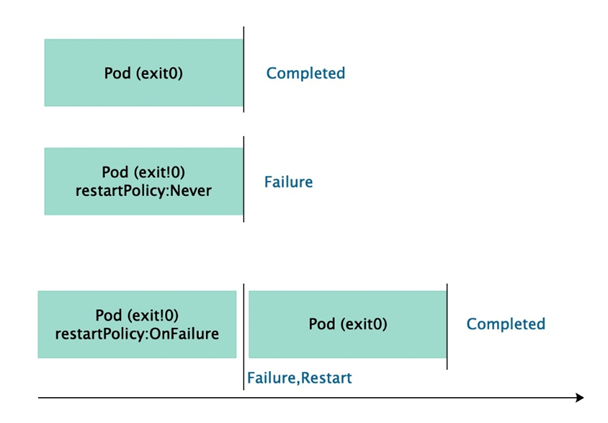
一、Job概念、原理解读 Job控制器用于管理Pod对象运行一次性任务,比方说我们对数据库备份,可以直接在k8s上启动一个mysqldump备份程序,也可以启动一个pod,这个pod专门用来备份用的,备份结束pod就可以终止了,不需要重启,而是将Pod对象置于”Completed”(完成)状态,若容器中的进程因错误而终止,则需要按照重启策略配置确定是否重启,对于Job这个类型的控制器来说,需不需要重建pod就看任务是否完成,完成就不需要重建,没有完成就需要重建pod。 Job控制器的Pod对象的状态转换如下图所示:
1、 Job三种使用场景 1、非并行任务:只启一个pod,pod成功,job正常结束
2、并行任务同时指定成功个数:.spec.completions为指定成功个数,可以指定也可以不指定.spec.parallelism(指定>1,会有多个任务并行运行)。当成功个数达到.spec.completions,任务结束。
3、有工作队列的并行任务:.spec.completions默认为1,.spec.parallelism为大于0整数。此时并行启动多个pod,只要有一个成功,任务结束,所有pod结束。
Job不是设计用来完成通信密集型的并行程序,如科学计算领域常见的场景。它支持并行地处理一组独立但相关的work item,如发送邮件,渲染帧,转码文件和扫描NoSql数据库中的key
2、Job相关参数配置 .spec.completions: 完成该Job需要执行成功的Pod数
.spec.parallelism: 能够同时运行的Pod数
.spec.backoffLimit: 允许执行失败的Pod数,默认值是6,0表示不允许Pod执行失败。如果Pod是restartPolicy为Nerver,则失败后会创建新的Pod,如果是OnFailed,则会重启Pod,不管是哪种情况,只要Pod失败一次就计算一次,而不是等整个Pod失败后再计算一个。当失败的次数达到该限制时,整个Job随即结束,所有正在运行中的Pod都会被删除。
.spec.activeDeadlineSeconds: Job的超时时间,一旦一个Job运行的时间超出该限制,则Job失败,所有运行中的Pod会被结束并删除。该配置指定的值必须是个正整数。不指定则不会超时
3、Job控制器资源清单编写技巧 1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master1 job]integer > integer > integer > integer > suspend <boolean>integer >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 integer >integer >integer >
4、Job案例:创建一个一次性任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@master1 job]command : ['sh' , '-c' ]'echo "Welcome to Job";sleep 60; echo "Next to Meet you"' ]
二、CronJob概念、原理解读 CronJob跟Job完成的工作是一样的,只不过CronJob添加了定时任务能力可以指定时间,实现周期性运行。Job,CronJob和Deployment,DaemonSet显著区别在于不需要持续在后台运行
Deployment主要用于管理无状态的应用(kubernetes集群有一些pod,某一个pod出现故障,删除之后会重新启动一个pod,那么kubernetes这个集群中pod数量就正常了,更多关注的是群体,这就是无状态应用)。
1、CronJob使用场景 1、在给定时间点只运行一次。
2、在给定时间点周期性地运行。
2、CronJob的典型用法 1、在给定的时间点调度Job运行。
2、创建周期性运行的Job,例如数据库备份、发送邮件
3、CronJob使用案例:创建周期性定时任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@master1 job]"*/1 * * * *" command :echo Hello from the Kubernetes cluster