OpenKruise
1. OpenKruise介绍
OpenKruise是一个Kubernetes的扩展套件,主要聚焦于云原生应用的自动化,比如部署、发布、运维以及可用性防护。OpenKruise提供的绝大多数能力都是基于CRD扩展来定义的,它们不存在于任何外部依赖,可以运行在任意纯净的Kubernetes集群中。Kubernetes自身提供的一些应用部署管理功能,对于大规模应用与集群的场景这些功能都是远远不够的,OpenKruise弥补了Kubernetes在应用部署、升级、防护、运维等领域的不足。
2.1 核心能力
- 增强版本的Workloads:OpenKruise 包含了一系列增强版本的工作负载,比如 CloneSet、Advanced StatefulSet、Advanced DaemonSet、BroadcastJob 等。它们不仅支持类似于 Kubernetes 原生 Workloads 的基础功能,还提供了如原地升级、可配置的扩缩容/发布策略、并发操作等。其中,原地升级是一种升级应用容器镜像甚至环境变量的全新方式,它只会用新的镜像重建 Pod 中的特定容器,整个 Pod 以及其中的其他容器都不会被影响。因此它带来了更快的发布速度,以及避免了对其他 Scheduler、CNI、CSI 等组件的负面影响。
- 应用的旁路管理:OpenKruise 提供了多种通过旁路管理应用 sidecar 容器、多区域部署的方式,旁路意味着你可以不需要修改应用的 Workloads 来实现它们。比如,SidecarSet 能帮助你在所有匹配的 Pod 创建的时候都注入特定的 sidecar 容器,甚至可以原地升级已经注入的 sidecar 容器镜像、并且对 Pod 中其他容器不造成影响。而 WorkloadSpread 可以约束无状态 Workload 扩容出来 Pod 的区域分布,赋予单一 workload 的多区域和弹性部署的能力。
- 高可用性防护:OpenKruise 可以保护你的 Kubernetes 资源不受级联删除机制的干扰,包括 CRD、Namespace、以及几乎全部的 Workloads 类型资源。相比于 Kubernetes 原生的 PDB 只提供针对 Pod Eviction 的防护,PodUnavailableBudget 能够防护 Pod Deletion、Eviction、Update 等许多种 voluntary disruption 场景。
- 高级的应用运维能力:OpenKruise 也提供了很多高级的运维能力来帮助你更好地管理应用,比如可以通过 ImagePullJob 来在任意范围的节点上预先拉取某些镜像,或者指定某个 Pod 中的一个或多个容器被原地重启。
2.2 架构
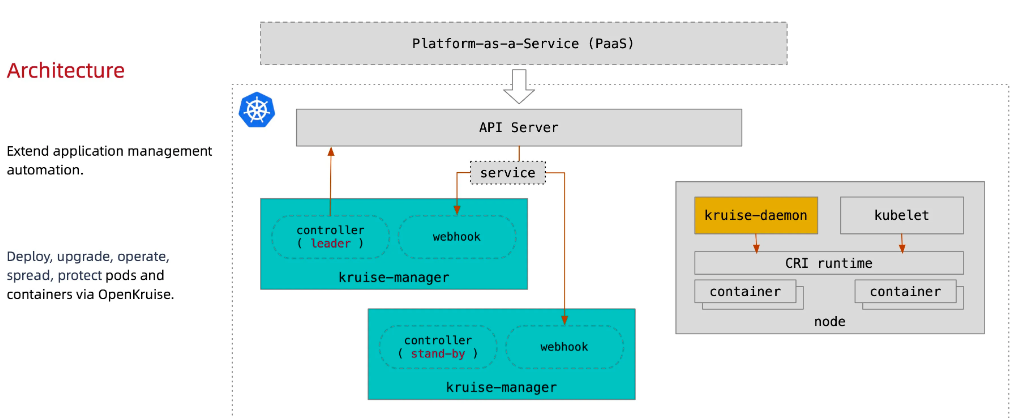
所有 OpenKruise 的功能都是通过 Kubernetes CRD 来提供的。
Kruise-manager 是一个运行控制器和 webhook 的中心组件,它通过 Deployment 部署在 kruise-system 命名空间中。
从逻辑上来看,如 cloneset-controller、sidecarset-controller 这些的控制器都是独立运行的,不过为了减少复杂度,它们都被打包在一个独立的二进制文件、并运行在 kruise-controller-manager-xxx 这个 Pod 中。
除了控制器之外,kruise-controller-manager-xxx 中还包含了针对 Kruise CRD 以及 Pod 资源的 admission webhook。
Kruise-manager 会创建一些 webhook configurations 来配置哪些资源需要感知处理、以及提供一个 Service 来给 kube-apiserver 调用。
从 v0.8.0 版本开始提供了一个新的 Kruise-daemon 组件,它通过 DaemonSet 部署到每个节点上,提供镜像预热、容器重启等功能。
2. 安装
使用 Helm 方式来进行安装,需要注意从 v1.0.0 开始,OpenKruise 要求在 Kubernetes >= 1.16 以上版本的集群中安装和使用。
2.1 添加charts仓库
1 | |
2.2 安装应用
该charts模版中默认定义了命名空间为kruise-system,所以在安装的时候可以不用指定,如果你的环境访问dockerhub官方镜像比较慢,则可以使用下面的命令将镜像替换成阿里云的镜像
1 | |
1 | |
应用部署完成后会在 kruise-system 命名空间下面运行 2 个 kruise-manager 的 Pod,同样它们之间采用 leader-election 的方式选主,同一时间只有一个提供服务,达到高可用的目的,此外还会以 DaemonSet 的形式启动 kruise-daemon 组件:
1 | |
如果不想使用默认的参数进行安装,也可以自定义配置,可配置的 values 值可以参考 charts 文档 https://github.com/openkruise/charts 进行定制。
3. 使用
3.1 CloneSet
CloneSet 控制器是 OpenKruise 提供的对原生 Deployment 的增强控制器,在使用方式上和 Deployment 几乎一致。
3.1.1 流式扩容
CloneSet 在扩容的时候可以通过 ScaleStrategy.MaxUnavailable 来限制扩容的步长,这样可以对服务应用的影响最小,可以设置一个绝对值或百分比,如果不设置该值,则表示不限制。
1 | |
scaleStrategy.maxUnavailable 为 1,结合 minReadySeconds 参数,表示在扩容时,只有当上一个扩容出的 Pod 已经 Ready 超过一分钟后,CloneSet 才会执行创建下一个 Pod。
3.1.2 缩容
当 CloneSet 被缩容时,可以指定一些 Pod 来删除,这对于 StatefulSet 或者 Deployment 来说是无法实现的, StatefulSet 是根据序号来删除 Pod,而 Deployment/ReplicaSet 目前只能根据控制器里定义的排序来删除。而 CloneSet 允许用户在缩小 replicas 数量的同时,指定想要删除的 Pod 名字。
1 | |
更新上面的资源对象后,会将应用缩到 4 个 Pod,如果在 podsToDelete 列表中指定了 Pod 名字,则控制器会优先删除这些 Pod,对于已经被删除的 Pod,控制器会自动从 podsToDelete 列表中清理掉。更新上面的资源对象后 cs-demo-n72fr 这个 Pod 会被移除,其余会保留下来。
只把 Pod 名字加到 podsToDelete,但没有修改 replicas 数量,那么控制器会先把指定的 Pod 删掉,然后再扩一个新的 Pod,另一种直接删除 Pod 的方式是在要删除的 Pod 上打 apps.kruise.io/specified-delete: true 标签。
相比于手动直接删除 Pod,使用 podsToDelete 或 apps.kruise.io/specified-delete: true 方式会有 CloneSet 的 maxUnavailable/maxSurge 来保护删除, 并且会触发 PreparingDelete 生命周期的钩子。
3.1.3 pvc模版
一个比较奇特的特性,CloneSet 允许用户配置 PVC 模板 volumeClaimTemplates,用来给每个 Pod 生成独享的 PVC,这是 Deployment 所不支持的,因为往往有状态的应用才需要单独设置 PVC,在使用 CloneSet 的 PVC 模板的时候需要注意下面的这些事项:
- 每个被自动创建的 PVC 会有一个
ownerReference指向 CloneSet,因此 CloneSet 被删除时,它创建的所有 Pod 和 PVC 都会被删除。 - 每个被 CloneSet 创建的 Pod 和 PVC,都会带一个
apps.kruise.io/cloneset-instance-id: xxx的 label。关联的 Pod 和 PVC 会有相同的instance-id,且它们的名字后缀都是这个instance-id。 - 如果一个 Pod 被 CloneSet controller 缩容删除时,这个 Pod 关联的 PVC 都会被一起删掉。
- 如果一个 Pod 被外部直接调用删除或驱逐时,这个 Pod 关联的 PVC 还都存在;并且 CloneSet controller 发现数量不足重新扩容时,新扩出来的 Pod 会复用原 Pod 的
instance-id并关联原来的 PVC。 - 当 Pod 被重建升级时,关联的 PVC 会跟随 Pod 一起被删除、新建。
- 当 Pod 被原地升级时,关联的 PVC 会持续使用。
pvc模版例子:
1 | |
应用上面的资源对象后会自动创建 3 个 Pod 和 3 个 PVC,每个 Pod 都会挂载一个 PVC
1 | |
3.1.4 升级
Cloneset 提供了三种升级方式:
ReCreate: 删除旧 Pod 和它的 PVC,然后用新版本重新创建出来,这是默认的方式InPlaceIfPossible: 会优先尝试原地升级 Pod,如果不行再采用重建升级InPlaceOnly: 只允许采用原地升级,因此,用户只能修改上一条中的限制字段,如果尝试修改其他字段会被拒绝
原地升级:这是OpenKruise提供的核心功能之一,当要升级一个Pod中镜像的时候,下图展示了重建升级和原地升级的区别。
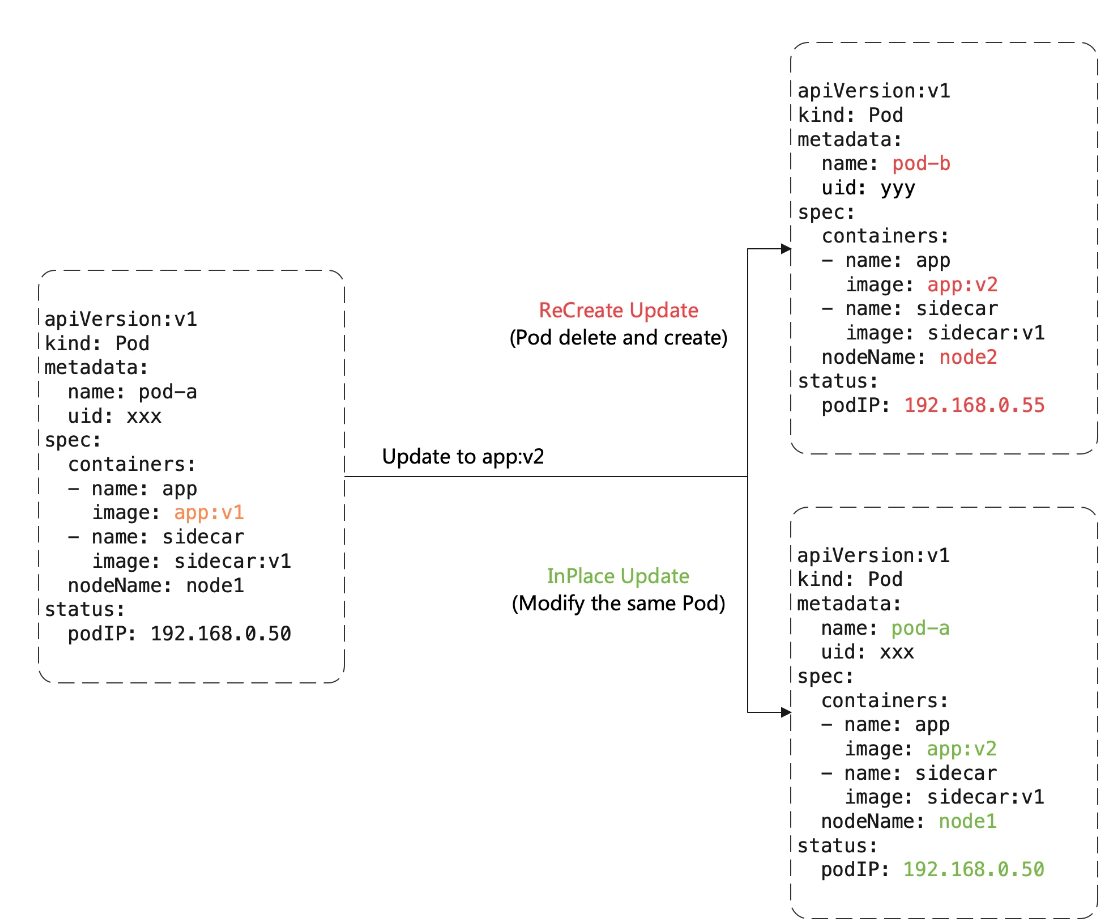
使用原地升级的方式来升级我们的工作负载,对在线应用的影响是最小的。
CloneSet 升级类型支持 InPlaceIfPossible,这意味着 OpenKruise 会尽量对 Pod 采取原地升级,如果不能则退化到重建升级,以下的改动会被允许执行原地升级:
- 更新 workload 中的
spec.template.metadata.*,比如 labels/annotations,Kruise 只会将 metadata 中的改动更新到存量 Pod 上。 - 更新 workload 中的
spec.template.spec.containers[x].image,Kruise 会原地升级 Pod 中这些容器的镜像,而不会重建整个 Pod。 - 从 Kruise v1.0 版本开始,更新
spec.template.metadata.labels/annotations并且 container 中有配置 env from 这些改动的labels/anntations,Kruise 会原地升级这些容器来生效新的 env 值。
以下的改动不允许执行原地升级:
spec.template.spec.containers[x].env或spec.template.spec.containers[x].resources,都是会回退为重建升级
3.1.4.1 重建升级
需要删除旧的Pod、创建新的Pod:
- Pod的名字和uid发生变化,因为它们是完全不同的两个Pod对象(比如Deployment升级)
- Pod的名字可能不变、但是uid发生变化,因为它们是不同的Pod对象,只是复用了同一个名字(比如StatefulSet升级)
- Pod所在Node名字可能发生变化,因为新Pod很可能不会调度到之前所在的Node节点
- Pod IP发生变化,因为新的Pod很大可能性是不会分配到之前的IP地址
3.1.4.2 原地升级
不需要删除旧的Pod,只需要修改里面的字段:
- 可以避免如调度、分配IP、挂载volume等额外的操作和代价
- 更快的镜像拉取,因为会服用已有旧镜像的大部分layer层,只需要拉取镜像变化的一些layer(构成镜像的基本单元,每个layer代表镜像构建时候的操作)
- 当一个容器在原地升级的时候,Pod中的其他容器不会受到影响,仍然会维持运行
工作流程图:
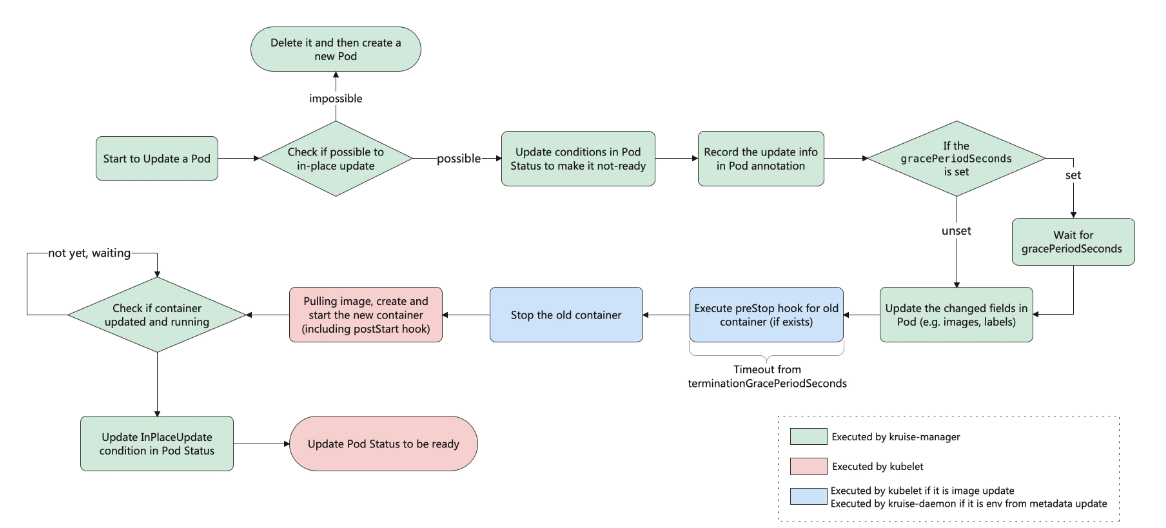
在安装或升级 Kruise 的时候启用了 PreDownloadImageForInPlaceUpdate 这个 feature-gate,CloneSet 控制器会自动在所有旧版本 pod 所在节点上预热你正在灰度发布的新版本镜像,这对于应用发布加速很有帮助。
默认情况下 CloneSet 每个新镜像预热时的并发度都是 1,也就是一个个节点拉镜像,如果需要调整,可以在 CloneSet 通过 apps.kruise.io/image-predownload-parallelism 这个 annotation 来设置并发度。
从 Kruise v1.1.0 开始,还可以使用 apps.kruise.io/image-predownload-min-updated-ready-pods 来控制在少量新版本 Pod 已经升级成功之后再执行镜像预热。它的值可能是绝对值数字或是百分比。
1 | |
⚠️注意,为了避免大部分不必要的镜像拉取,目前只针对 replicas > 3 的 CloneSet 做自动预热。
3.1.5 分批灰度
在 updateStrategy 属性中可以配置 partition 参数,该参数可以用来保留旧版本 Pod 的数量或百分比,默认为 0:
- 如果是数字,控制器会将
(replicas - partition)数量的 Pod 更新到最新版本 - 如果是百分比,控制器会将
(replicas * (100% - partition))数量的 Pod 更新到最新版本
CloneSet 还支持一些更高级的用法,比如可以定义优先级策略来控制 Pod 发布的优先级规则,还可以定义策略来将一类 Pod 打散到整个发布过程中,也可以暂停 Pod 发布等操作。
3.1.6 生命周期钩子
每个 CloneSet 管理的 Pod 会有明确所处的状态,在 Pod label 中的 lifecycle.apps.kruise.io/state 标记:
Normal:正常状态PreparingUpdate:准备原地升级Updating:原地升级中Updated:原地升级完成PreparingDelete:准备删除
生命周期是上述状态流转中的卡点,来实现原地升级后、删除前的自定义操作(比如开关流量、告警等)。
CloneSet的lifecycle下面主要支持preDelete和inPlaceUpdate两个属性
1 | |
升级/删除Pod前将其置为NotReady
1 | |
如果设置
preDelete.markPodNotReady=true:Kruise将会在Pod进入
PreparingDelete状态时,将KruisePodReady这个Pod Condition设置为False,Pod将变为NotReady如果设置
inPlaceUpdate.markPodNotReady=true:Kruise 将会在 Pod 进入
PreparingUpdate状态时,将 KruisePodReady 这个 Pod Condition 设置为 False, Pod 将变为 NotReady。Kruise 将会尝试将 KruisePodReady 这个 Pod Condition 设置回 True。
可以利用这个特性,在容器真正被停止之前将Pod上流量先行进行排除,防止流量的损失。
流转示意图:
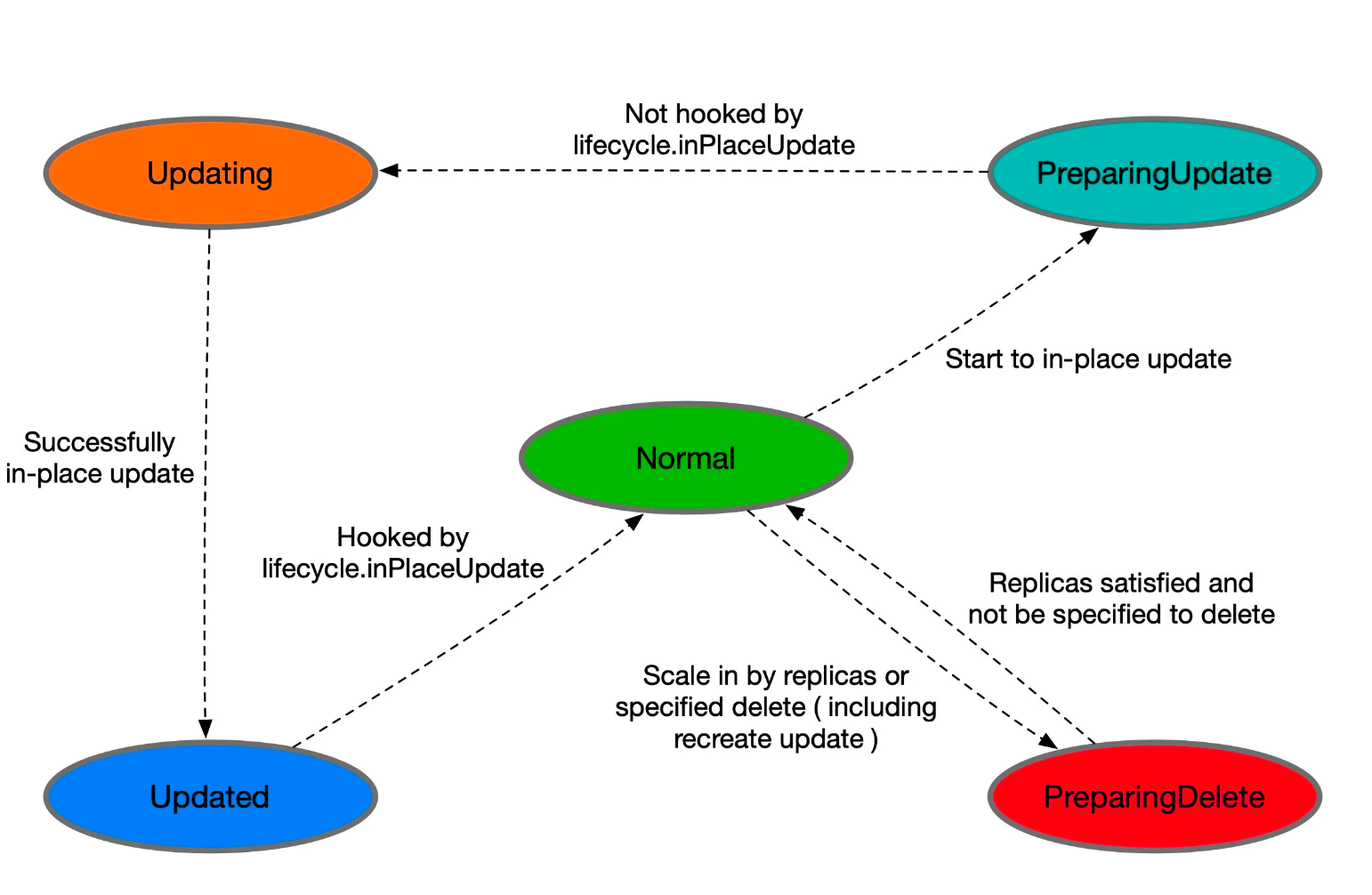
- 当CloneSet删除一个Pod(包括正常缩容和重建升级)时:
- 如果没有定义
lifcycle hook或者pod不符合preDelete条件,则直接删除 - 否则,先只将Pod的状态改变为
PerparingDelete。等用户controller完成任务去掉label/finalizer、Pod 不符合 preDelete 条件后,kruise 才执行 Pod 删除 - 需要注意的是
PreparingDelete状态的 Pod 处于删除阶段,不会被升级 - 当 CloneSet 原地升级一个 Pod 时:
- 升级之前,如果定义了 lifecycle hook 且 Pod 符合
inPlaceUpdate条件,则将 Pod 状态改为PreparingUpdate - 等用户 controller 完成任务去掉 label/finalizer、Pod 不符合
inPlaceUpdate条件后,kruise 将 Pod 状态改为Updating并开始升级 - 升级完成后,如果定义了 lifecycle hook 且 Pod 不符合
inPlaceUpdate条件,将 Pod 状态改为 Updated - 等用户 controller 完成任务加上 label/finalizer、Pod 符合
inPlaceUpdate条件后,kruise 将 Pod 状态改为 Normal 并判断为升级成功
- 升级之前,如果定义了 lifecycle hook 且 Pod 符合
关于从 PreparingDelete 回到 Normal 状态,从设计上是支持的(通过撤销指定删除),但我们一般不建议这种用法。由于 PreparingDelete 状态的 Pod 不会被升级,当回到 Normal 状态后可能立即再进入发布阶段,对于用户处理 hook 是一个难题。
3.1.6.1 自定义finalizersHandler标签
按照上面的例子,可以自定义:
example.io/unready-blocker finalizer作为 hookexample.io/initialingannotation 作为初始化标记
在 CloneSet template 模板里带上这个字段:
1 | |
逻辑如下:
- 对于 Normal 状态的 Pod,如果 annotation 中有
example.io/initialing: true并且 Pod status 中的 ready condition 为 True,则接入流量、去除这个 annotation - 对于
PreparingDelete和PreparingUpdate状态的 Pod,切走流量,并去除example.io/unready-blockerfinalizer - 对于 Updated 状态的 Pod,接入流量,并打上
example.io/unready-blocker finalizer
使用场景:
因为各种各样的历史原因和客观因素,有些用户可能无法将自己公司的整套体系架构k8s化,比如有些用户暂时无法使用k8s本身提供好的service服务发现机制,而是使用了独立于k8s之外的另一套服务注册和发现体系。
在这种架构下,如果用户对服务进行k8s化改造,可能会遇到诸多的问题。例如:
每当k8s成功创建出一个pod,都需要自行将该pod注册到服务发现中心,以便能够对内对外提供服务;相应的,想要下线一个pod,也通常需要先将其在服务发现中心进行删除,才能将pod优雅的进行下线,否则就可能导致流量的损失。但是在原生的k8s体系中,pod的生命周期由workload管理(例如Deployment),当这些workload的Replicas字段发生后,相应的Controller会立即添加或者删除掉pod,用户很难定制化地去管理pod的生命周期。
面对这类问题,一般来说有两种解决思路:
- 约束k8s的弹性能力,例如规定只能由特定的链路对workload进行扩缩容,以保证在删除pod前先把pod ip 在服务注册中心摘除,但是这样会制约k8s本身的弹性能力,并且也增加了链路管控的难度和风险。
- 从根本上改造现有的服务发现体系,显然是一个更加漫长和高风险的事情。
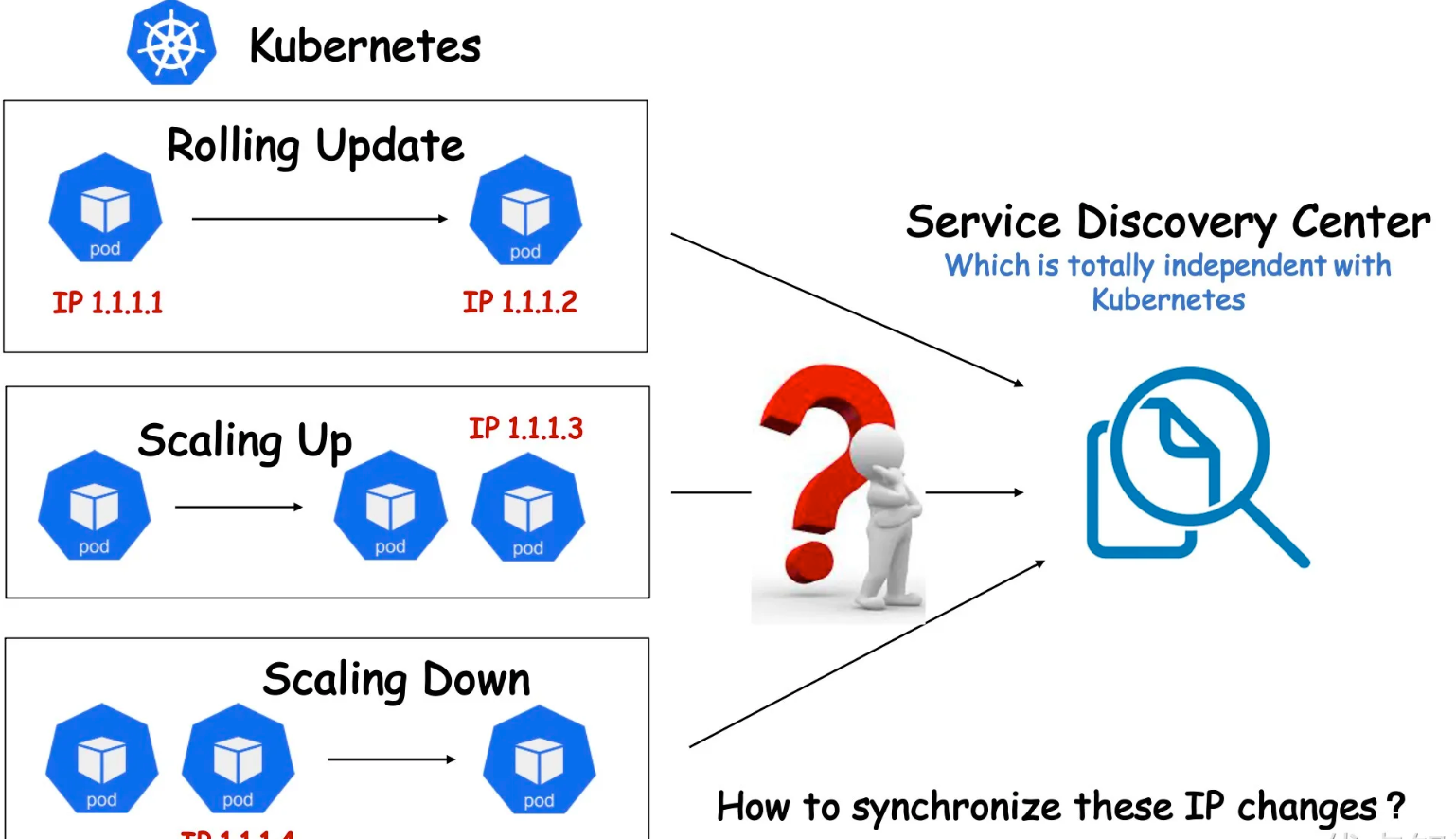
有没有一种能够充分利用k8s的弹性能力,又可以避免对现有的服务发现体系进行改造,快速弥补两个系统之前的间隙呢?
CloneSet就提供了这样一组可以高度可定制化的扩展能力来专门应对此类场景,让用户能够对Pod生命周期做更精细化、定制化的管理。
假设一个场景:
- 用户不使用k8s service作为服务发现机制,服务发现体系完全独立于k8s
- 使用CloneSet作为k8s工作负载
对于这个需求做贺礼的假设:
- 当k8s pod被创建的时候
- 在创建成功,并且pod ready之后,将pod ip注册到服务发现中心
- 当k8s pod原地升级的时候
- 在升级之前,需要将pod ip 从服务发现中心删除(或者主动FailOver)
- 在升级完成,并且Pod Ready之后,将Pod ip再次注册到服务发现中心
- 当pod被删除的时候
- 在删除之前,需要先将pod从服务发现中心删除
基于以上的假设,可以利用CloneSet LifeCycle来编写一个简单的Operator实现用户定义的pod生命周期管理机制。
CloneSet LifeCycle 将 Pod 的生命周期定义为了 5 种状态,5 种状态之间的转换逻辑由一个状态机所控制。我们可以只选择自己所关心的一种或多种,编写一个独立的 Operator 来实现这些状态的转换,控制 Pod 的生命周期,并在所关心的时间节点插入自己的定制化逻辑。
1 | |
控制器核心代码:
1 | |
上述代码中四个分支分别从上到下对应 Pod 的创建后、升级前、升级后、删除前等四个重要声明周期节点,我们可以根据自己的实际需求来完善相应的 Hook,我们这里上述几个 Hook 的行为具体为:
postRegistry(pod *v1.Pod): 发送请求通知服务发现中心注册该 Pod 服务;postFailOver(pod *v1.Pod): 发送请求通知服务发现中心 Fail Over 该 Pod 服务;postUnregiste(pod *v1.Pod): 发送请求通知服务发现中心将该 Pod 服务注销。
这就是 CloneSet Lifecycle 的强大之处,完全可以根据需求在 Pod 生命周期管理中插入定制化逻辑。
3.2 Advanced StatefulSet
该控制器在原生的StatefulSet基础上增强了发布的能力,比如maxUnavailable 并行发布、原地升级等,该对象的名称也是 StatefulSet,但是 apiVersion 是 apps.kruise.io/v1beta1,这个 CRD 的所有默认字段、默认行为与原生 StatefulSet 完全一致,除此之外还提供了一些可选字段来扩展增强的策略。因此,用户从原生 StatefulSet 迁移到 Advanced StatefulSet,只需要把 apiVersion 修改后提交即可:
1 | |
3.2.1 最大不可用
Advanced StatefulSet 在滚动更新策略中新增了 maxUnavailable 来支持并行 Pod 发布,它会保证发布过程中最多有多少个 Pod 处于不可用状态。注意,maxUnavailable 只能配合 podManagementPolicy 为 Parallel 来使用。
这个策略的效果和 Deployment 中的类似,但是可能会导致发布过程中的 order 顺序不能严格保证,如果不配置 maxUnavailable,它的默认值为 1,也就是和原生 StatefulSet 一样只能串行发布 Pod,即使把 podManagementPolicy 配置为 Parallel 也是这样。
创建一个实例
这个应用下面有5个pod,并且应用能容忍3个副本不可用,当升级StatefulSet里面的pod升级版本的时候,可以通过下面的步骤来做:
- 设置 maxUnavailable=3
- (可选) 如果需要灰度升级,设置
partition=4,Partition 默认的意思是 order 大于等于这个数值的 Pod 才会更新,在这里就只会更新 P4,即使我们设置了maxUnavailable=3。 - 在 P4 升级完成后,把 partition 调整为 0,此时,控制器会同时升级 P1、P2、P3 三个 Pod。注意,如果是原生 StatefulSet,只能串行升级 P3、P2、P1。
- 一旦这三个 Pod 中有一个升级完成了,控制器会立即开始升级 P0。
1 | |
3.2.2 原地升级
增加了 podUpdatePolicy 来允许用户指定重建升级还是原地升级。此外还在原地升级中提供了 graceful period 选项,作为优雅原地升级的策略。用户如果配置了 gracePeriodSeconds 这个字段,控制器在原地升级的过程中会先把 Pod status 改为 not-ready,然后等一段时间(gracePeriodSeconds),最后再去修改 Pod spec 中的镜像版本。这样,就为 endpoints-controller 这些控制器留出了充足的时间来将 Pod 从 endpoints 端点列表中去除。
如果使用 InPlaceIfPossible 或 InPlaceOnly 策略,必须要增加一个 InPlaceUpdateReady readinessGate,用来在原地升级的时候控制器将 Pod 设置为 NotReady,比如设置上面的应用为原地升级的方式:
Standard: 对于每个节点,控制器会先删除旧的 daemon Pod,再创建一个新 Pod,和原生 DaemonSet 行为一致,同样也可以通过maxUnavailable或maxSurge来控制重建新旧 Pod 的顺序。Surging: 对于每个 node,控制器会先创建一个新 Pod,等它 ready 之后再删除老 Pod。InPlaceIfPossible: 控制器会尽量采用原地升级的方式,如果不行则重建升级,注意,在这个类型下,只能使用maxUnavailable而不能用maxSurge。
创建一个资源对象:
当修改image字段后应用下面的yaml文件,只会修改node1上节点的pod,原地进行升级
1 | |
和前面两个控制器一样,Advanced DaemonSet 也支持分批灰度升级,使用 Partition 进行配置,Partition 的语义是保留旧版本 Pod 的数量,默认为 0,如果在发布过程中设置了 partition,则控制器只会将 (status.DesiredNumberScheduled - partition) 数量的 Pod 更新到最新版本。
1 | |
同样 Advanced DaemonSet 也是支持原地升级的,只需要设置 rollingUpdateType 为支持原地升级的类型即可,比如这里我们将上面的应用升级方式设置为 InPlaceIfPossible 即可:
1 | |
3.3 BroadcastJob
这个控制器将Pod分发到集群中的每个节点上,类似于DaemonSet,但是BroadcasetJob管理的pod并不是长期运行的daemon服务,而是类似于job的任务类型pod,在每个即诶单的pod执行完成退出后,BroadcasetJob和这些pod并不会占用集群资源。这个控制器非常有利于做升级基础软件、巡检等过一段时间需要在整个集群中跑一次的工作。
例子:
1 | |
此外在 BroadcastJob 对象中还可以配置任务完成后的一些策略,比如配置 completionPolicy.ttlSecondsAfterFinished: 30,表示这个 job 会在执行结束后 30s 被删除。
1 | |
配置 completionPolicy.activeDeadlineSeconds 为 10,表示这个 job 会在运行超过 10s 之后被标记为失败,并把下面还在运行的 Pod 删除掉。
1 | |
completionPolicy 类型除了 Always 之外还可以设置为 Never,表示这个 job 会持续运行即使当前所有节点上的 Pod 都执行完成了。
1 | |
比如说,用户希望对集群中每个节点都下发一个配置,包括后续新增的节点,那么就可以创建一个 Never 策略的 BroadcastJob。
此外也可以配置 Parallelism 表示最多能允许多少个 Pod 同时在执行任务,默认不做限制。比如,一个集群里有 10 个 node、并设置了 Parallelism 为 3,那么 BroadcastJob 会保证同时只会有 3 个 node 上的 Pod 在执行。每当一个 Pod 执行完成,BroadcastJob 才会创建一个新 Pod 执行。
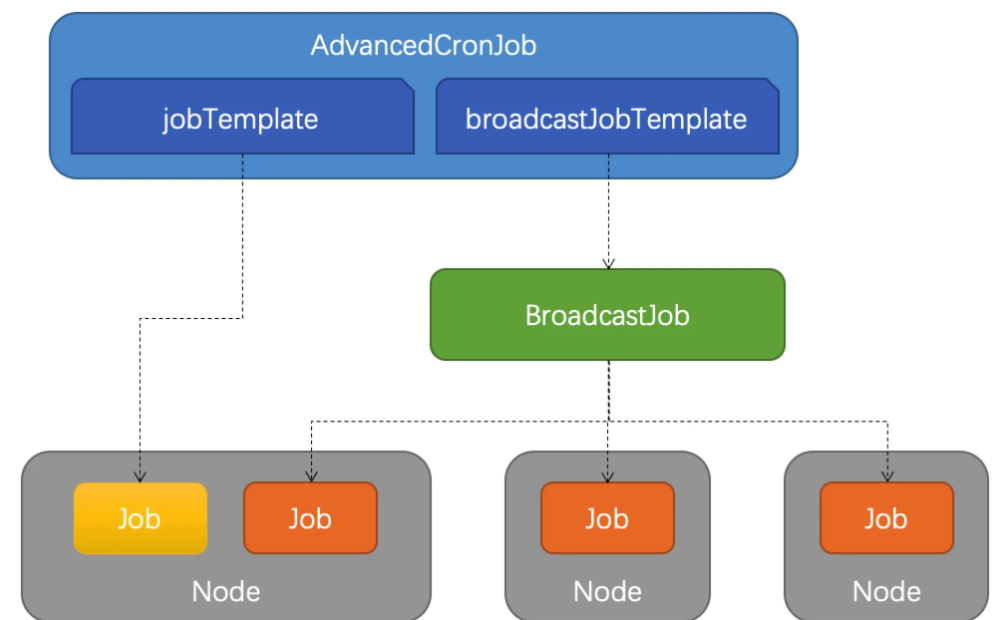
3.4 AdvancedCornJob
是对于原生CronJob的扩展版本,根据用户设置的schedule规则,周期性创建job执行任务,template支持多种不同的job资源。
1 | |
jobTemplate:与原生 CronJob 一样创建 Job 执行任务broadcastJobTemplate:周期性创建 BroadcastJob 执行任务
1 | |
默认情况下,所有 AdvancedCronJob schedule 调度时,都是基于 kruise-controller-manager 容器本地的时区所计算的。
在 v1.3.0 版本中引入了 spec.timeZone 字段,可以将它设置为任意合法时区的名字。例如,设置 spec.timeZone: "Asia/Shanghai" 则 Kruise 会根据国内的时区计算 schedule 任务触发时间。
3.5 SIdecarSet
SidecarSet支持通过admission webhook来自动为集群中创建的符合条件的pod注入sidecar容器,除了在pod创建时候注入外,sidecarSet还提供了为Pod原地升级其中已经注入sidecar容器镜像的能力。sidecarSet将sidecar容器的定义和生命周期与业务容器结偶,它主要用于管理无状态的sidecar容器,比如监控、日志等等
定义一个sidecarSet资源对象:
1 | |
在定义 SidecarSet 对象的时候里面有一个非常重要的属性就是 label selector,会去匹配具有 app=nginx 的 Pod,然后向其中注入下面定义的 sidecar1 这个容器,比如定义如下所示的一个 Pod,该 Pod 中包含 app=nginx 的标签,这样可以和上面的 SidecarSet 对象匹配:
1 | |
3.5.1 基本特性
需要注意的是sidecar的注入只会发生在pod的创建阶段,并且只有pod spec会被更新,不会影响pod所属的工作负载template模版。spec.containers除了默认的k8s container字段,还扩展了如下的一些字段,来方便注入:
1 | |
podInjectPolicy定义了容器 注入到pod.spec.containers中的位置BeforeAppContainer:表示注入到 pod 原 containers 的前面(默认)AfterAppContainer: 表示注入到 pod 原 containers 的后面- 数据卷共享
- 共享指定卷:通过
spec.volumes来定义 sidecar 自身需要的 volume - 共享所有卷:通过
spec.containers[i].shareVolumePolicy.type = enabled | disabled来控制是否挂载 pod 应用容器的卷,常用于日志收集等 sidecar,配置为enabled后会把应用容器中所有挂载点注入 sidecar 同一路经下(sidecar 中本身就有声明的数据卷和挂载点除外) - 环境变量共享:可以通过
spec.containers[i].transferEnv来从别的容器获取环境变量,会把名为sourceContainerName容器中名为envName的环境变量拷贝到本容器
SidecarSet 不仅支持 sidecar 容器的原地升级,而且提供了非常丰富的升级、灰度策略。同样在 SidecarSet 对象中 updateStrategy 属性下面也可以配置 partition 来定义保留旧版本 Pod 的数量或百分比,默认为 0;同样还可以配置的有 maxUnavailable 属性,表示在发布过程中的最大不可用数量。
- 当
{matched pod}=100,partition=40,maxUnavailable=10,控制器会发布 100-40=60 个 Pod 到新版本,但是同一时间只会发布 10 个 Pod,每发布好一个 Pod 才会再找一个发布,直到 60 个发布完成。 - 当
{matched pod}=100,partition=80,maxUnavailable=30,控制器会发布 20 个 Pod 到新版本,因为满足 maxUnavailable 数量,所以这 20 个 Pod 会同时发布。
同样也可以设置 paused: true 来暂停发布,此时对于新创建的、扩容的 pod 依旧会实现注入能力,已经更新的 pod 会保持更新后的版本不动,还没有更新的 pod 会暂停更新。
1 | |
3.5.2 金丝雀发布
对于有金丝雀发布需求的业务,可以通过selector来实现,对于需要率先金丝雀灰度的pod打上固定的[canary.release] = true的标签,再通过selector.matchLabels来选中这个pod就好。
例如现在有一个3副本的pod,也具有app=nginx的标签
1 | |
创建后现在就具有4个app=nginx标签的pod了,由于都匹配上面创建的SidecarSet对象,所以都会被注入一个sidecar1的容器,镜像为busybox
1 | |
现在如果想为test-pod这个应用来执行灰度策略,将sidecar容器镜像更新成busybox:1.35.0,则可以在updateStrategy下面添加selector.matchLabels 属性 canary.release: "true",重新修改配置文件,然后进行应用。
1 | |
需要给test-pod也添加canary.release=true这个标签
1 | |
查看日志的详情可以看到test-pod的sidecar镜像更新了,其他pod没有变化,这样就实现了sidecar的灰度功能。
3.5.3 热升级
sidecarset原地升级会先停止旧版本的容器,然后创建新版本的容器,这种方式适合不影响pod服务可用性的sidecar容器,比如日志收集的agent。
但是对于很多代理或者运行时的sidecar容器,例如istio Envoy,这种升级的方法就有问题,Envoy作为pod 中的一个代理容器,代理了所有的流量,如果直接重启,pod服务的可用性会受到影响,如果单独升级envory sidecar,就需要复杂的优雅的终止和协调机制,所以为这种sidecar容器的升级提供了一种新的解决方案。
1 | |
upgradeType:HotUpgrade代表该 sidecar 容器的类型是热升级方案hotUpgradeEmptyImage: 当热升级 sidecar 容器时,业务必须要提供一个 empty 容器用于热升级过程中的容器切换,empty 容器同 sidecar 容器具有相同的配置(除了镜像地址),例如:command、lifecycle、probe等,但是它不做任何工作。lifecycle.postStart: 在postStart这个 hook 中完成热升级过程中的状态迁移,该脚本需要由业务根据自身的特点自行实现,例如:nginx 热升级需要完成 Listen FD 共享以及流量排水(reload)操作。
整体来说热升级特性总共包含以下两个过程:
- Pod 创建时,注入热升级容器
- 原地升级时,完成热升级流程
注入热升级容器
Pod 创建时,SidecarSet Webhook 将会注入两个容器:
{sidecarContainer.name}-1: 如下图所示envoy-1,这个容器代表正在实际工作的 sidecar 容器,例如:envoy:1.16.0{sidecarContainer.name}-2: 如下图所示envoy-2,这个容器是业务配置的hotUpgradeEmptyImage容器,例如:empty:1.0,用于后面的热升级机制
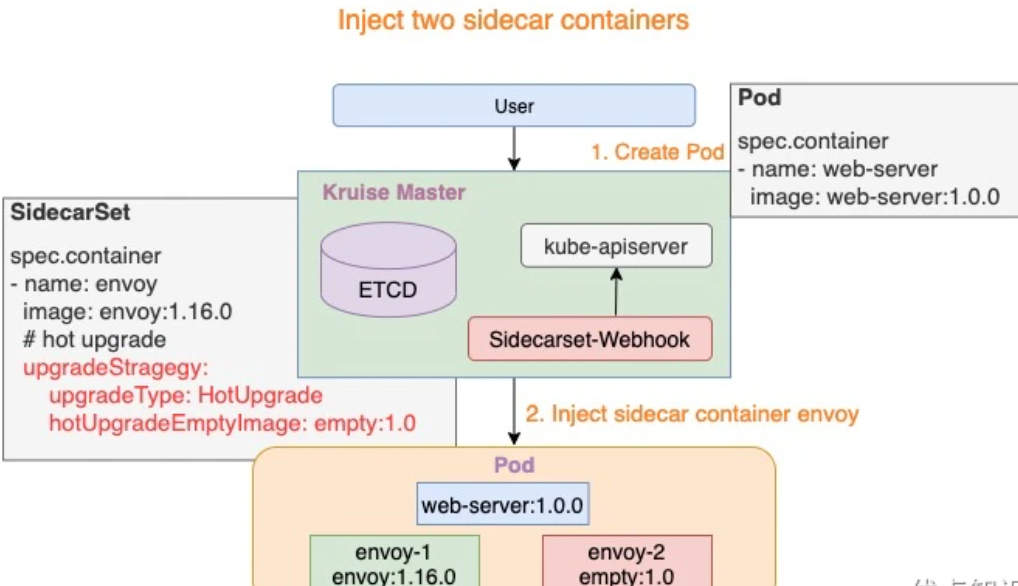
热升级流程
热升级流程主要分为三个步骤:
Upgrade: 将 empty 容器升级为当前最新的 sidecar 容器,例如:envoy-2.Image = envoy:1.17.0Migration:lifecycle.postStart完成热升级流程中的状态迁移,当迁移完成后退出Reset: 状态迁移完成后,热升级流程将设置 envoy-1 容器为 empty 镜像,例如:envoy-1.Image = empty:1.0
上述三个步骤完成了热升级中的全部流程,当对 Pod 执行多次热升级时,将重复性的执行上述三个步骤。
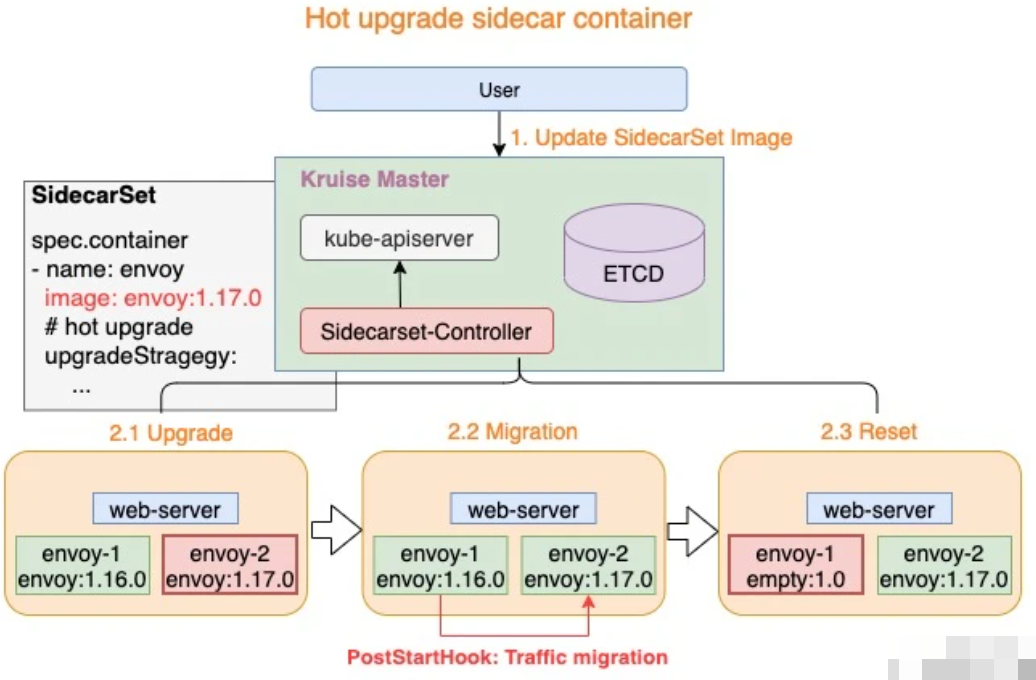
在这里举例官方的案例,首先创建上面的hotupgrade-sidecarset这个sidecarSet,然后创建如图所示的CloneSet对象
1 | |
现在去升级sidecar容器,将容器的镜像改成openkruise/hotupgrade-sample:sidecarv2
1 | |
然后去观察pod的状态,可以看到sidecar-2的镜像又正常进行更新了
1 | |
1 | |
查看busybox的日志,发现请求并没有中断的地方
1 | |
3.6 Container Restart
ContainerRecreateRequest控制器可以帮助用户重启/重建存量pod中的一个或者多个容器。和Kruise提供的原地升级类似,当一个容器重建的时候,Pod中的其他容器还保持正常运行,重建完成后,Pod中除了盖容器的restartCount增加意外不会有什么其他的变化。
不过需要注意之前临时写到旧容器rootfs中的文件会丢失,但是volume mount挂载卷中的数据都还存在。这个功能依赖于kruise-daemon组件来停止pod容器。
为要重建容器的pod提交一个ContainerRecreateRequest自定义资源(缩写CRR)
1 | |
一般来说,列表中的容器会一个个的被停止,但是可能同时在被重建和启动,除非orderedRecreate被设置为true。unreadyGracePeriodSeconds功能依赖于KruisePodReadinessGate这个feature-gate,后者会在每个pod创建的时候注入一个readinessGate,否则,默认只会给Kruise工作负载创建的pod注入readinessGate,也就是说只有这些pod才能在CRR重建的时候使用unreadyGracePeriodSeconds。
当用户创建了一个CRR,Kruise webhook会把当时容器的containerID/restartCount记录到spec.containers[x].statusContext之中。在kruise-daemon执行的过程中,如果它发现实际容器当前的containerID与statusContext不一致或者restartCount已经变大,则认为容器已经被重建成功了(比如可能发生了一次原地升级)。
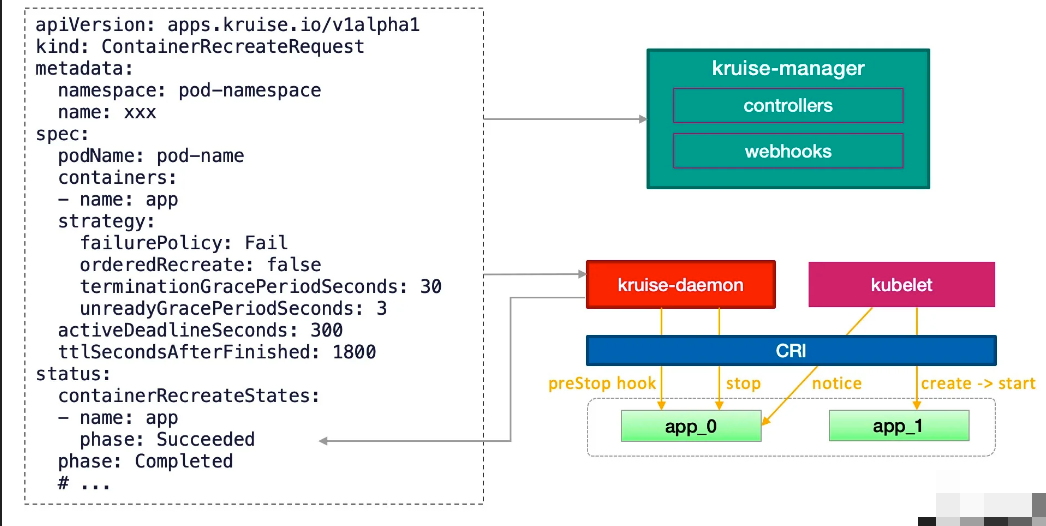
一般情况下,kruise-daemon会执行preStop hook后把容器停掉,然后kubelet感知到容器的退出,则会新建一个容器并启动。最后kruise-daemon看到新容器已经启动成功超过minStartedSeconds时间后,会上报这个容器的phase状态为Succeeded。
如果容器重建和原地升级操作同时触发了:
- 如果 kubelet 根据原地升级要求已经停止或重建了容器,kruise-daemon 会判断容器重建已经完成。
- 如果 kruise-daemon 先停了容器,Kubelet 会继续执行原地升级,即创建一个新版本容器并启动。
- 如果针对一个 Pod 提交了多个
ContainerRecreateRequest资源,会按时间先后一个个执行。
3.7 ImagePullJob
NodeImage和ImagePullJob是从Kruise v0.8.0 版本开始提供的 CRD。Kruise会自动为每个节点创建一个NodeImage,它包含了哪些镜像需要在这个Node上做预热,比如这里三个节点,则会自动创建3个NOdeImage对象:
1 | |
希望在这个节点上去拉一个ubuntu:latest镜像,修改spec:
1 | |
更新后可以从status中看到拉取进度以及结果,并且拉取完成后600s后任务会被清除。
对node节点设置标签
1 | |
在这里查看到镜像拉取失败了,原因是没有配置kruise-daemon的代理,配置代理后再次查看镜像拉取的状态。
1 | |
重新触发镜像拉取操作
1 | |
查看镜像拉取日志,显示镜像拉取成功
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!