描述高可用集群架构
1. 描述HA集群的硬件配置
下图显示了五节点HA集群的典型硬件配置。
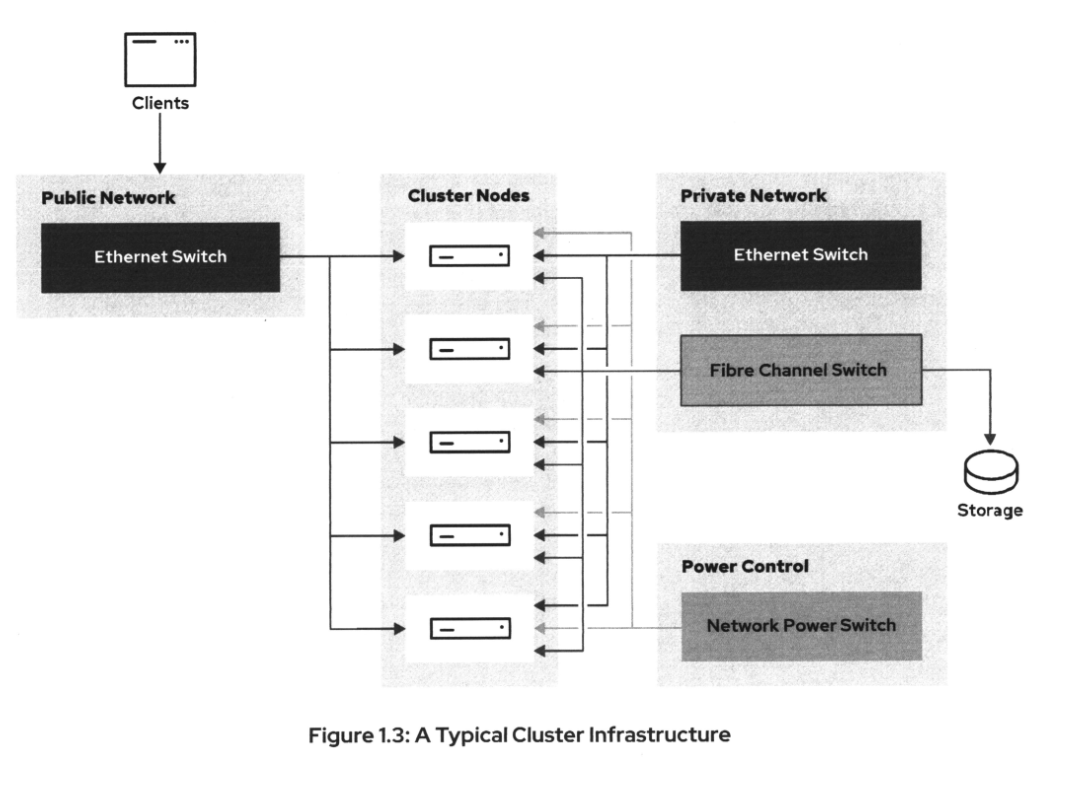
该基础设施的不同组件如下:
- 集群节点:运行集群软件和服务的机器
- public网络:客户端通过这个网络访问集群上的服务。服务通常有一个浮动IP地址,这个IP地址是集群分配给任何一个当前正在运行服务的节点上。
- Private网络:集群使用这个网络实现节点间通信。
- 联网电源开关:需要通过网络电源开关等方式远程控制集群节点的供电。这是一种可能的方式来实现power fencing。为此,请使用远程管理卡,如惠普的iLO或戴尔的iDRAC。
- 光纤通道交换机:在集群基础设施的图中,所有节点在同一时间,连接到相同的共享存储。通常使用光纤通 道来达到这个目的。另一种方法是使用iSCSI或FCoE建立单独的以太网。
在图中,只有集群节点左侧的组件是可公开访问的。集群节点右侧的所有内容都是严格私有的,不应该从公共网络访问。
2. 描述一个HA集群的软件配置
集群节点需要多个软件组件通过Red Hat High Availability Add-On提供集群服务。这些组件及其功能 概述如下:
- corosync:这是Pacemaker用于处理集群节点之间通信的框架。
corosync也是Pacemaker的成员和仲裁数据的来源。 - Pacemaker: 该组件负责所有与集群相关的活动,例如监视集群成员、管理服务和资源以及隔离集群成员。pacemaker RPM 包包含三个重要功能:
(1) CIB (Cluster Information Base): CIB以XML格式包含集群和集群资源的配置信息和状态信息。 Pacemaker选举集群中的集群节点作为指定的协调器(DC),并存储与所有其他活动集群节点同步的集群和资源 状态以及集群配置。调度器(pacemaker-schedulerd)使用CIB的内容来计算集群的理想状态以及如何达到 理想状态。
(2) CRMd (Cluster Resource Management Daemon):集群资源管理守护进程协调并发送资源启动、停 止和状态查询操作给运行在每个集群节点上的本地资源管理守护进程LRMd (Local Resource Management Daemon)。LRMd将从CRMd接收到的操作传递给资源代理。
(3) 射击另一个节点的头部-Shoot the Other in the Head(stoneith): stoneith是负责处理 Fencing请求的设施,并将请求的操作转发给CIB中配置的Fencing设备。 - pcs:pcs RPM包中包含两个集群配置工具:
(1) pcs命令提供了一个命令行界面,用于创建、配置和控制Pacemaker/Corosync集群的各个方面。
(2) pcsd服务提供集群配置同步和web前端来创建和配置Pacemaker/Corosync集群。
3. HA集群需求
在使用Red Hat high availability Add-On部署高可用性集群之前,了解集群配置的需求和可支持性非 常重要。Red Hat可以帮助你评估现有集群的性能或构建新集群。该过程需要将集群的相关数据(如集群配置、 网络架构和fencing配置)传输给Red Hat Support。如果需要,支持代表可能会要求提供额外的数据。然 后,Red Hat Support决定它是否支持集群配置。在基于Red Hat high availability Add-On部署高 可用性集群之前,系统管理员应该考虑一些重要的需求和建议。
3.1 节点数量
对于Red Hat Enterprise Linux 8.1及更高版本,Red Hat支持最多32个节点的集群。如果使用RHEL 8.0及之前版本,或弹性存储插件,则支持的节点数量最多为16个节点。只有一个或两个节点的集群是特殊情 况。RHEL 8.2及更高版本支持单节点集群。但是,fencing是不可用的,因此单节点集群不支持需要 fencing的文件系统,例如DLM和GFS2。RHEL 8.1和更早的版本只支持两个或更多节点的集群。Red Hat在 大多数情况下支持双节点集群,但建议在将双节点集群部署到生产环境之前提交集群设计并咨询Red Hat Support。
3.2 单站点、多站点和拉伸集群(Stretch Clusters)
Red Hat完全支持单站点集群。这是一种集群设置,其中所有集群成员都位于相同的物理位置,通过局域网连 接。多站点集群由两个集群组成,一个处于活动状态,另一个用于灾难恢复。多站点集群在设计时确实需要特别 考虑。Red Hat Enterprise Linux 8 High Availability Add-On支持多站点集群。拉伸集群,也称 为geo cluster,是在多个物理位置上拉伸的集群。Red Hat不将这些集群视为具有单独规则的特殊部署类。 因此,适用于RHEL高可用性集群的标准策略、需求和限制将它们绑定在一起。然而,伸缩集群确实具有固有的 复杂性,Red Hat Support强烈建议在部署它们之前提交集群设计.
3.3 Fecning硬件
Fecning是一种确保故障集群节点不会导致损坏的机制。因此,可以安全地在集群的其他地方恢复它的资源。 这可以通过对节点进行电源循环或禁用与存储层的通信来实现。集群中的所有节点都需要隔离,可以通过电源隔 离、存储隔离,或者两者的结合。在部署高可用性基础设施之前,请确保使用受支持的硬件。如果集群使用集成 的Fecning设备(如iLO或iDRAC),那么当接收到关机信号时,充当集群节点的系统必须立即关闭电源 (poweroff),而不是启动完全关机(shutdown)。
3.4 虚拟化和云环境
Red Hat支持在最流行的虚拟环境和云提供商上使用虚拟机作为集群成员。
当作为集群节点运行时,在主机上运行的虚拟机是集群的成员并运行资源。可以使用特殊的fencing代理,以 便这些集群节点可以相互防护,无论是运行在基于RHEL 8 libvirt的系统、Red Hat Virtualization还 是其他虚拟机管理程序主机上。在这种情况下,物理主机是运行在该主机上的所有基于虚拟机的集群节点的单点 故障。如果物理主机崩溃,则会导致在其上运行的所有集群节点虚拟机崩溃。
3.5 网络
在RHEL8中,corosync组件在私有网络中使用单播传输协议kronosnet进行默认的网络通信。对于public网 络,免费ARP用于浮动IP地址。网络交换机必须支持此功能。
在public网络上,需要开放集群业务运行所需的网口。为了保证正常运行,还需要在私网中打开以下端口: (1)pcsd的2224/TCP
(2)corosync的5404-5412/UDP 可选的集群组件需要额外的端口。例如,GFS2文件系统使用21064/TCP端口,仲裁设备使用5403/TCP端口, booth ticket管理器使用9929/TCP和UDP端口。其中一些组件将在其他章节中描述。
booth ticket管理是一种分布式服务,便于支持多站点集群。
3.6 selinux
当在集群节点上使用目标策略时,Red Hat Enterprise Linux High Availability Add-On支持以强制模式使用SELinux。
3.7 为失败做计划
所有硬件最终都会失效。硬件生命周期从几周到几年不等。此外,几乎每一个(复杂的)软件都有bug。有些可能 不引人注意,有些可能会破坏整个数据库。系统管理员的主要任务之一是确认这些故障的发生,并进行相应的计 划。
当出现故障的硬件是一台简单的桌面计算机时,正确的方法最有可能是替换故障的计算机,尽管对于任务关键型
服务器需要更主动的方法。当一台机器发生故障时,运行在该机器上的服务不应该失败。
单点故障(SPOF)是复杂设置的任何部分,当它发生故障时,可能会导致整个环境崩溃。典型的高可用性集群可 能有许多可能的单点故障。以下并不是详尽的清单,但它们确实包含了最常见的情况。
硬件单点故障、电力供应 、本地存储 、网络接口 、网络交换机 、Fencing软件
软件单点故障 、集群通信 、共享存储连接 、软件Fencing配置
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!