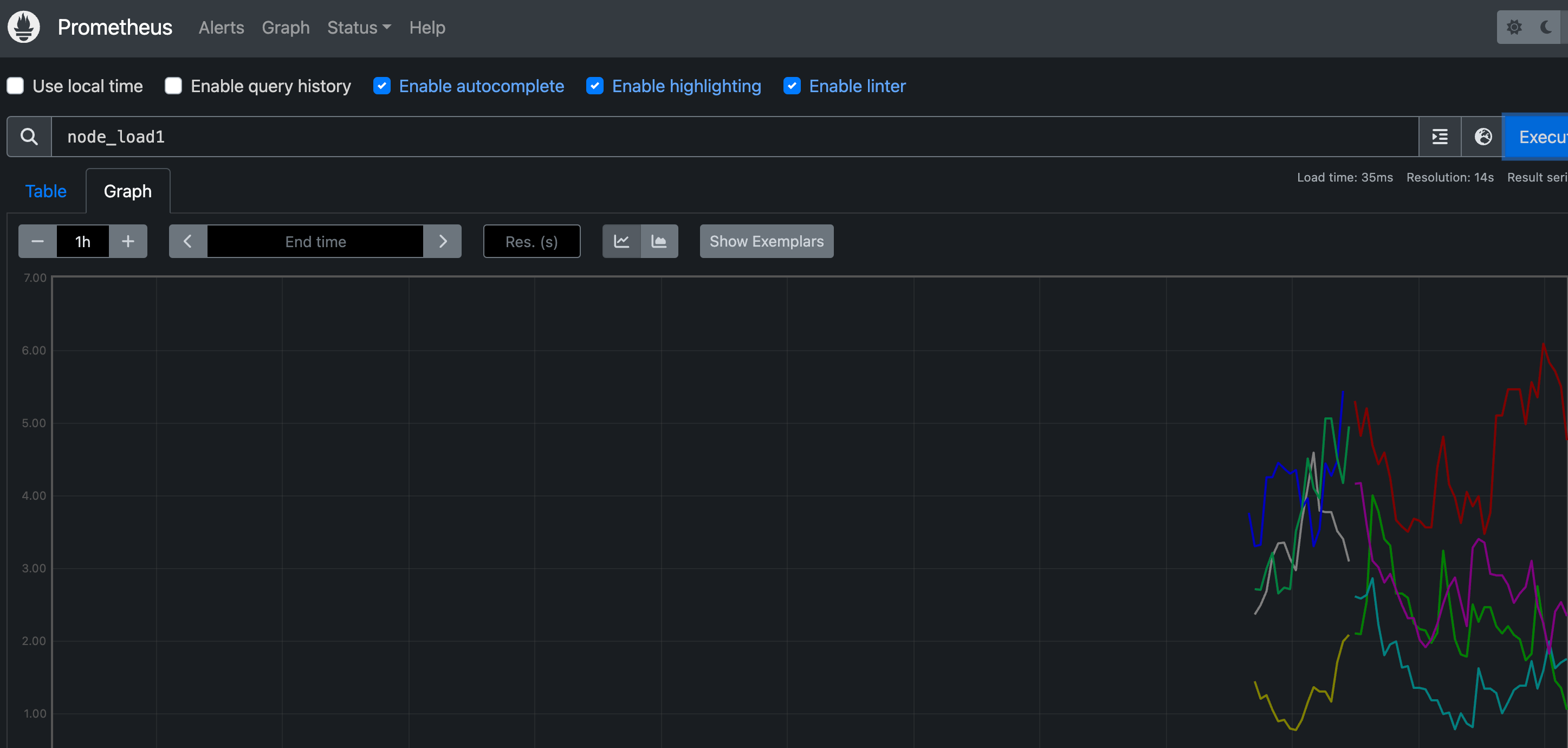
我们可以看到将几个节点对应的 node_load1 指标数据都查询出来了,同样的,我们还可以使用 PromQL 语句来进行更复杂的一些聚合查询操作,还可以根据我们的 Labels 标签对指标数据进行聚合,比如我们这里只查询 node1 节点的数据,可以使用表达式 node_load1{instance="node1"} 来进行查询:

到这里我们就把 Kubernetes 集群节点使用 Prometheus 监控起来了,接下来我们再来和大家学习下怎样监控 Pod 或者 Service 之类的资源对象。
4. 容器监控
说到容器监控我们自然会想到 cAdvisor,我们前面也说过 cAdvisor 已经内置在了 kubelet 组件之中,所以我们不需要单独去安装,cAdvisor 的数据路径为 /api/v1/nodes/<node>/proxy/metrics,但是我们不推荐使用这种方式,因为这种方式是通过 APIServer 去代理访问的,对于大规模的集群比如会对 APIServer 造成很大的压力,所以我们可以直接通过访问 kubelet 的 /metrics/cadvisor 这个路径来获取 cAdvisor 的数据, 同样我们这里使用 node 的服务发现模式,因为每一个节点下面都有 kubelet,自然都有 cAdvisor 采集到的数据指标,配置如下:
1 | |
上面的配置和我们之前配置 node-exporter 的时候几乎是一样的,区别是我们这里使用了 https 的协议,另外需要注意的是配置了 ca.cart 和 token 这两个文件,这两个文件是 Pod 启动后自动注入进来的,然后加上 __metrics_path__ 的访问路径 /metrics/cadvisor,现在同样更新下配置,然后查看 Targets 路径:
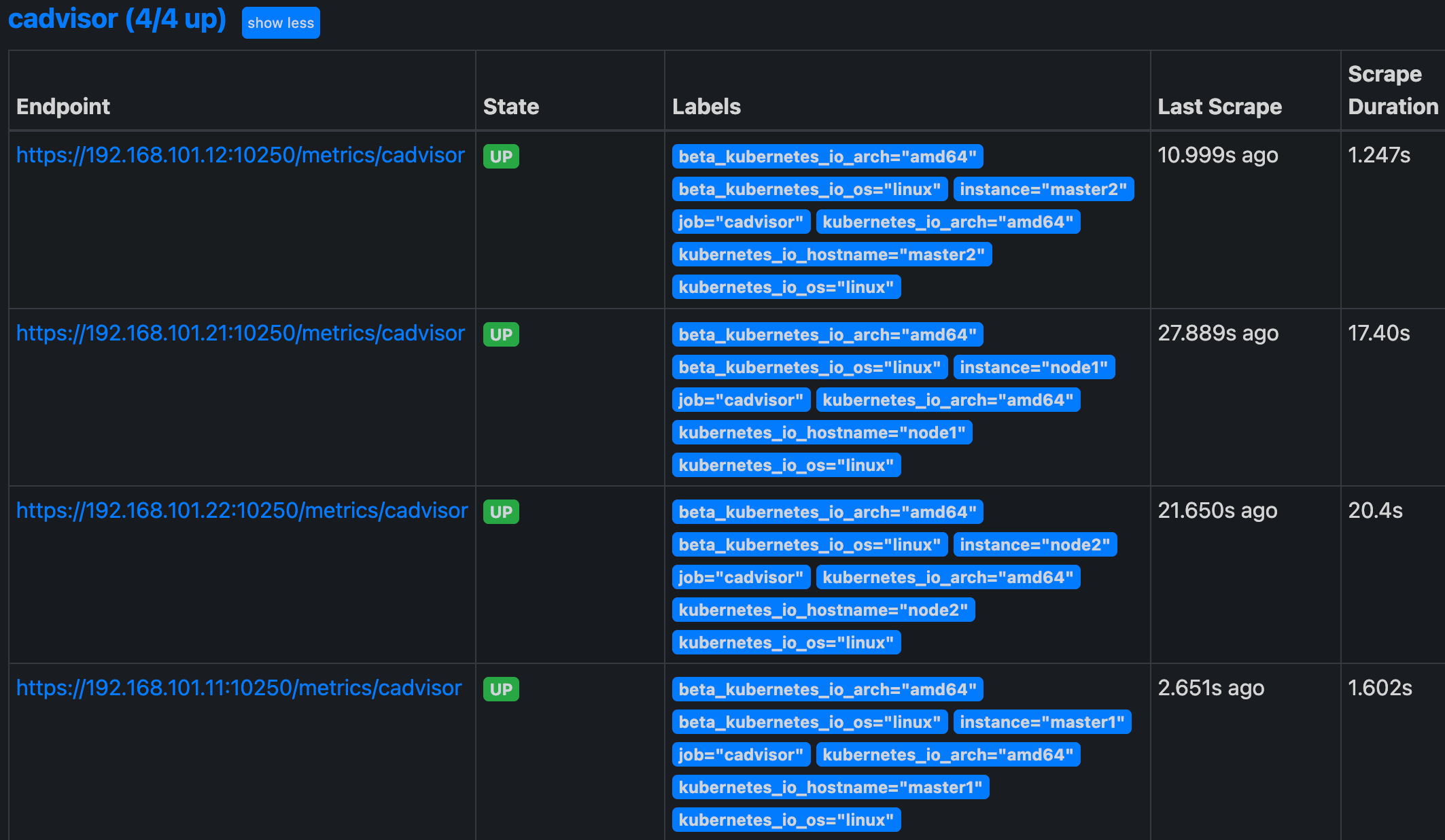
我们可以切换到 Graph 路径下面查询容器相关数据,比如我们这里来查询集群中所有 Pod 的 CPU 使用情况,kubelet 中的 cAdvisor 采集的指标和含义,可以查看 Monitoring cAdvisor with Prometheus 说明,其中有一项:
1 | |
container_cpu_usage_seconds_total 是容器累计使用的 CPU 时间,用它除以 CPU 的总时间,就可以得到容器的 CPU 使用率了:
首先计算容器的 CPU 占用时间,由于节点上的 CPU 有多个,所以需要将容器在每个 CPU 上占用的时间累加起来,Pod 在 1m 内累积使用的 CPU 时间为:(根据 pod 和 namespace 进行分组查询)
1 | |
在 Kubernetes 1.16 版本中移除了 cadvisor metrics 的 pod_name 和 container_name 这两个标签,改成了 pod 和 container。
1 | |
然后计算 CPU 的总时间,这里的 CPU 数量是容器分配到的 CPU 数量,container_spec_cpu_quota 是容器的 CPU 配额,它的值是容器指定的 CPU 个数 * 100000,所以 Pod 在 1s 内 CPU 的总时间为:Pod 的 CPU 核数 * 1s:
1 | |
由于 container_spec_cpu_quota 是容器的 CPU 配额,所以只有配置了 resource-limit CPU 的 Pod 才可以获得该指标数据。
将上面这两个语句的结果相除,就得到了容器的 CPU 使用率:
1 | |
在 promethues 里面执行上面的 promQL 语句可以得到下面的结果:
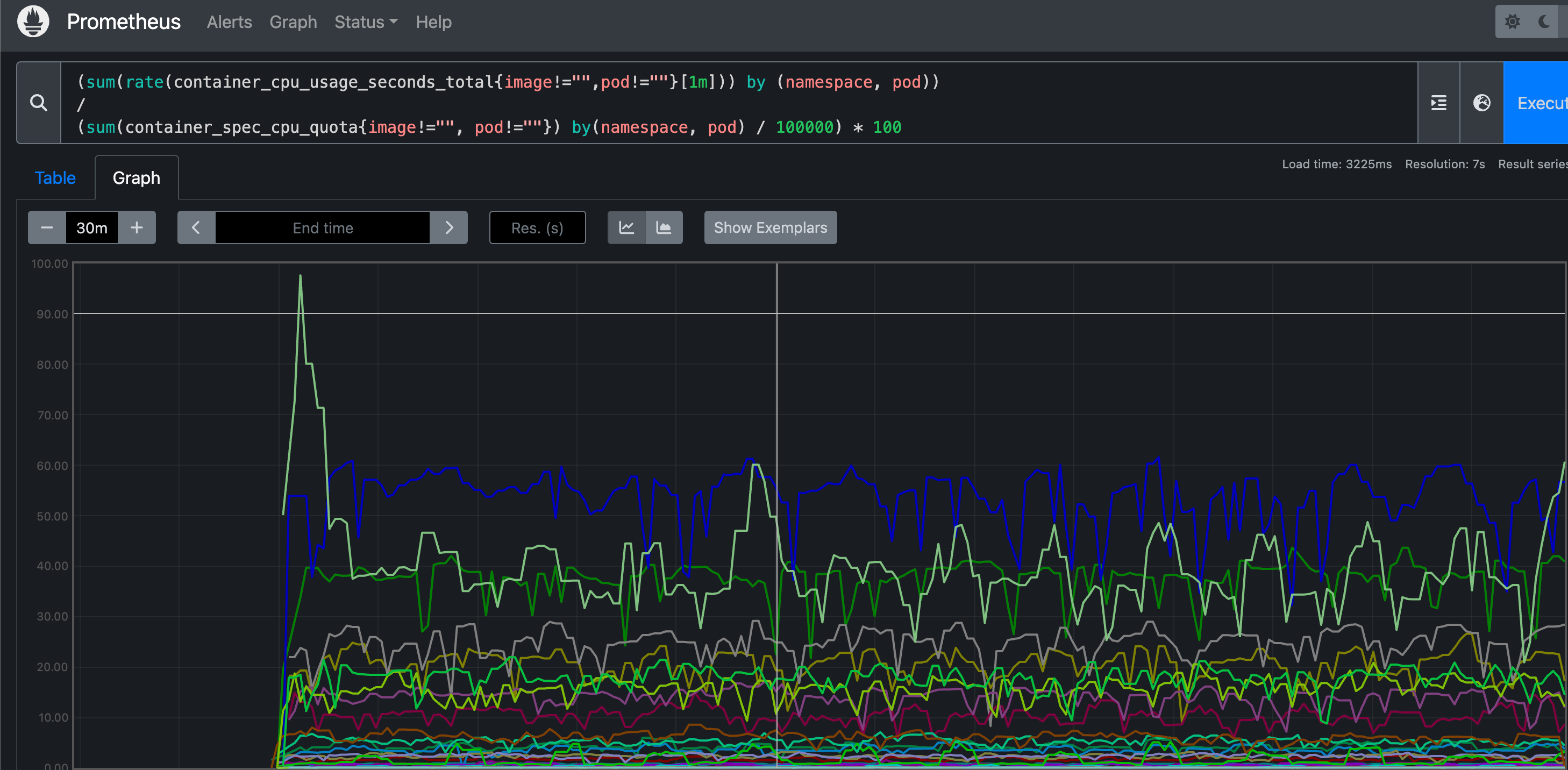
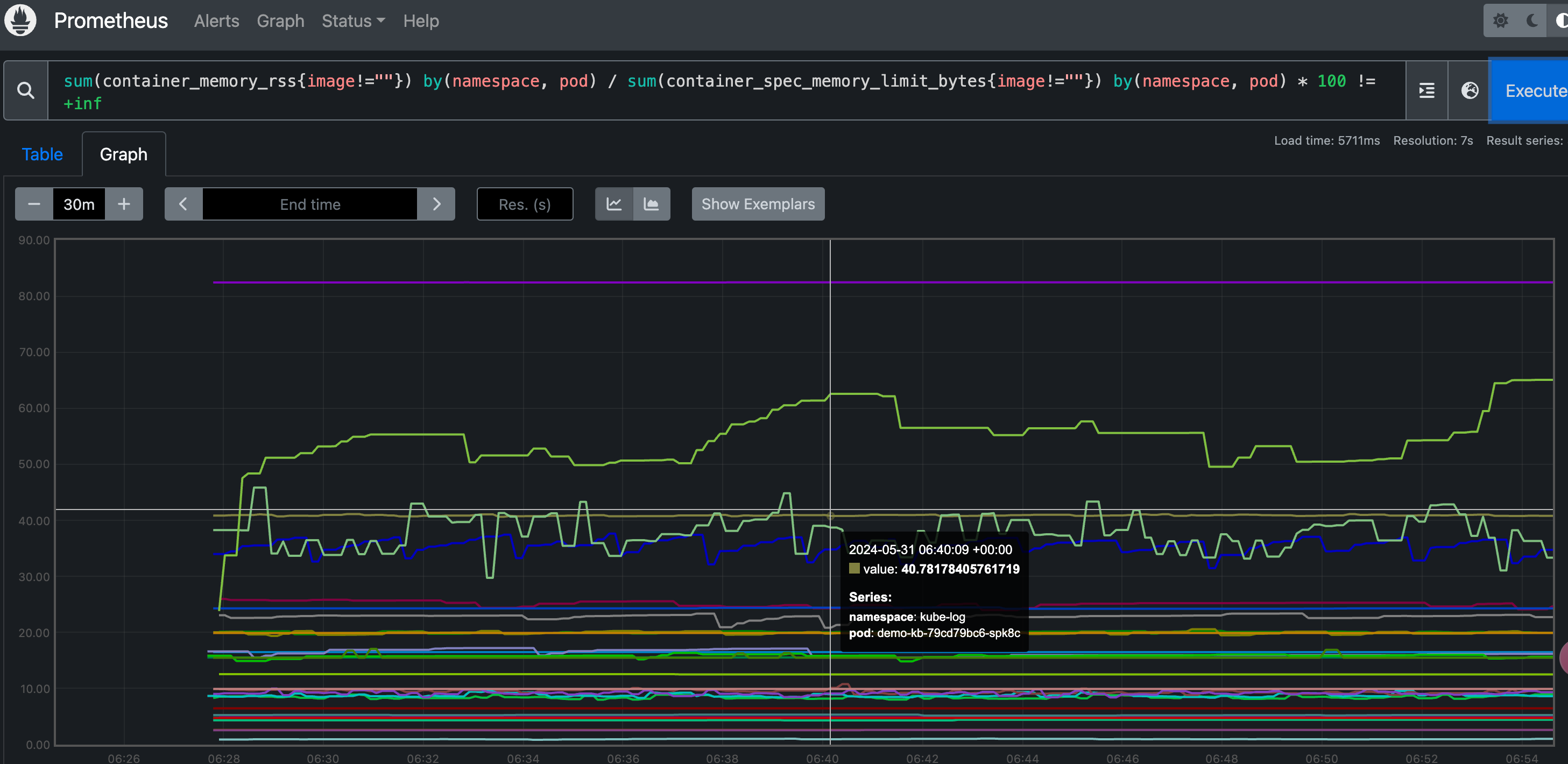
Pod 内存使用率的计算就简单多了,直接用内存实际使用量除以内存限制使用量即可:
1 | |
5. 监控apiserver
apiserver 作为 Kubernetes 最核心的组件,当然他的监控也是非常有必要的,对于 apiserver 的监控我们可以直接通过 kubernetes 的 Service 来获取:
1 | |
上面这个 Service 就是我们集群的 apiserver 在集群内部的 Service 地址,要自动发现 Service 类型的服务,我们就需要用到 role 为 Endpoints 的 kubernetes_sd_configs,我们可以在 ConfigMap 对象中添加上一个 Endpoints 类型的服务的监控任务:
1 | |
上面这个任务是定义的一个类型为 endpoints 的 kubernetes_sd_configs ,添加到 Prometheus 的 ConfigMap 的配置文件中,然后更新配置:
1 | |
更新完成后,我们再去查看 Prometheus 的 Dashboard 的 target 页面:
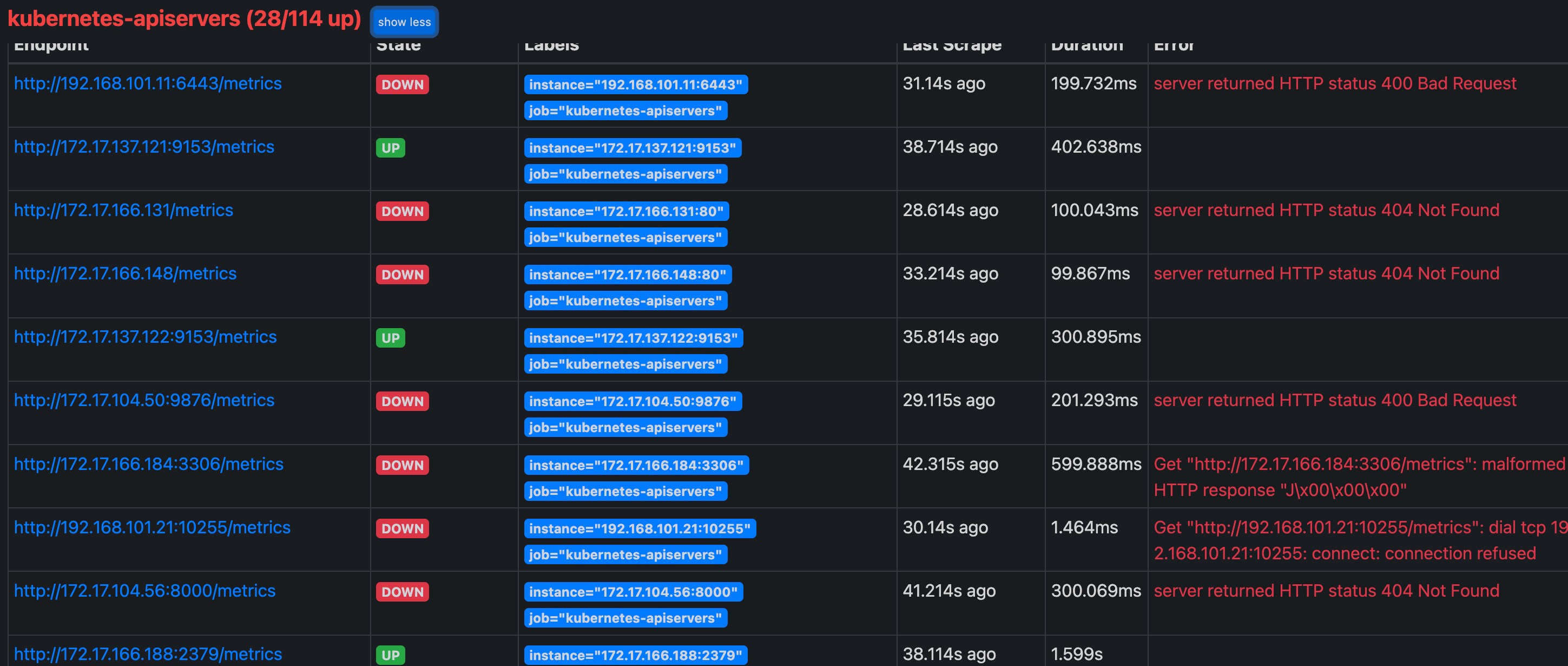
我们可以看到 kubernetes-apiservers 下面出现了很多实例,这是因为这里我们使用的是 Endpoints 类型的服务发现,所以 Prometheus 把所有的 Endpoints 服务都抓取过来了,同样的,上面我们需要的服务名为 kubernetes 这个 apiserver 的服务也在这个列表之中,那么我们应该怎样来过滤出这个服务来呢?还记得前面的 relabel_configs 吗?没错,同样我们需要使用这个配置,只是我们这里不是使用 replace 这个动作了,而是 keep,就是只把符合我们要求的给保留下来,哪些才是符合我们要求的呢?我们可以把鼠标放置在任意一个 target 上,可以查看到 Before relabeling里面所有的元数据,比如我们要过滤的服务是 default 这个 namespace 下面,服务名为 kubernetes 的元数据,所以这里我们就可以根据对应的 __meta_kubernetes_namespace 和 __meta_kubernetes_service_name 这两个元数据来 relabel,另外由于 kubernetes 这个服务对应的端口是 443,需要使用 https 协议,所以这里我们需要使用 https 的协议,对应的就需要将 ca 证书配置上,如下所示:
1 | |

现在可以看到 kubernetes-apiserver 这个任务下面只有 apiserver 这个实例了,证明我们的 relabel 是成功的,现在我们切换到 Graph 路径下面查看下采集到的数据,比如查询 apiserver 的总的请求数:

这样我们就完成了对 Kubernetes APIServer 的监控。
另外如果我们要来监控其他系统组件,比如 kube-controller-manager、kube-scheduler 的话应该怎么做呢?由于 apiserver 服务 namespace 在 default 使用默认的 Service kubernetes,而其余组件服务在 kube-system 这个 namespace 下面,如果我们想要来监控这些组件的话,需要手动创建单独的 Service,其中 kube-sheduler 的指标数据端口为 10251,kube-controller-manager 对应的端口为 10252,大家可以尝试下自己来配置下这几个系统组件。
6. 监控pod
上面的 apiserver 实际上就是一种特殊的 Endpoints,现在我们同样来配置一个任务用来专门发现普通类型的 Endpoint,其实就是 Service 关联的 Pod 列表:
1 | |
注意我们这里在 relabel_configs 区域做了大量的配置,特别是第一个保留 __meta_kubernetes_service_annotation_prometheus_io_scrape 为 true 的才保留下来,这就是说要想自动发现集群中的 Endpoint,就需要我们在 Service 的 annotation 区域添加 prometheus.io/scrape=true 的声明,现在我们先将上面的配置更新,查看下效果:
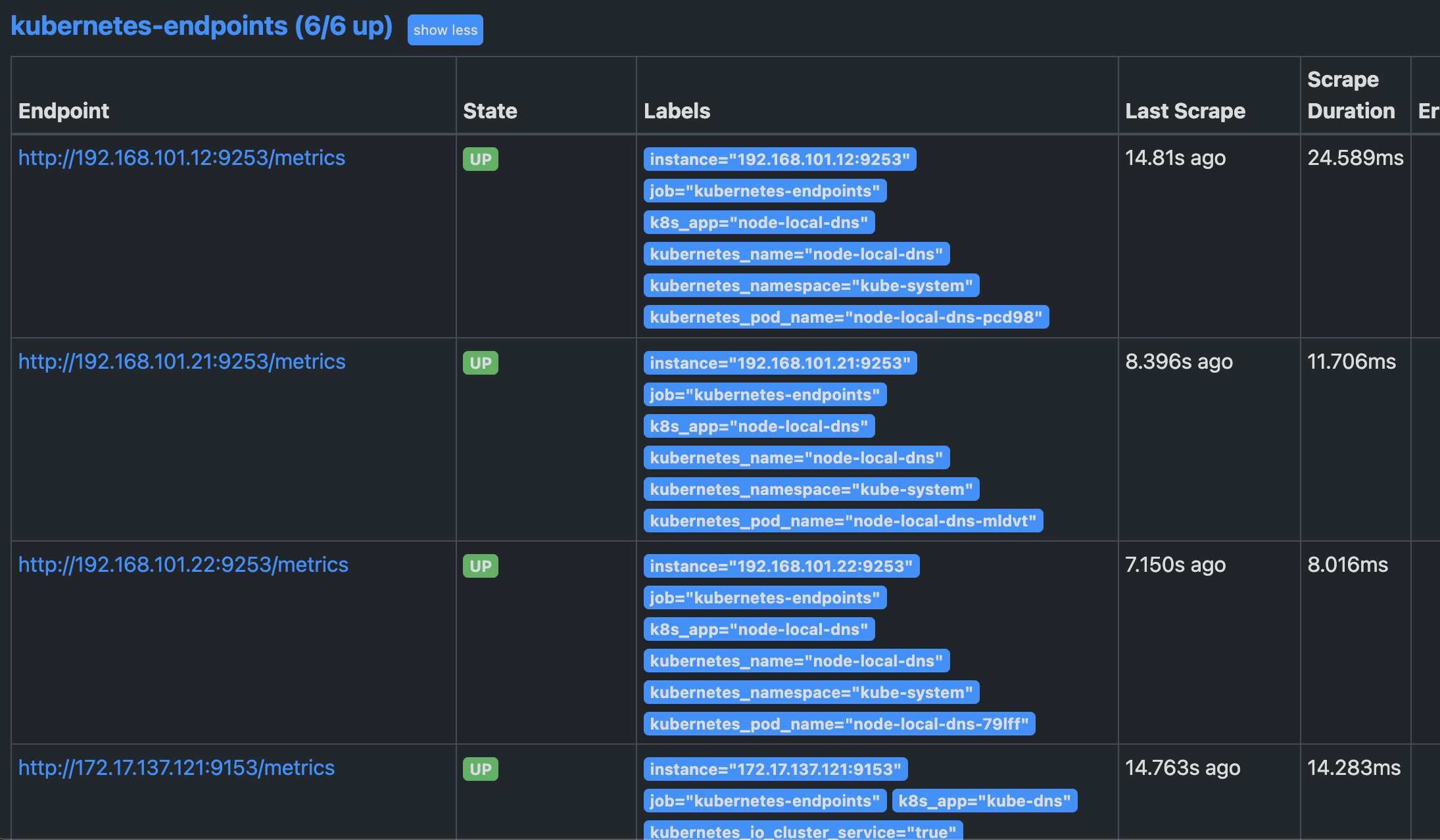
我们可以看到 kubernetes-endpoints 这一个任务下面只发现了6个服务,这是因为我们在 relabel_configs 中过滤了 annotation 有 prometheus.io/scrape=true 的 Service,而现在我们系统中只有 kube-dns 和node-local-dns服务符合要求, Service 下面有6个实例,所以出现了6个实例:
1 | |
现在我们在之前创建的 redis 这个 Service 中添加上 prometheus.io/scrape=true 这个 annotation:
1 | |
由于 redis 服务的 metrics 接口在 9121 这个 redis-exporter 服务上面,所以我们还需要添加一个 prometheus.io/port=9121 这样的 annotations,然后更新这个 Service:
1 | |
更新完成后,去 Prometheus 查看 Targets 路径,可以看到 redis 服务自动出现在了 kubernetes-endpoints 这个任务下面:
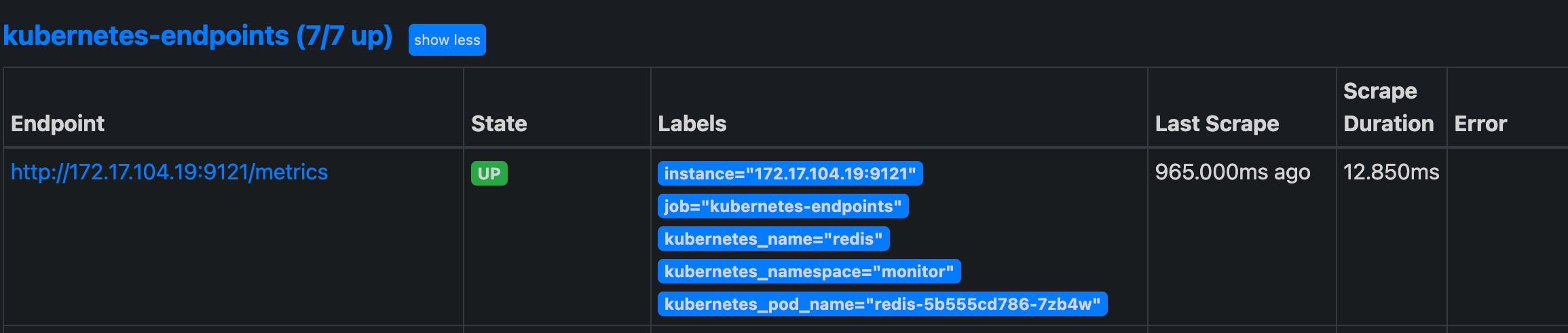
这样以后我们有了新的服务,服务本身提供了 /metrics 接口,我们就完全不需要用静态的方式去配置了,到这里我们就可以将之前配置的 redis 的静态配置去掉了。
7. kube-state-metrics
上面我们配置了自动发现 Endpoints 的监控,但是这些监控数据都是应用内部的监控,需要应用本身提供一个 /metrics 接口,或者对应的 exporter 来暴露对应的指标数据,但是在 Kubernetes 集群上 Pod、DaemonSet、Deployment、Job、CronJob 等各种资源对象的状态也需要监控,这也反映了使用这些资源部署的应用的状态。比如:
- 我调度了多少个副本?现在可用的有几个?
- 多少个 Pod 是
running/stopped/terminated状态? - Pod 重启了多少次?
- 我有多少 job 在运行中等等
通过查看前面从集群中拉取的指标(这些指标主要来自 apiserver 和 kubelet 中集成的 cAdvisor),并没有具体的各种资源对象的状态指标。对于 Prometheus 来说,当然是需要引入新的 exporter 来暴露这些指标,Kubernetes 提供了一个kube-state-metrics 就是我们需要的。
7.1 与 metric-server 的对比
metric-server是从 APIServer 中获取 cpu、内存使用率这种监控指标,并把他们发送给存储后端,如 influxdb 或云厂商,当前的核心作用是为 HPA 等组件提供决策指标支持。kube-state-metrics关注于获取 Kubernetes 各种资源的最新状态,如 deployment 或者 daemonset,metric-server 仅仅是获取、格式化现有数据,写入特定的存储,实质上是一个监控系统。而 kube-state-metrics 是获取集群最新的指标。- 像 Prometheus 这种监控系统,并不会去用 metric-server 中的数据,他都是自己做指标收集、集成的,但 Prometheus 可以监控 metric-server 本身组件的监控状态并适时报警,这里的监控就可以通过
kube-state-metrics来实现,如 metric-server pod 的运行状态。
7.2 安装
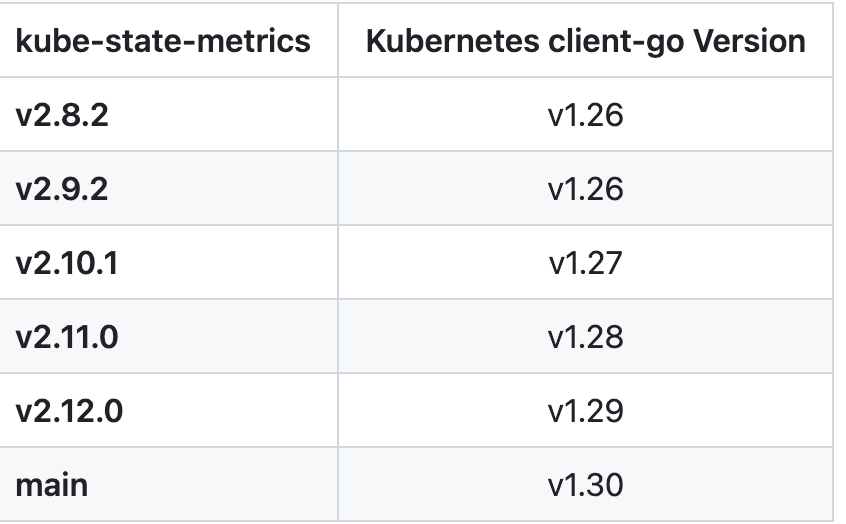
kube-state-metrics 已经给出了在 Kubernetes 部署的 manifest 定义文件,我们直接将代码 Clone 到集群中(能用 kubectl 工具操作就行),不过需要注意兼容的版本:
1 | |
默认的镜像为 registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.10.1 的,此外我们上面为 Prometheus 配置了 Endpoints 的自动发现,所以我们可以给 kube-state-metrics 的 Service 配置上对应的 annotations 来自动被发现,然后直接创建即可:
1 | |
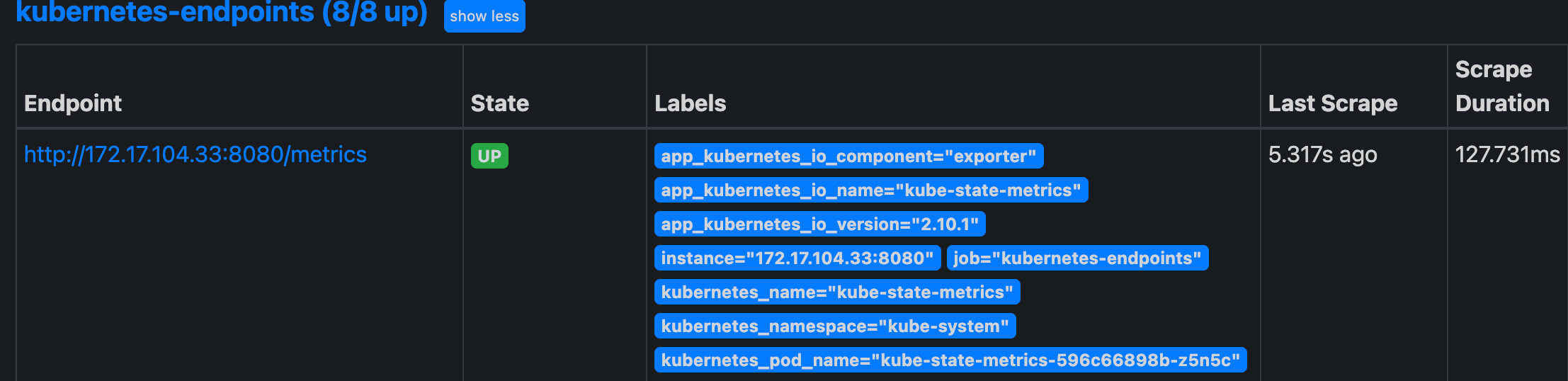
部署完成后正常就可以被 Prometheus 采集到指标了:
7.3 水平缩放(分片)
kube-state-metrics 已经内置实现了一些自动分片功能,可以通过 --shard 和 --total-shards 参数进行配置。现在还有一个实验性功能,如果将 kube-state-metrics 部署在 StatefulSet 中,它可以自动发现其命名位置,以便自动配置分片,这是一项实验性功能,可能以后会被移除。
要启用自动分片,必须运行一个 kube-state-metrics 的 StatefulSet,并且必须通过 --pod 和 --pod-namespace 标志将 pod 名称和名称空间传递给 kube-state-metrics 进程。可以参考 /examples/autosharding 目录下面的示例清单文件进行说明。
7.4 使用
使用kube-state-metrics的一些典型场景:
- 存在执行失败的Job:
kube_job_status_failed - 集群节点状态错误:
kube_nodes_status_condition{condition="Ready",status!="true"}==1 - 集群中存在启动失败的Pod:
kube_pod_status_phase{phase=~"Failed|Unknown"}==1 - 最近 30 分钟内有 Pod 容器重启:
changes(kube_pod_container_status_restarts_total[30m])>0
现在有一个问题是前面我们做 endpoints 类型的服务发现的时候做了一次 labelmap,将 namespace 和 pod 标签映射到了指标中,但是由于 kube-state-metrics 暴露的指标中本身就包含 namespace 和 pod 标签,这就会产生冲突,这种情况会将映射的标签变成 exported_namespace 和 exported_pod,这变会对指标的查询产生影响,如下所示:
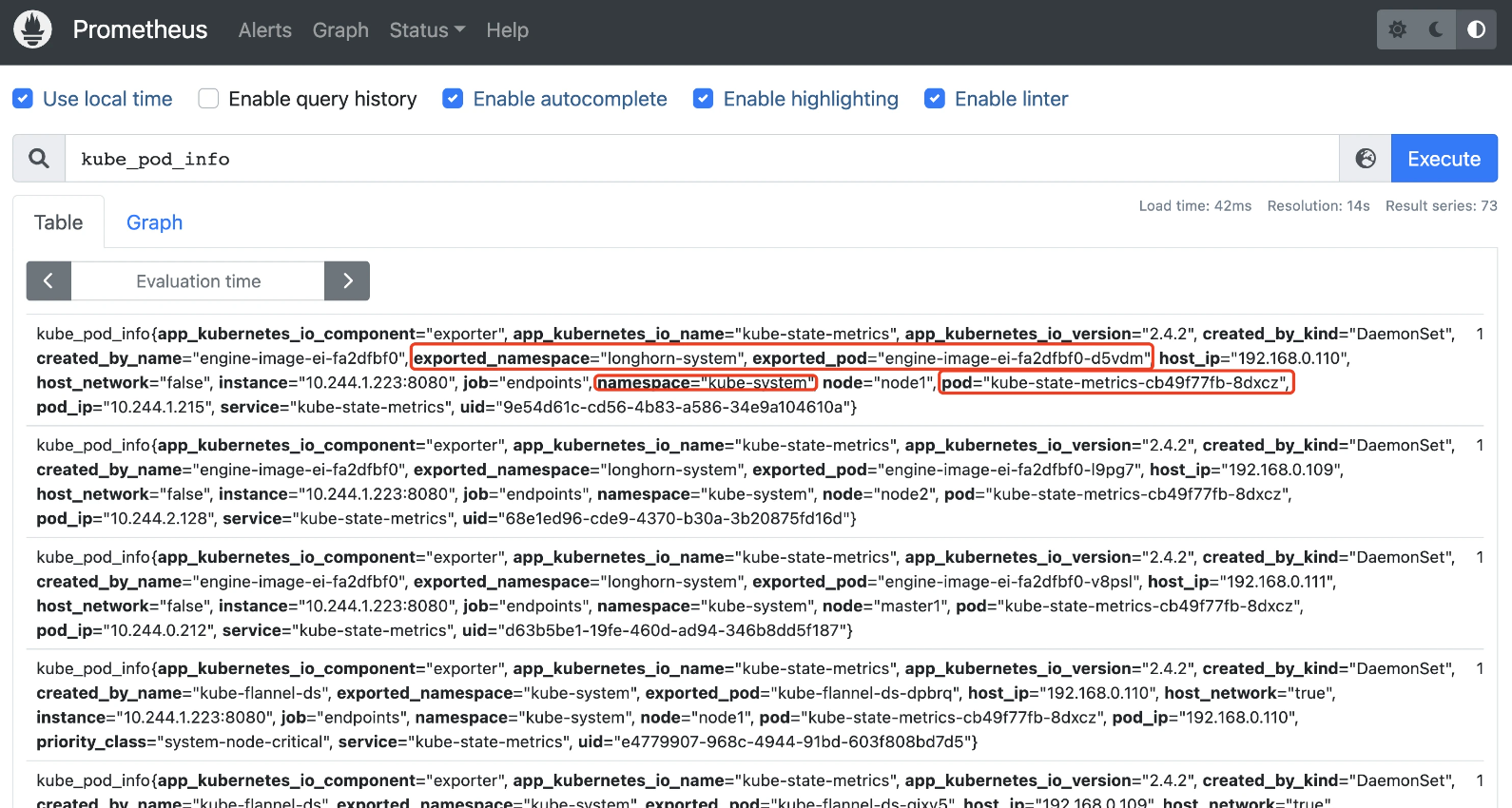
这个情况下我们可以使用 metric_relabel_configs 这 Prometheus 保存数据前的最后一步重新编辑标签,metric_relabel_configs 模块和 relabel_configs 模块很相似,metric_relabel_configs 一个很常用的用途就是可以将监控不需要的数据,直接丢掉,不在 Prometheus 中保存。比如我们这里可以重新配置 endpoints 类型的指标发现配置:
1 | |
metric_relabel_configs 与 relabel_configs 虽然非常类似,但是还是有很大不同的,relabel_configs 是针对 target 指标采集前和采集中的筛选,而 metric_relabel_configs 是针对指标采集后的筛选,如果一个不起作用,那么我们可以随时尝试使用另一个!
Prometheus 需要知道要抓取什么,这就是服务发现和 relabel_configs 配置的地方,relabel_configs 允许你选择要抓取的目标以及目标标签是什么,所以如果你想抓取这种类型的机器而不是那种类型的机器,请使用relabel_configs。
metric_relabel_configs 相比之下,在抓取发生之后,但在数据被存储系统摄取之前应用,因此,如果你想要删除一些昂贵的指标,或者你想要操作来自抓取目标本身的标签(例如来自 /metrics 页面),那就用 metric_relabel_configs。
譬如下面的 relabel_configs drop 动作:
1 | |
那么将不会收集这个指标,而 metric_relabel_configs 使用的时候指标已经采集过了:
1 | |
所以 metric_relabel_configs 相对来说,更加昂贵,因为指标已经采集了。
关于 kube-state-metrics 的更多用法可以查看官方 GitHub 仓库:https://github.com/kubernetes/kube-state-metrics
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!